






这篇论文简直是视觉语言模型(VLM)的“瘦身教练”(咳咳 就是不需锻炼就能瘦 爽~)!大家都知道,ViT和VLM这类模型虽然强悍,但它们的计算量却像吃自助餐一样疯狂——自注意力机制的二次方复杂度,让显卡分分钟想罢工!于是,作者团队祭出了SAINT这个“训练免费”的剪枝神器,通过动态分析token的相似性,像精准的园丁一样修剪冗余部分,让模型跑得飞快还不掉性能!
论文:Similarity-Aware Token Pruning: Your VLM but Faster
链接:https://arxiv.org/abs/2503.11549v1
项目:https://github.com/ArmenJeddi/saint
方法
SAINT的核心思路可以概括为:用图论玩消消乐!它把每个token当作图中的节点,计算它们之间的余弦相似度,构建一个“谁和谁长得像”的关系网。接着,SAINT像侦探一样,通过节点度数(邻居数量)和相似度分数,揪出那些“混日子”的冗余token,然后无情踢出群聊!
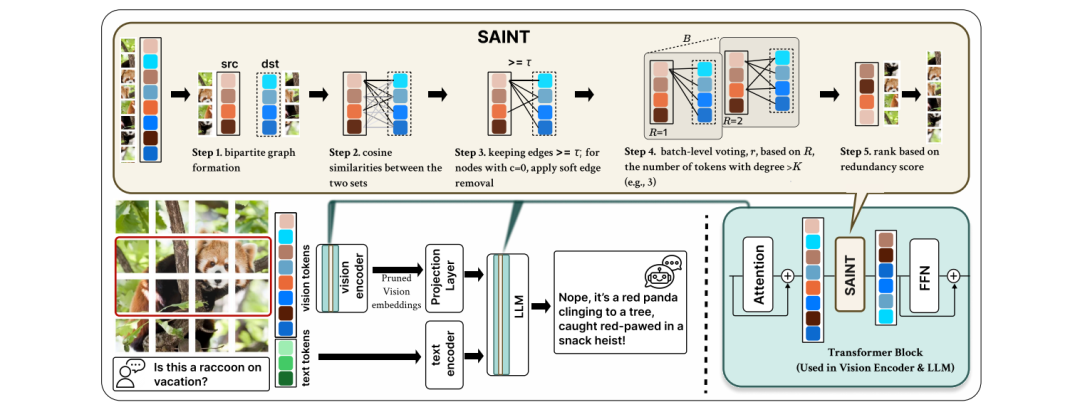
整个过程分三步走:
二分图构建:把token分成两队(src和dst),计算两队之间的相似度,像相亲大会一样匹配“灵魂伴侣”。
动态投票:根据相似度阈值(τ)和邻居数量(K),让模型自己决定“这层该剪多少头发”。
冗余排名:给每个token打“无聊分”,分数高的直接淘汰,只留下最独特的仔继续干活!
实验
为了证明SAINT不是花架子,作者们祭出了一系列“魔鬼测试”:
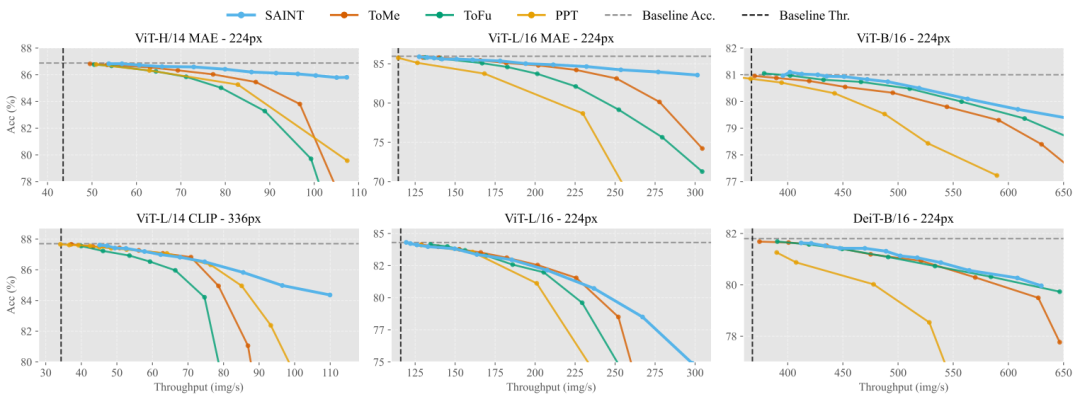
ViT实验:涡轮加速,性能稳如狗
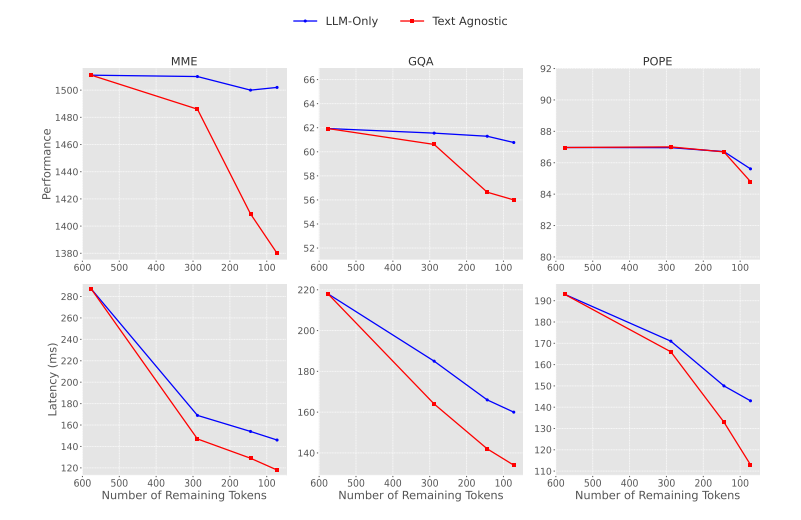
在ImageNet-1K上,SAINT给ViT-H/14模型装上了“氮气加速”——吞吐量翻倍,准确率仅掉0.6%!对比其他方法(比如ToMe和PPT),SAINT像学霸一样轻松碾压,准确率高出0.8%!
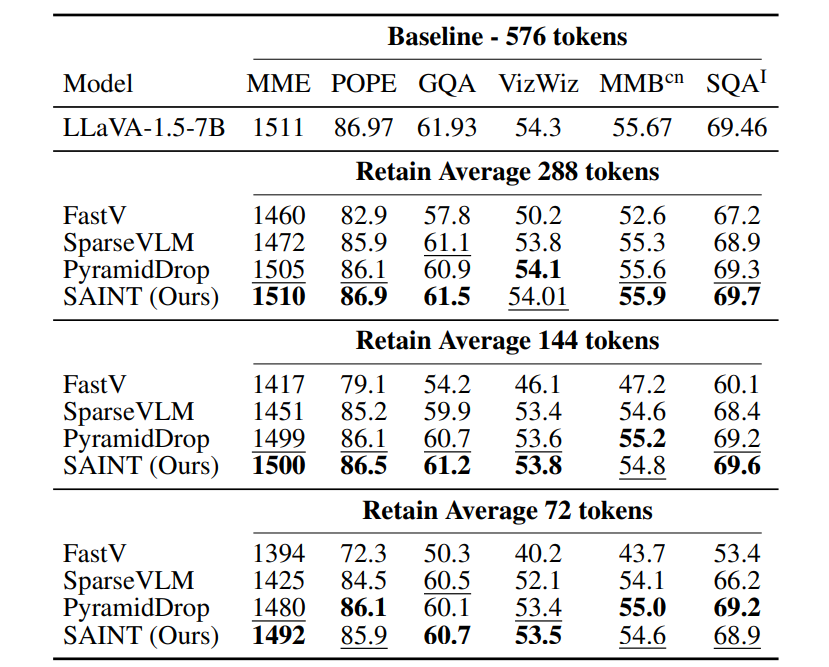
VLM实验:从大卡车变身超跑
在LLaVA-13B模型上,SAINT一口气砍掉75%的token,结果性能损失不到1%,推理速度直接对齐LLaVA-7B!这相当于把一辆载重卡车改成了特斯拉,既省电又拉风!

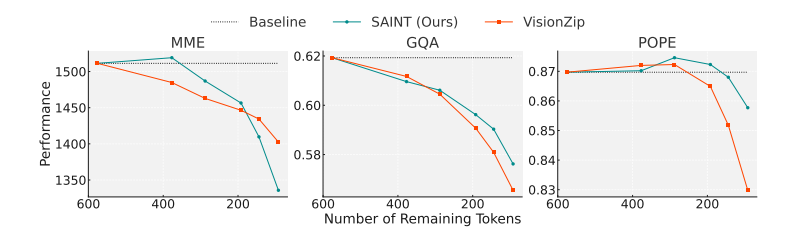
更有趣的是,作者还尝试了混合剪枝模式(ViT+LLM双管齐下),结果发现既能保住性能,又能让推理速度飞起!
结论
SAINT就像给模型装上了“智能节能模式”,通过动态剪枝冗余token,让ViT和VLM在保持智商的同时跑出博尔特的速度!无论是图像分类还是多模态任务,SAINT都证明了自己是“很强”!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









