






 本文介绍如何使用lxml、Requests库进行爬虫,结合MongoDB存储爬取的一加社区数据,同时提及多线程处理的可能性。
本文介绍如何使用lxml、Requests库进行爬虫,结合MongoDB存储爬取的一加社区数据,同时提及多线程处理的可能性。
新手入门爬虫lxml+Requests+MongoDB
测试爬取一加社区
import requests
from lxml import etree
import pymongo
import proxyIP
import time
def get_UrlInfos(url,proxyIp):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36'
}
response = requests.get(url,proxies = proxyIp,headers = header).text
html = etree.HTML(response)
items = html.xpath('//tbody')
for item in items:
info = {
'type':item.xpath('tr/th/div[2]/span/em/a')[0].text.strip() if len(item.xpath('tr/th/div[2]/span/em/a'))>0 else '',
'title':item.xpath('tr/th/div[2]/a/text()')[0],
'author':item.xpath('tr/th/div[2]/div/em[2]/a/text()')[0].strip(),
'time': item.xpath('tr/th/div[2]/div/em[3]/span/text()')[0].strip()
if len(item.xpath('tr/th/div[2]/div/em[3]/span/text()'))>0 else item.xpath('tr/th/div[2]/div/em[3]/span/span/@title')[0],
'view' :int(item.xpath('tr/th/div[2]/div/em[1]/text()')[0].split(':')[1]),
'reply':int(item.xpath('tr/th/div[2]/div/em[1]/a/text()')[0].strip())
}
yijia.insert_one(info)
if __name__ == '__main__':
start = time.time()
mongoclient = pymongo.MongoClient('127.0.0.1',27017)
mydb = mongoclient['mydb']
yijia = mydb['yijia']
proxyIp = proxyIP.getIp()
urls = ['http://www.oneplusbbs.com/forum-116-{}.html'.format(i) for i in range(2,1000)]
for url in urls:
get_UrlInfos(url,proxyIp)
end = time.time()
print("单线程完成耗时:%d"%(end-start))
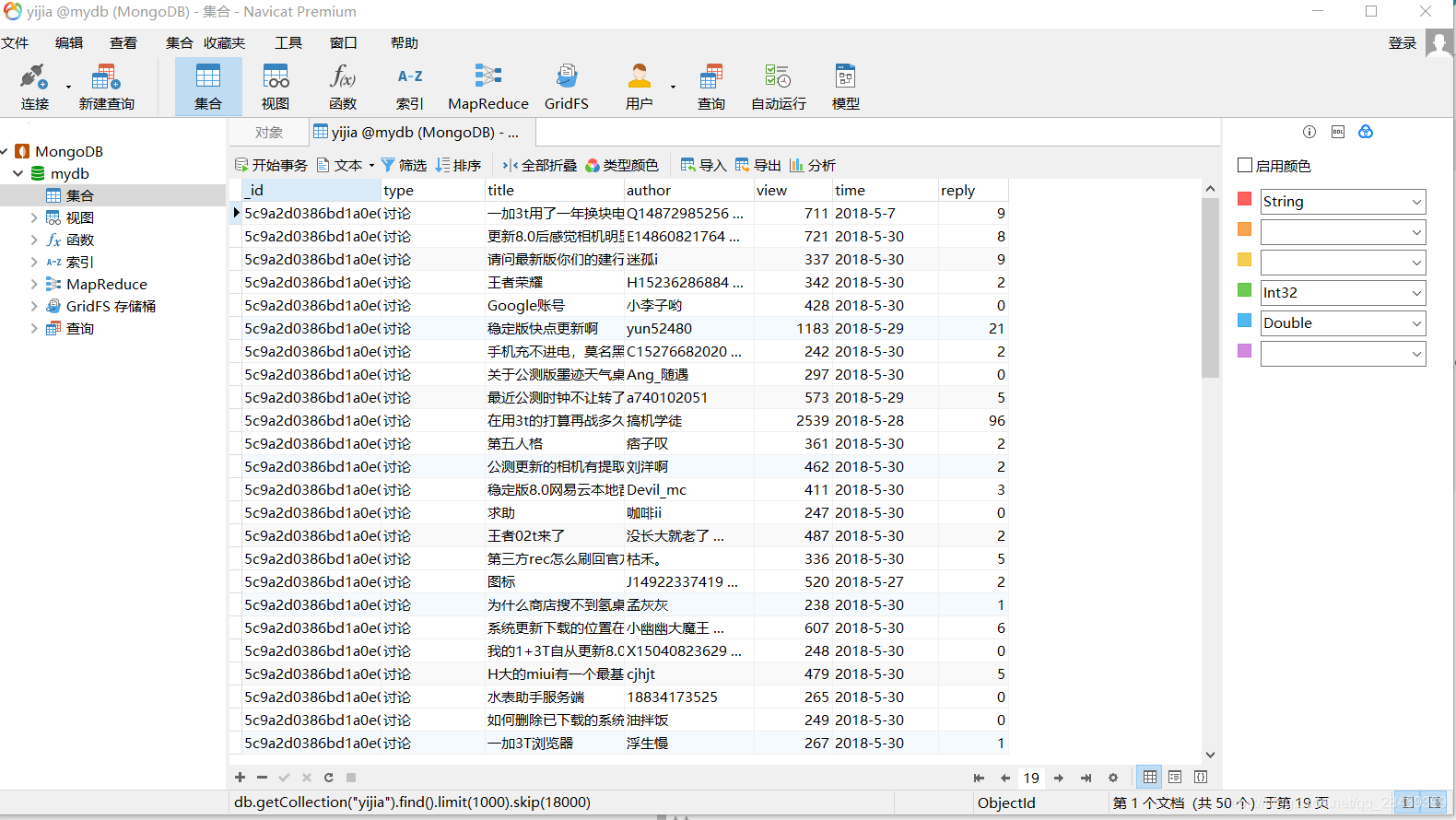

多线程可以自己用multiprocessing玩一下

















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









