






这是一篇让视觉模型学会“自我反思”的论文!如果你的AI在识别猫咪时,不仅能说“这是猫”,还能推理出“耳朵尖尖、尾巴长长、胡须翘翘”——是不是更靠谱?但问题来了:如果训练数据少得可怜,怎么让模型不摆烂?

论文:Visual-RFT: Visual Reinforcement Fine-Tuning
链接:https://arxiv.org/pdf/2503.01785
项目:https://github.com/Liuziyu77/Visual-RFT
传统方法(比如监督微调,SFT)需要海量标注数据,但现实中数据往往比奶茶里的珍珠还少。于是,作者脑洞大开:用强化学习(RL)给模型发“小红花”! 模型生成多个答案,通过奖励函数(比如检测任务用IoU打分)选出最优解,边试错边进步。这就是Visual-RFT的核心理念——让模型在“答题闯关”中升级!
方法
Visual-RFT的秘诀是 “多生成,严打分,勤优化”。具体流程如下:
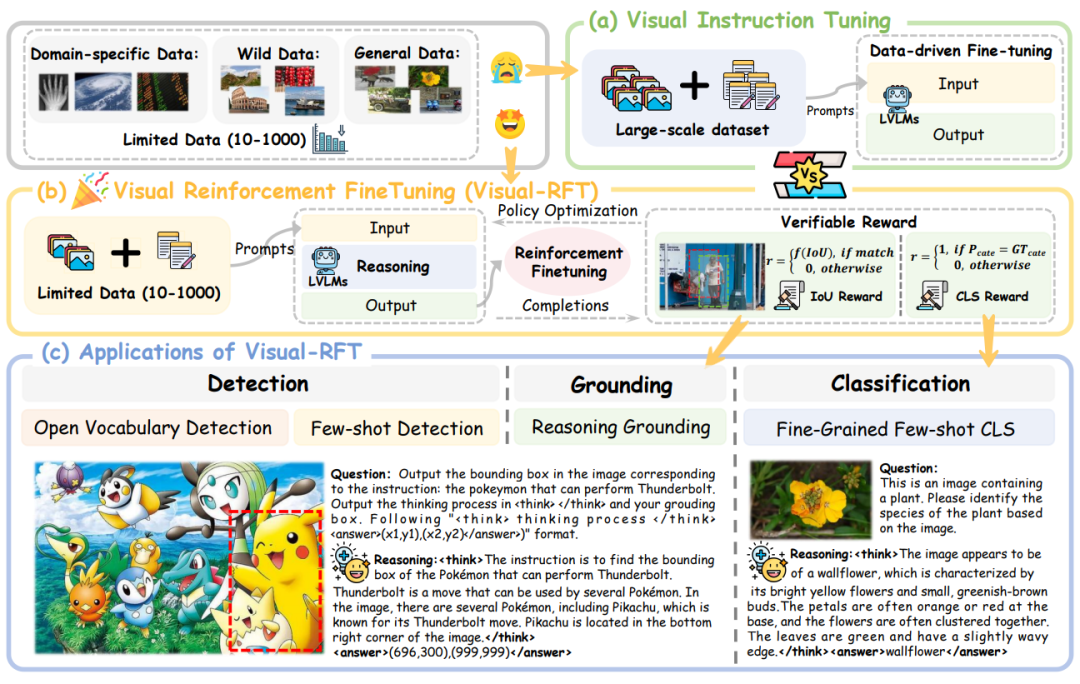
模型收到输入(图片+问题)后,会像学霸刷题一样生成多个答案,每个答案包含推理步骤和最终结果。比如检测任务,模型不仅要画框框,还要解释“为什么框这里”。
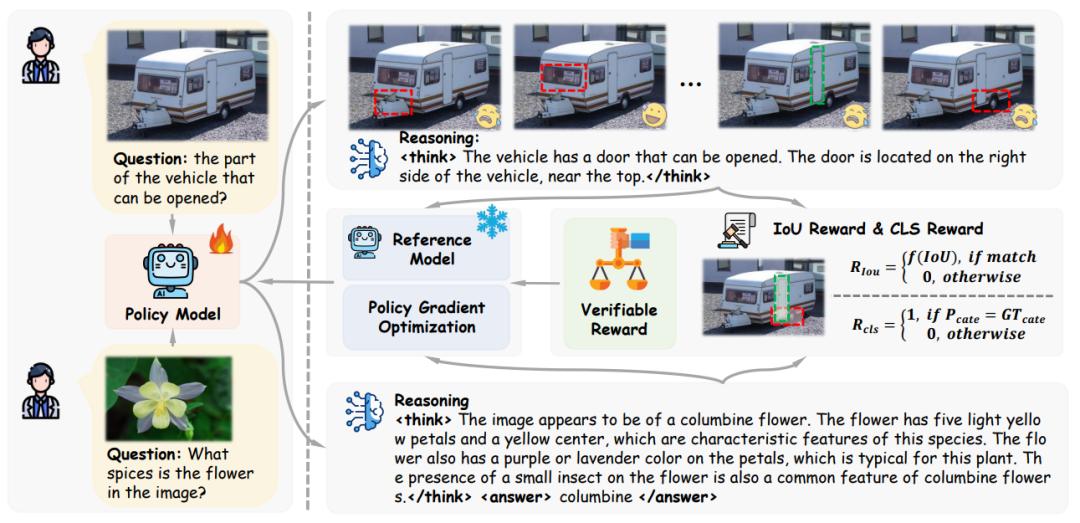
奖励函数是核心“判卷老师”!比如检测任务用IoU奖励(框框和真实框的重合度),分类任务用准确率奖励。作者还贴心地加了“格式奖励”,确保模型输出不乱码(比如必须用<think>和<answer>标签)。最后,通过GRPO算法(一种强化学习策略)更新模型,让模型越来越聪明~
整个过程就像AI在玩“大家来找茬”,每次犯错都被告知“扣10分”,然后默默改进。是不是像极了考前刷题的你?
实验
为了证明Visual-RFT不是“纸上谈兵”,作者在多个视觉任务中做了大量实验!
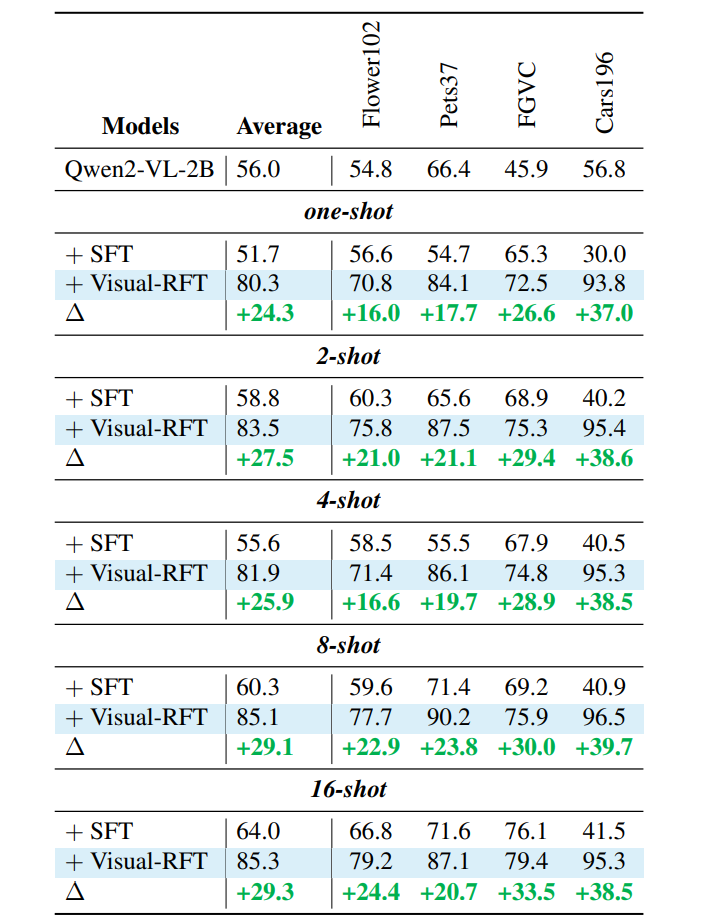
细粒度图像分类:火眼金睛
在仅有100张图的“地狱模式”下,Visual-RFT准确率比基线模型暴涨24.3%,而传统SFT反而掉了4.3%!数据越少,我越强”...
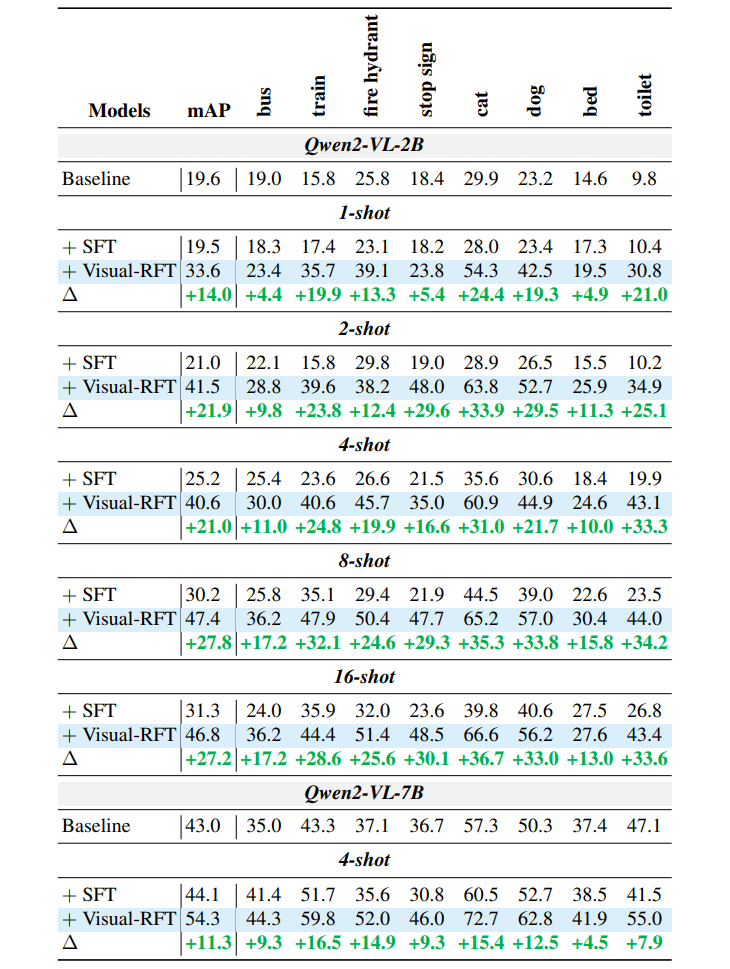
少样本目标检测:框得准,还省数据
在COCO数据集上,只用2张图训练,Visual-RFT的mAP直接飙升21.9分!LVIS数据集的稀有类别上也有15.4分提升。“瞄一眼就记住”...
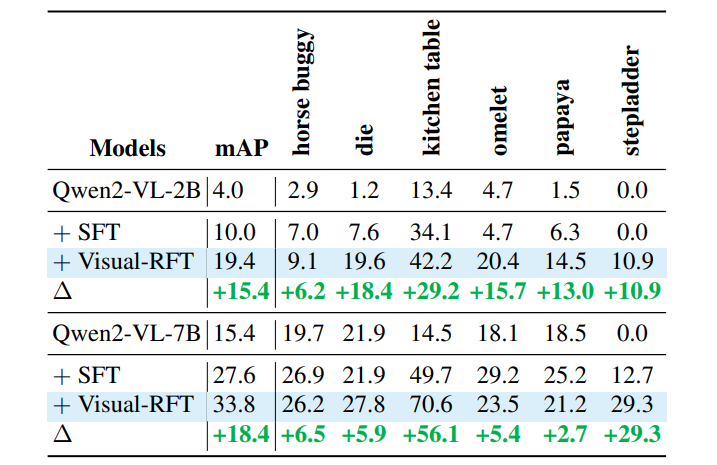
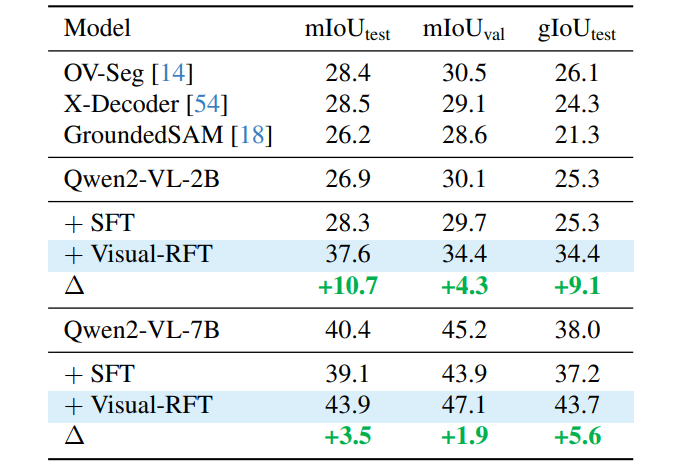
推理定位:不仅找得到,还要讲道理
在需要推理的LISA数据集上,Visual-RFT的定位精度吊打专业模型GroundedSAM。比如面对“图片里戴帽子的狗”,模型会先推理“狗在左边,帽子是红色”,再精准框选——嗯...“逻辑怪”
开放词汇检测:从“不认识”到“秒识别”
训练时没见过“蛋卷”和“蒲团”?Visual-RFT依然能检测!在LVIS罕见类别上,模型从0分直接冲到40分,“从学渣直接到学霸”啊...
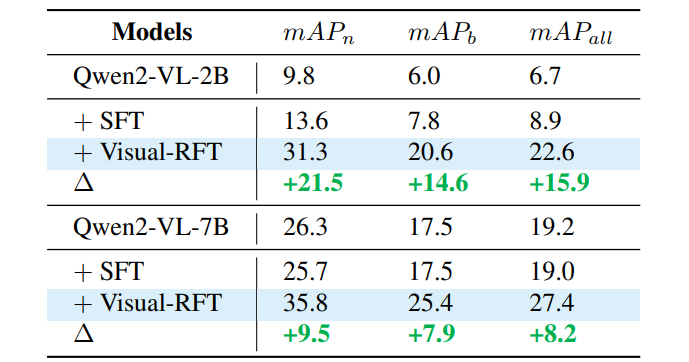
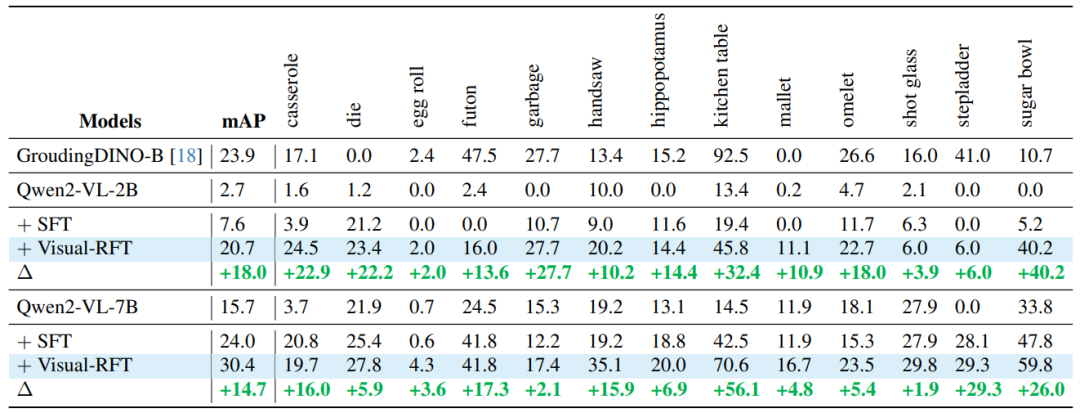
这俩tab展示了开放词汇检测结果
结论
总结一下,Visual-RFT用强化学习+可验证奖励,成功解决了数据稀缺下视觉模型摆烂的难题!无论是分类、检测还是推理任务,它都展现了“小样本,大能量”的逆天表现。
这篇论文不仅为视觉任务提供了新思路,还证明了一件事:强化学习不是语言模型的专利,视觉模型也能玩出花! 未来,我们或许能看到更多“自我进化”的视觉AI,甚至让它们学会边看边吐槽(误)。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









