










 博客围绕样本不平衡问题展开,指出当全量数据正负样本比超4:1时需处理,且仅针对训练集。介绍了过采样(如SMOTE算法)、欠采样(如EasyEnsemble算法)及两者结合的处理方法,还提及阈值移动、扩大数据集等后续处理思路。
博客围绕样本不平衡问题展开,指出当全量数据正负样本比超4:1时需处理,且仅针对训练集。介绍了过采样(如SMOTE算法)、欠采样(如EasyEnsemble算法)及两者结合的处理方法,还提及阈值移动、扩大数据集等后续处理思路。
如何解决样本不平衡问题?
1 样本不平衡问题的处理方式
1.1 场景
最近刚好做的项目是一个二分类问题,全量数据中正负样本比超过了5:1,一般认为超过4:1则是样本不平衡,因此需要进行处理。
1.2 对训练集还是测试集用?还是全量用?
- 仅针对训练集进行样本不平衡问题的处理,测试集不用动,使用平衡后的训练集来训练模型,然后喂给测试集即可。
- 为什么呢?因为有些处理方式是新生成一批数据,这些对于实际的数据来说是不存在的,放在测试集就没有意义!
- 要保持测试集的纯净性!
2.3 处理方法有哪些?
根据周志华老师的西瓜书上描述,大概有两种方法:
2.3.1 过采样
- 过采样。增加少类样本。典型算法是SMOTE算法
什么叫SMOTE方法呢?原理是啥?
SMOTE (synthetic minority oversampling technique) 的思想概括起来就是在少数类样本之间进行插值来产生额外的样本。
以下图为例,选择k近邻(此处k=3)的方式,随机选择k中的一个点,然后将选择的点的坐标乘以0~1之间的随机数,然后加上本身点的坐标,形成了一个新的样本点!一般在两点之间的连线上!
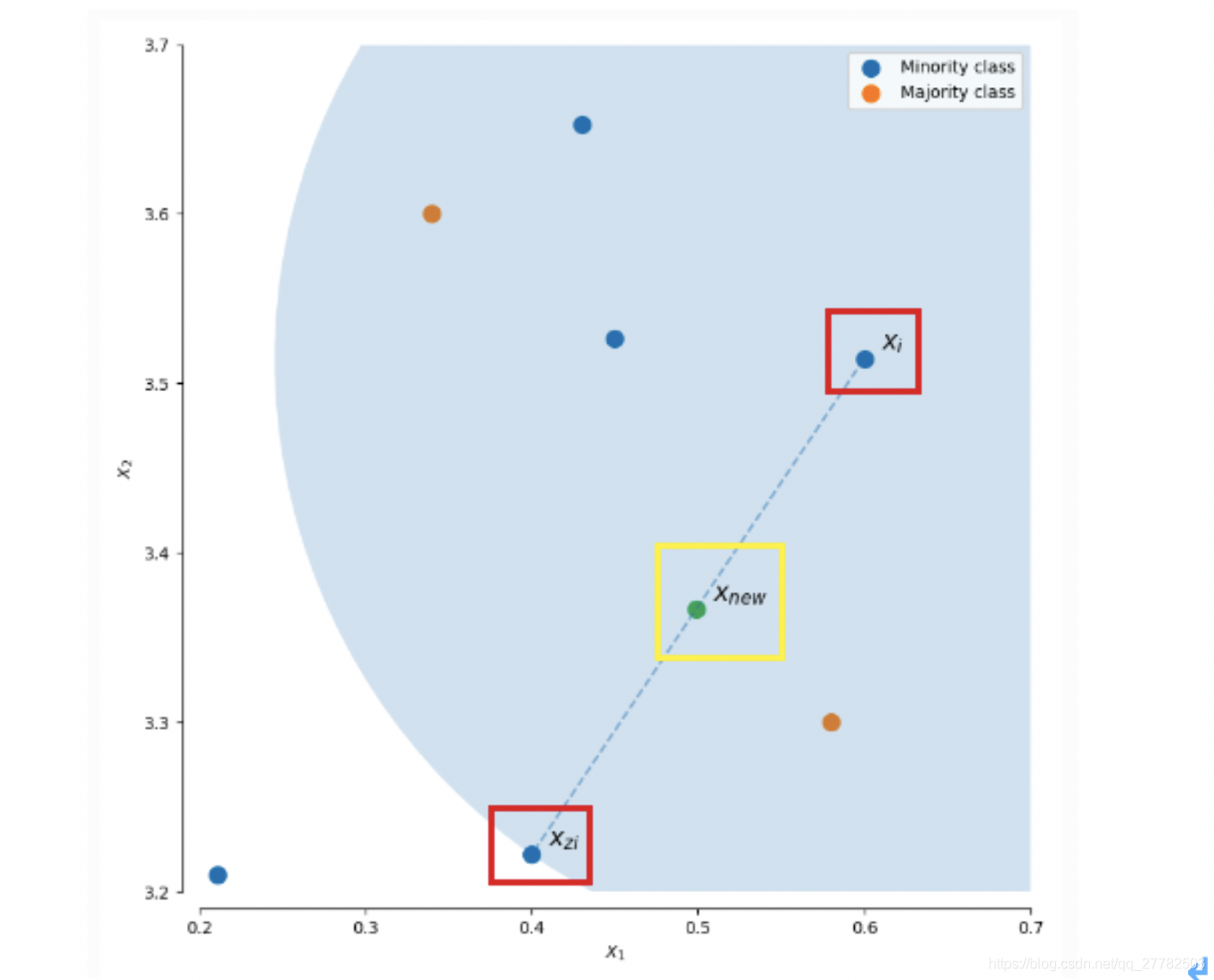
2.3.2 过采样Python实现
from imblearn.over_sampling import SMOTE, ADASYN
def SMOTE_(X, y, df):
# 作用:对训练集进行过采样 使得训练集正负样本比差不多
# X表示训练集的X
# y表示训练集的y
# df表示数据集
# SMOTE方法:对于少数类样本a, 随机选择一个最近邻的样本b, 然后从a与b的连线上随机选取一个点c作为新的少数类样本;
# 返回的结果是:新的训练集的X(df_new)和y(y_resampled_smote)
X_resampled_smote, y_resampled_smote = SMOTE().fit_sample(X, y)
df_new = pd.DataFrame(X_resampled_smote, columns=df.columns)
return df_new, y_resampled_smote
2.3.3 欠采样
- 欠采样。减小多类样本。典型算法是EasyEnsemble算法。
思想:
- 首先通过从多数类中独立随机抽取出若干子集
- 将每个子集与少数类数据联合起来训练生成多个基分类器
- 最终将这些基分类器组合形成一个集成学习系统。
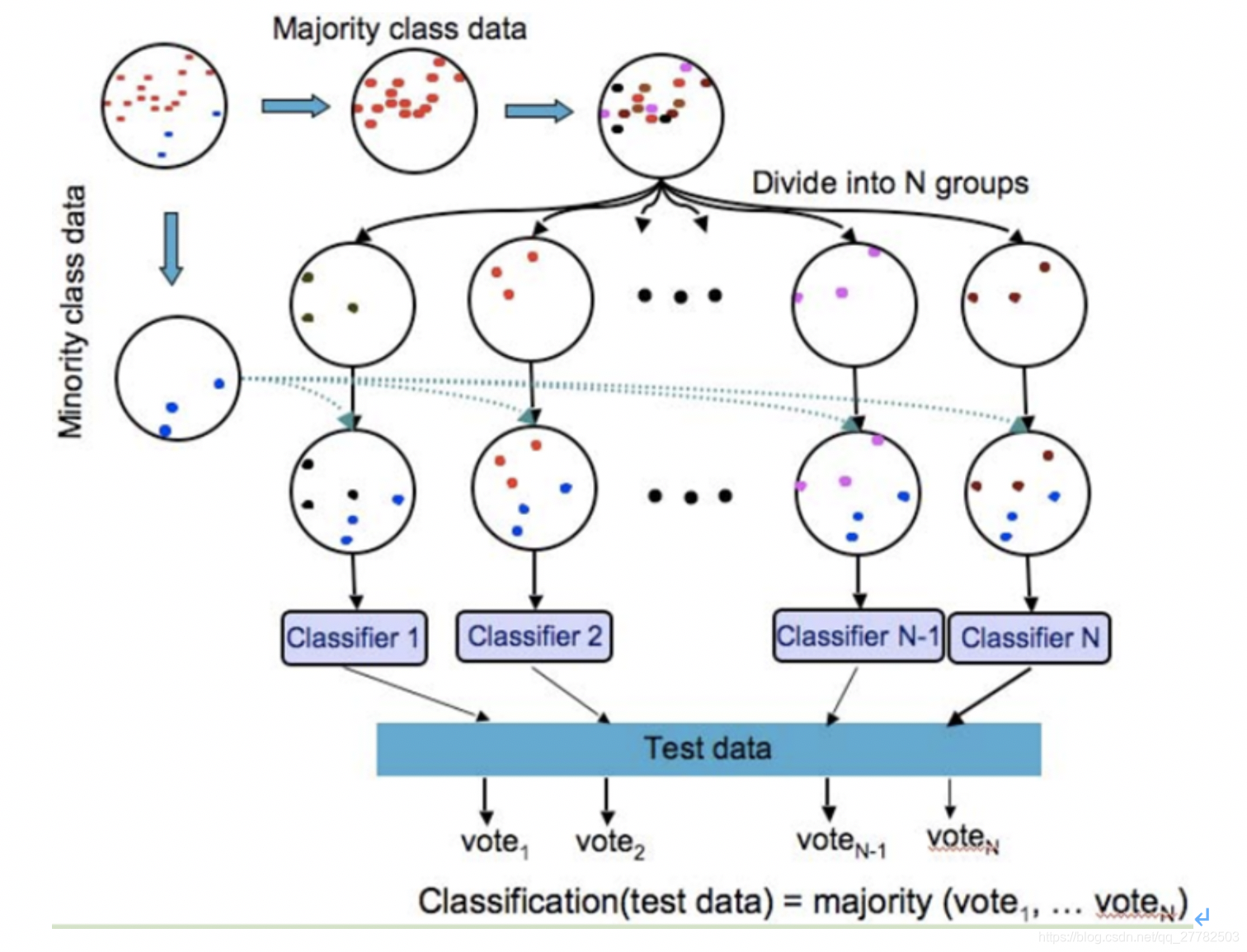
总结来说,就是将多类样本分成几份,然后分别和训练集一起组成新的训练集来训练模型,然后分别对测试集进行预测,最后使用模型融合的方法融合多模型的结果!
2.3.4 欠采样Python实现
from imblearn.ensemble import EasyEnsembleClassifier
eec = EasyEnsembleClassifier(random_state=42)
eec.fit(X, y)
# 接下来就是评估模型效果即可!
所以EasyEnsemble的Python实现还是很简单的 重要的是原理清楚就ok!
2.3.5 两种方法的结合
不局限于欠采样和过采样单独方法的运用,可以结合欠采样和过采样两种方法,一起使用!
1、SMOTE+Tomek Links
-
SMOTE:过采样的方式,通过对小类进行插值拟合新样本,上面已介绍过~
-
Tomek Links:欠采样。Tomek links被定义为相反类最近邻样本之间的一对连接。
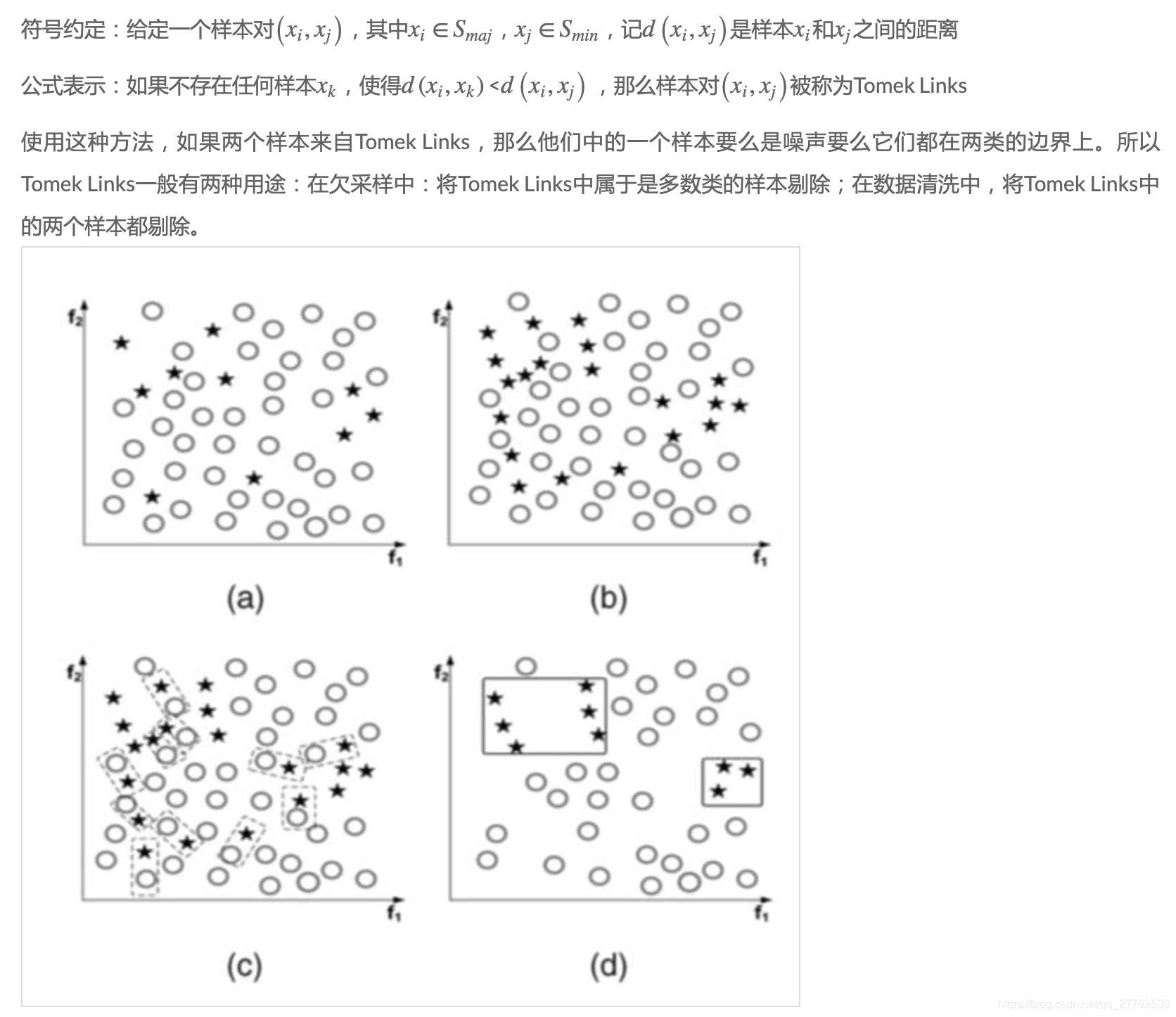
-
结合的流程:
- 利用SMOTE方法生成新的少数类样本,得到扩充后的数据集T
- 剔除T中的Tomek Links对
为什么可以实现比较好的效果呢?
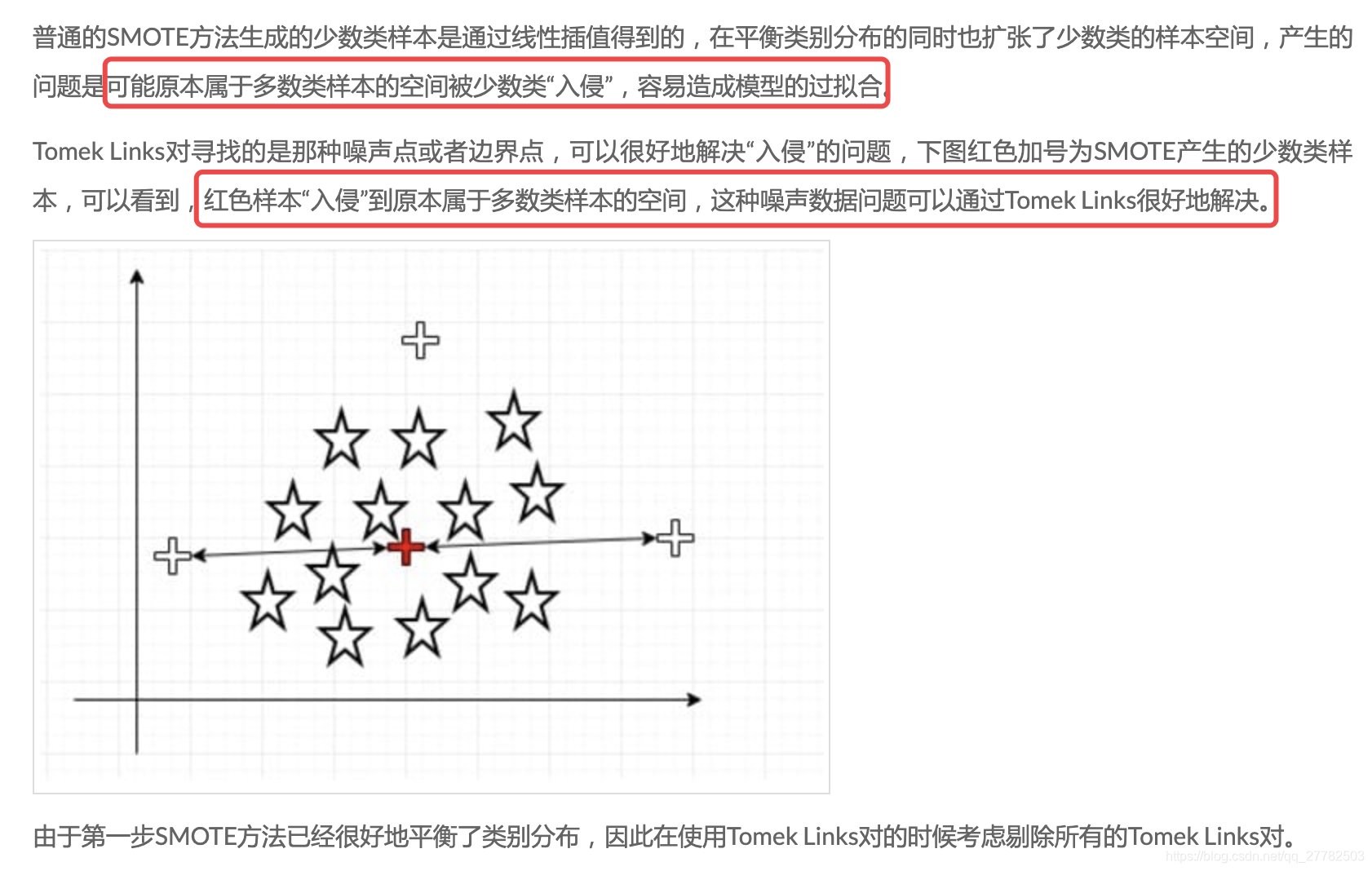
2、SMOTE+KNN
-
结合过程:
- 利用SMOTE方法生成新的少数类样本,得到扩充后的数据集T
- 对T中的每一个样本使用KNN(一般K取3)方法预测,若预测结果与实际类别标签不符,则剔除该样本。
3 参考
- https://blog.youkuaiyun.com/qq_27802435/article/details/81201357#commentBox
- https://blog.youkuaiyun.com/heyongluoyao8/article/details/49408131
- https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.ensemble.EasyEnsembleClassifier.html
- 参考:https://plushunter.github.io/2017/04/18/机器学习算法系列(17):非平衡数据处理/
- 机器学习中样本不平衡的处理方法
- 文献综述
4 后续工作-其余处理样本不平衡问题的方法
- 上述样本不平衡问题的处理方式为两种特别经典的方式,后续可以补充其余的!以及具体的案例实现!
0716更新
如何处理样本不平衡问题呢?上述3种方法,欠采样和过采样或者是两者的结合其实还是从样本的角度出发解决的,能不能从其余的角度出发解决问题呢?
4.1 阈值移动
这类方法的中心思想不是对样本集和做再平衡设置,而是对算法的决策过程进行改进。

4.2 扩大数据集
首先应该想到,是否可能再增加数据(一定要有小类样本数据),更多的数据往往战胜更好的算法。因为机器学习是使用现有的数据多整个数据的分布进行估计,因此更多的数据往往能够得到更多的分布信息,以及更好分布估计。
4.3 尝试对模型进行惩罚
- 比如你的分类任务是识别那些小类,那么可以对分类器的小类样本数据增加权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集),从而使得分类器将重点集中在小类样本身上。
- 一个具体做法就是,在训练分类器时,若分类器将小类样本分错时额外增加分类器一个小类样本分错代价,这个额外的代价可以使得分类器更加“关心”小类样本。如penalized-SVM和penalized-LDA算法。
4.4 将问题变为异常点检测
- 我们可以从不同于分类的角度去解决数据不均衡性问题,我们可以把那些小类的样本作为异常点(outliers),因此该问题便转化为异常点检测(anomaly detection)与变化趋势检测问题(change detection)。
- 异常点检测是对那些罕见事件进行识别。如通过机器的部件的振动识别机器故障,又如通过系统调用序列识别恶意程序。这些事件相对于正常情况是很少见的。
4.5 特殊的集成的方法
-
首先使用原始数据集训练第一个学习器L1。
-
然后使用50%在L1学习正确和50%学习错误的的那些样本训练得到学习器L2,即从L1中学习错误的样本集与学习正确的样本集中,循环一边采样一个。
-
接着,使用L1与L2不一致的那些样本去训练得到学习器L3。
-
最后,使用投票方式作为最后输出。
那么如何使用该算法来解决类别不平衡问题呢? -
假设是一个二分类问题,大部分的样本都是true类。让L1输出始终为true。
-
使用50%在L1分类正确的与50%分类错误的样本训练得到L2,即从L1中学习错误的样本集与学习正确的样本集中,循环一边采样一个。因此,L2的训练样本是平衡的。
-
L使用L1与L2分类不一致的那些样本训练得到L3,即在L2中分类为false的那些样本。
-
最后,结合这三个分类器,采用投票的方式来决定分类结果,因此只有当L2与L3都分类为false时,最终结果才为false,否则true。

















 1284
1284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









