







目录
HashMap中的属性
/**
* The default initial capacity - MUST be a power of two.
*
* 解释:
* capacity:HashMap容量。表示HashMap中数组table的大小。默认为16。
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*
* 解释:
* 最大容量:2的30次方
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*
* 解释:
* 默认装载因子:与数组扩容有关。用于计算扩容阈值 threshold = capacity * load_factory
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*
* 解释:
* 树化阈值:当链表长度大于8时,链表转化为红黑树
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*
* 解释:
* 当红黑树中节点小于6时,红黑树退化为链表
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*
* 解释:
* HashMap中的数组结构
*/
transient HashMap.Node<K,V>[] table;
/**
* The number of key-value mappings contained in this map.
*
* 解释:
* HashMap中的kv键值对个数
*/
transient int size;
/**
* The next size value at which to resize (capacity * load factor).
*
* 解释:
* 数组扩容阈值 threshold = capacity * load_factory
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
/**
* The load factor for the hash table.
*
* 解释:
* 装载因子,与数组扩容阈值 threshold 有关
* @serial
*/
final float loadFactor;构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* Returns a power of two size for the given target capacity.
*
* 解释:
* 返回给定目标容量的2次幂大小
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}注:有参构造函数会在将输入的capacity改为大于等于capacity的最小的2的次方的数值,如:输入2会修改为2;输入3会修改为4;输入6会修改为8。
HashMap允许空键空值么
HashMap最多只允许一个键为Null(多条会覆盖),但允许多个值为Null
static final int hash(Object key) {
int h;
// 允许key为null,key为null时,hash值设为0
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}putVal分析
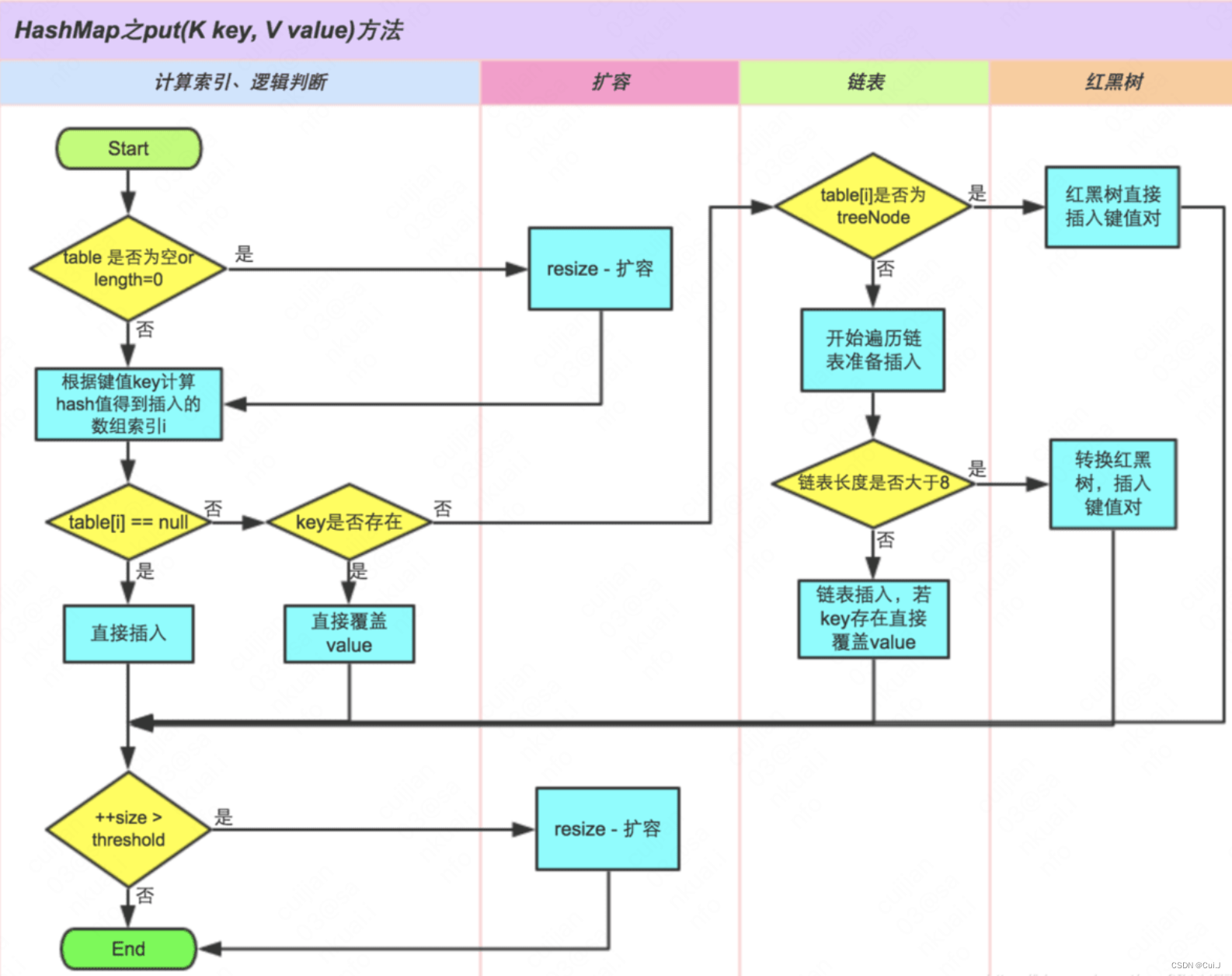
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// tab:引用HashMap中的table数组
// n:table数组大小
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;
// 1、数组为null 或 大小为0,则通过resize初始化数组
// 注:在创建HashMap对象后,数组不会初始化,只有首次调用put时才会初始化
if ((tab = table) == null || (n = tab.length) == 0)
// 1.1 将初始化后数组的大小赋值给n
n = (tab = resize()).length;
// 2、通过与运算(&)计算hash值和数组长度取余的值,即为key应放入的数组下标位置(这也是为什么数组长度需要设为2的n次方),
// 然后将数组下标元素赋值给p
if ((p = tab[i = (n - 1) & hash]) == null)
// 2.1 如果该下标位置为空,构建node节点并放到改下标位置,kv插入完成
tab[i] = newNode(hash, key, value, null);
else {
// 2.2 该下标位置已经有数据了
HashMap.Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 2.2.1 数组下标位置第一个节点的key和待插入key相等(hash值相等 且 equal相等)
e = p;
else if (p instanceof HashMap.TreeNode)
// 2.2.2 数组下标位置为TreeNode类型
e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 2.2.3 数组下标位置为链表,遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 2.2.3.1 遍历链表,找到链表表尾,创建node节点,并将已存在节点的next指针指向新节点,kv插入完成
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 新节点插入完成后,节点数超过 TREEIFY_THRESHOLD ,进入树化逻辑,但并不一定会树化
treeifyBin(tab, hash);
// 2.2.3.2 插入完成,跳出链表循环
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 2.2.3.3 遍历过程中,如果某个节点的key和待插入key相等( hash 和 equal 都相等),跳出遍历
break;
// 2.2.3.4 指针往后移动,用于下次循环遍历下一个节点
p = e;
}
}
if (e != null) { // existing mapping for key
// 2.3 存在与待插入key值相等的node节点,替换node节点的value为新value
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
// 返回旧值,不进行后续的扩容判断,因为size不变
return oldValue;
}
}
++modCount;
if (++size > threshold)
// 3、kv插入完成后的size大于扩容阈值
resize();
afterNodeInsertion(evict);
return null;
}注:
- 先插入数据,再判断如果插入后链表节点数大于数化阈值8,则进入树化逻辑,数化逻辑中判断如果数组长度小于64,会执行resize()扩容,大于64时才会树化。
- 先插入数据,再判断如果插入后size大于扩容阈值,则扩容。
resize分析
final HashMap.Node<K,V>[] resize() {
HashMap.Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
// 如果容量大于了最大容量时,直接返回旧的table
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 扩容两倍后容量小于最大容量 且 原容量大于默认初始化的容量,对阈值增大两倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 默认初始化容量和阈值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap];
table = newTab;
if (oldTab != null) {
// 遍历旧数组的每个桶
for (int j = 0; j < oldCap; ++j) {
// e:桶的第一个节点
HashMap.Node<K,V> e;
// 将桶内的第一个节点赋值给e,桶为null则不进行操作
if ((e = oldTab[j]) != null) {
// 将原哈希桶置为null,让gc回收(根可达性分析算法)
oldTab[j] = null;
if (e.next == null)
// 如果桶的第二个节点为null,则只需要将e进行转移到新的哈希桶中
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof HashMap.TreeNode)
// 如果哈希桶内的节点为红黑树,则交给TreeNode进行转移
((HashMap.TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 将桶内的node转移到新的哈希桶内
// loHead、loTail记录低位链表的头部和尾部节点(即移动到新数组后,下标不需要变化的node链表)
HashMap.Node<K,V> loHead = null, loTail = null;
// hiHead,hiTail与上面的一样,区别在于这个是高位链表(即移动到新数组后,下标需要变化的node链表)
HashMap.Node<K,V> hiHead = null, hiTail = null;
HashMap.Node<K,V> next;
do {
next = e.next;
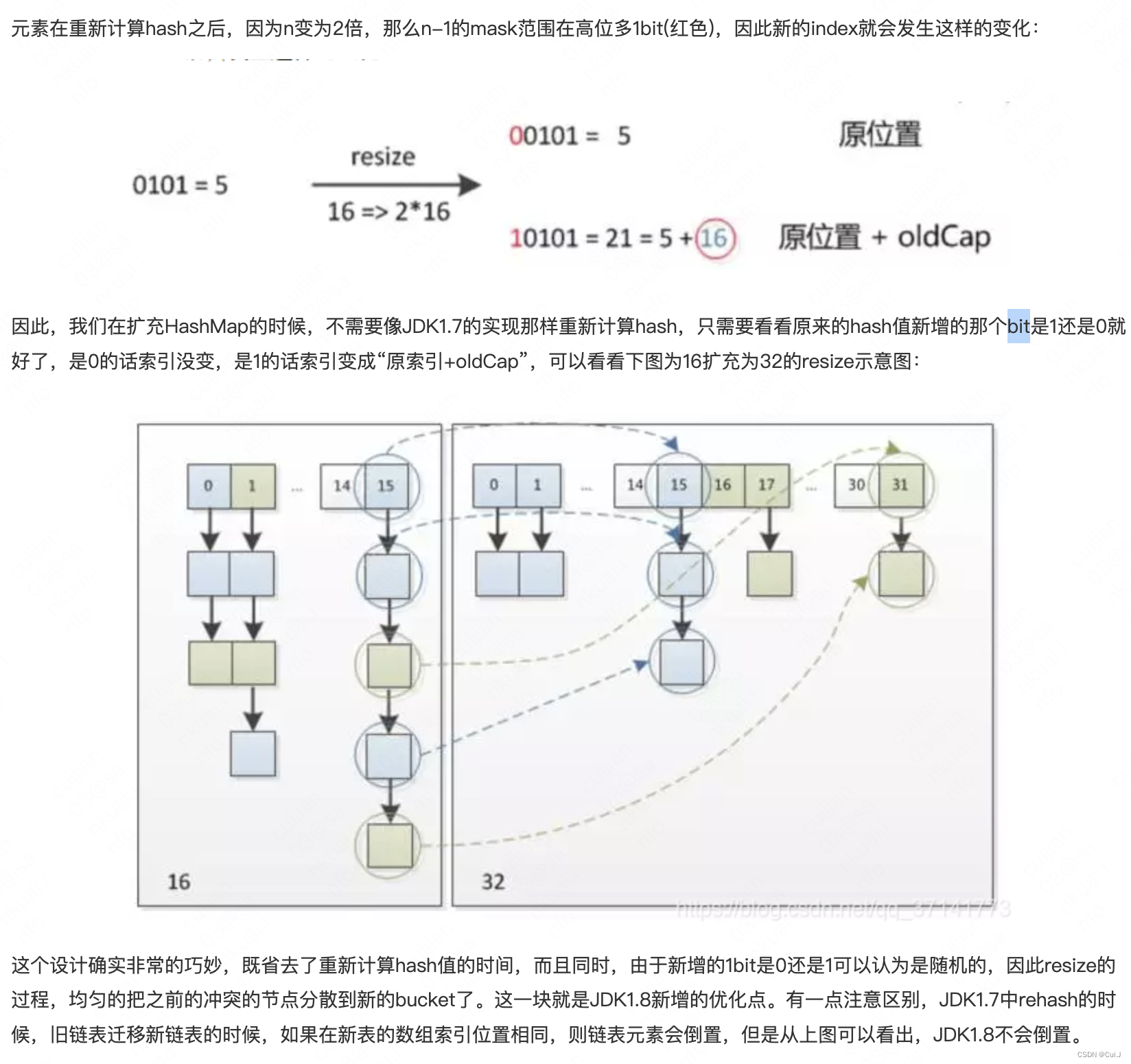
// jdk1.7是将哈希桶的所有元素重新进行hash算法后转移到新的哈希桶中
// 而1.8后,则是利用哈希桶长度在扩容前后的区别,将桶内元素分为原先索引值和新的索引值(即原先索引值+原先容量)。
if ((e.hash & oldCap) == 0) {
// 扩容前后对当前节点的下标值 没有发生改变
if (loTail == null)
// loTail低位尾结点为null时,代表低位桶内无元素,则记录低位头节点
loHead = e;
else
// 将低位尾节点next指向当前节点,即新的节点是插在链表的后面,尾插法
loTail.next = e;
loTail = e;
}
else {
// 扩容前后对当前节点的下标值 发生改变
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 如果低位链表记录不为null,则低位链表放到新数组的 原 下标位置中
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 如果高位链表记录不为null,则高位链表放到新数组的 新 下标位置中
if (hiTail != null) {
hiTail.next = null;
// j + oldCap 计算新数组下标
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}数组长度为什么为2的n次幂?
1、计算数组下标时提高性能。位运算直接对内存数据操作,不用转成十进制计算,在定位目标值数组下标时可以通过与运算 ( length - 1 ) & hash 计算,因为当length为2的n次方时,
(length - 1)&hash = hash%length。
2、实现均与分布。回答1中说明了使用 ( length - 1 ) & hash 计算数组下标,因为在使用不是2的次方的数字的时候,Length - 1 的值是所有二进制位全为1,这种情况下,计算后下标的值就等于hash后几位的值,只要输入的hash本身分布均匀,计算的下标位置就是均匀的。
3、快速计算容量。
- 创建HashMap对象时传入的自定义容量如果不是2的次方,构造函数会计算出第一个比他大的2的幂并设置为容量大小。
- 在resize()扩容的时候通过容量右移一位的方式扩容为原来的2倍。
4、扩容后,重新计算数组下标逻辑简单。扩容为原来的2倍,( length - 1 ) & hash 重新计算下标只是在原有计算逻辑多加一个bit。
为什么数组大小超过64才会树化?
1、如果数组长度小时,元素的碰撞率会比较高,和容易导致桶中节点数过多。
2、如果数组长度小时,会导致频繁扩容,从而导致红黑树不断进行拆分重新映射到新数组。
参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









