







在基于隐私保护的数据发布研究中,主要考虑两个因素:1)隐私的保护性,即确保数据不会造成隐私泄漏;2)数据的有效性,即数据隐私保护后数据仍具有效用,在后续数据挖掘等工作中仍然具有较高的精确度
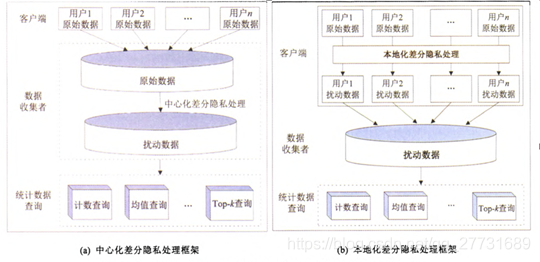
差分隐私主要分为4类,本地化差分隐私、中心化差分隐私、分布式差分隐私和混差分隐私。
1、本地化差分隐私(ε-LDP)
在本地化差分隐私中,一个统计数据库的查询结果不会受到任何单一隐私数据的影响,它能在确保处理后统计信息可用的需求下保护个人信息不被泄露。其主要思想是利用对敏感问题响应的不确定性实现对原始数据的隐私保护,进而研究对敏感属性值的隐私化处理及其频数、均值的统计校正处理和发布。
噪声机制
本地化差分隐私中,每个用户将各自的数据进行扰动后,再上传至数据收集者处,而任意两个用户之间并不知晓对方的数据记录,本地化差分隐私中并不存在全局敏感性的概念。目前,随机响应(randomized response) 技术是本地化差分隐私保护技术的主流扰动机制
随机响应算法( Randomized Response,RR) 是最典型的 LDP 算法。但 RR 存在一个不足,它对于超过两种取值的数据并不适用,仅对包含两种取值的离散型数据进行响应。为此,一个更普遍使用的随机响应 GRR( Generalized randomized response)算法被提出。即对于收集到的每一条私有数据
x
∈
X
x\in X
x∈X,X=Z=[k],用户以p的概率发送x的真实值,并以概率1-p从X{x} 中发送随机选择的值x^\prime,扰动函数如下公式所示.
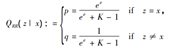
①、扰动性统计
引入一个现实场景:有n个用户,假设AIDS患者的真实比例为\pi。我们希望对其比例进行统计,于是发起一个敏感的问题:“你是否为AIDS患者?”,每个用户对此进行响应,第i个用户的答案为X_i是或否,但出于隐私性考虑,用户不会直接响应真实答案.假设其借助于一枚非均匀的硬币来给出答案,其正面向上的概率为p,反面向上的概率为1-p 。抛出该硬币,若正面向上,则回答真实答案,反面向上,则回答相反的答案。
首先,进行扰动性统计。利用上述扰动方法对n个用户的回答进行统计,可以得到艾滋病患者人数的统计值.假设统计结果中,回答“是”的人数为n_1,则回答“否”的人数为n-n_1。 显然,按照上述统计,回答“是”和“否”的用户比例如下:
P(
X
i
X_i
Xi=“yes”)=
π
\pi
π p+(1-
π
\pi
π)(1-p)
P(
X
i
X_i
Xi=“no”)=(1-
π
\pi
π)p+
π
\pi
π(1-p)
②、校正
显然,上述统计比例并非真实比例的无偏估计,因此需要对统计结果进行校正。
因此,构建以下似然函数:
L=[πp+(1-p)(1-π)]n1[(1-π)p+π(1-p)]n-n1
并得到\pi的极大似然估计:
π
^
\hat{\pi}
π^=
p
−
1
2
p
−
1
\frac{p-1}{2p-1}
2p−1p−1+
n
1
(
2
p
−
1
)
n
\frac{n_1}{(2p-1)n}
(2p−1)nn1
π
^
\hat{\pi}
π^的数学期望证明
π
^
\hat{\pi}
π^是真实
π
\pi
π的无偏估计:
E(
π
^
\hat{\pi}
π^)=
1
2
p
−
1
[
p
−
1
+
1
n
∑
i
=
1
n
X
i
]
=
12
p
−
1
[
p
−
1
+
1
n
n
P
r
(
X
i
=
"
y
e
s
"
)
]
\frac{1}{2p-1}[p-1+\frac{1}{n}\sum_{i=1}^{n}X_i]=12p-1[p-1+1nnPr(Xi="yes")]
2p−11[p−1+n1∑i=1nXi]=12p−1[p−1+1nnPr(Xi="yes")]
即 E
(
π
^
)
=
1
2
p
−
1
[
p
−
1
+
π
p
+
(
1
−
π
)
(
1
−
p
)
]
=
π
(\hat{\pi})=\frac{1}{2p-1}[p-1+\pi p+(1-\pi)(1-p)]=π
(π^)=2p−11[p−1+πp+(1−π)(1−p)]=π
由此可以得到校正的统计值,其中N表示统计得到的AIDS人数估计值:
N=
π
^
×
n
=
p
−
1
2
p
−
1
n
+
n
1
2
p
−
1
\hat{\pi}\times n=\frac{p-1}{2p-1}n+\frac{n_1}{2p-1}
π^×n=2p−1p−1n+2p−1n1
2、中心化差分隐私
差分隐私方法最初被提出时大多采用中心化的形式,通过一个可信的第三方数据收集者汇总数据,并对数据集进行扰动从而实现差分隐私。在中心化差分隐私保护技术中要求一个可信的第三方数据收集者来对数据分析结果进行隐私化处理。
噪声机制
拉普拉斯机制(连续型数据查询),指数机制(离散型数据查询)两种机制都和查询函数的全局敏感度相关,而全局敏感性则是定义在至多相差一条记录的近邻数据集之上,使得攻击者无法根据统计结果推测个体记录,即将个体记录隐藏在统计结果之中。
例:表1显示了一个医疗数据集D,其中的每个记录表示某个人是否患有癌症(1表示是,0表示否).数据集为用户提供统计查询服务(例如计数查 询),但不能泄露具体记录 的值.设用户输入参数Si,调用查询函数f(i)=count(i)来得到数据集前i行中满足“诊断结 果”=1的记录数量,并将函数值反馈给用户.假设攻击者欲推测Alice是否患有癌症,并且知道Alice在数据集的第5行,那么可以用count(5)-count(4)来推出正确的结果。

但是,如果f是一个提供ε-差分隐私保护的查询函数,例如f(i)=count(i)+noise,其中noise是服从某种随机分布的噪声.假设f(5)可能的输出来自集合{2,2,5,3},那么,f(4)也将以几乎完全相同的概率输出{2,2,5,3}中的任一可能的值,因此攻击者无法通过f(5)-f(4)来得到想要的结果.这种针对统计输出的随机化方式使得攻击者无法得到查询结果间的差 异,从而能保证数据集中每个个体的安全。
3、分布式差分隐私
分布式差分隐私指的是在若干个可信中间节点上先对部分用户发送的数据进行聚合并实施隐私保护,然后传输加密或扰动后的数据到服务器端,确保服务器端只能得到聚合结果而无法得到数据。该方案需要客户端首先完成计算并进行简单的扰动( 例如较高隐私预算的本地化差分隐私) 或加密,将结果发送至一个可信任的中间节点,然后借助可信执行环境( Trusted ExecutionEnvironment,TEE)、安全多方计算、安全聚合( Secure Aggregation)或安全混洗( Secure Shuffling)等方法,在中间节点实现进一步的隐私保护,最终将结果发送至服务器端。
4、混合差分隐私
混合差分隐私方案由Avent等提出,它通过用户对服务器信任关系的不同对用户进行分类。举例而言,最不信任服务器的用户可以使用最低隐私预算的本地化差分隐私,而最信任服务器的用户甚至可以直接发送原始参数; 服务器也将根据用户的信任关系对数据进行不同程度的处理。该方案的问题是同样需要一定的通信成本,并且还需要付出额外的预处理成本以划分信任关系。

















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









