







 本文深入探讨线程池的工作原理,包括线程池的管理、复用策略、队列缓存及拒绝策略,详细解析核心线程、最大线程、队列选择和拒绝策略的设定,帮助读者理解线程池在不同业务场景下的合理应用。
本文深入探讨线程池的工作原理,包括线程池的管理、复用策略、队列缓存及拒绝策略,详细解析核心线程、最大线程、队列选择和拒绝策略的设定,帮助读者理解线程池在不同业务场景下的合理应用。
聊到线程池相信大家应该都听过,其实也不排除很多程序员工作了好几年后没用过线程池,这个现象不少见。
聊点题外话,IT行业目前还是很火,形形色色的公司都有,所以就有了形形色色的程序员,外包公司慎入!慎入!慎入!
好了言归正传.
线程池地方好处:
线程使应用能够充分合理的协调利用CPU,内存,网络,I/O等系统资源。创建线程需要开辟虚拟机栈,本地方法栈,程序计数器等私有的内存空间。并且销毁时又需要回收这些资源,这样频繁的创建销毁线程会浪费大量的系统资源,增加我们并发编程的风险,如果在服务器负载过高的如何让新的线程等待或者优雅的拒绝服务呢?这些都是线程无法解决的问题,所以呢我们需要一个用来管理这些线程的池子,我们叫它线程池。另外线程池还有以下作用:
1 利用线程池管理并且复用线程,控制最大并发数
2 实现队列缓存策略以及拒绝策略
3 可以实现特定的功能,比如周期性执行,单个线程,并行执行执行等
4 可以实现环境隔离: 比如搜索和下单如果部署在同一个项目中,开辟两个线程池可以很好的让他们的环境隔离,不影响他们 各自的效率
--------------------------------------------
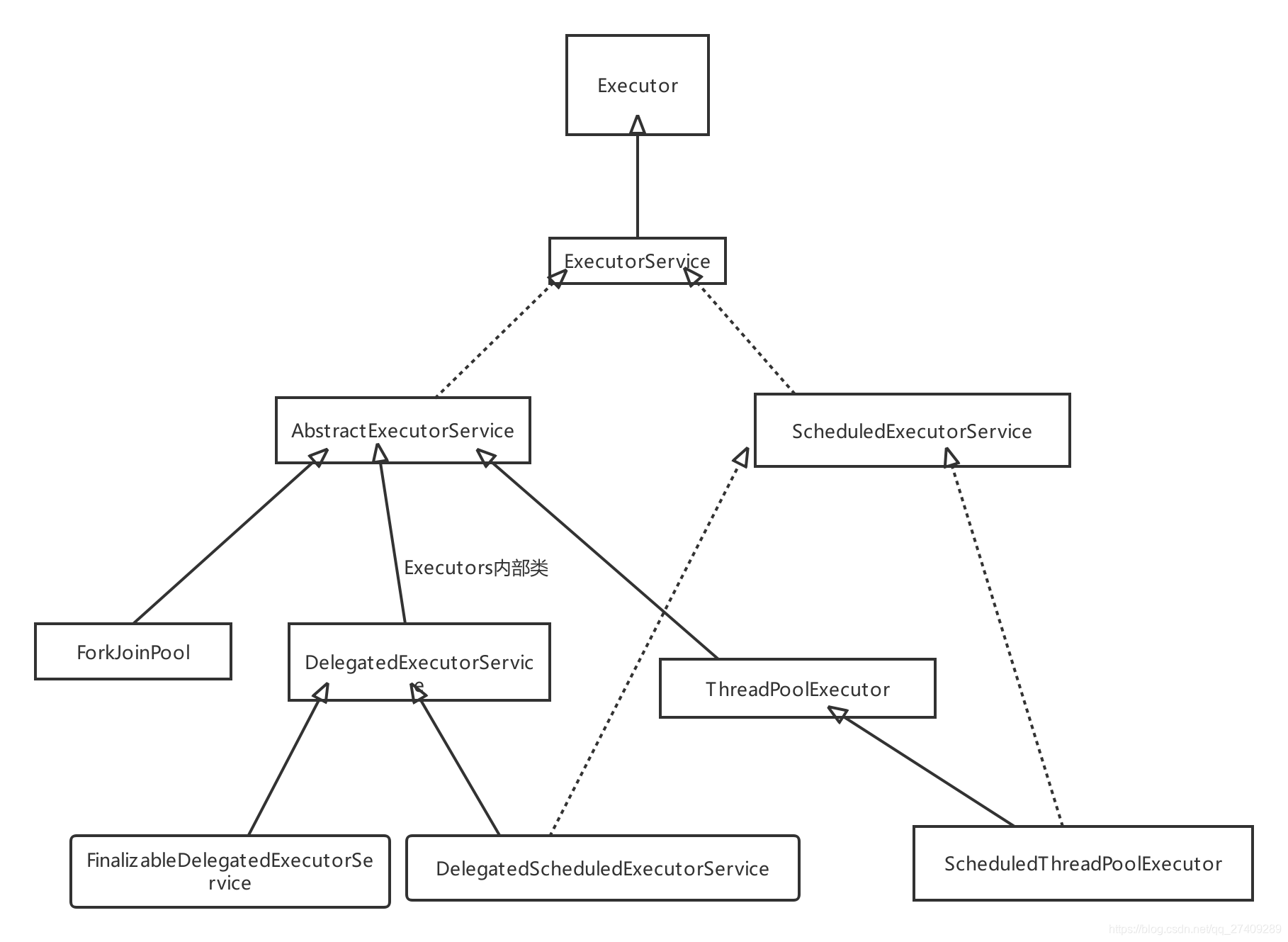
后面写: 介绍Excutors(线程池工具类:获取线程池,类似Collections) |-------->ForkJoinPool(类)
|------>AbstractExecutorService--->
Excutor顶级接口--》 ExcutorsService(接口)----> |--------->ThreadPoolExcutor(类)
|-------->ScheduledExcutorService |
|-----> ScheduledThreadPool(定时任务)
介绍下线程池的一些参数:
corePoolSize : 线程池维护线程的最少数量,哪怕是空闲的。注意这个也是可以设置存活时间的
maximumPoolSize :线程池维护线程的最大数量。
keepAliveTime : 线程池维护线程所允许的空闲时间。
unit : 线程池维护线程所允许的空闲时间的单位。
workQueue : 线程池所使用的缓冲队列,改缓冲队列的长度决定了能够缓冲的最大数量。不同的BlockingQueue决定了线程池 的排队策略。 (下面会介绍)
拒绝任务:拒绝任务是指当线程池里面的线程数量达到 maximumPoolSize 且 workQueue 队列已满的情况下被尝试添加进来的任务。
handler : 线程池对拒绝任务的处理策略。在 ThreadPoolExecutor 里面定义了 4 种 handler 策略,分别是
1. CallerRunsPolicy :这个策略重试添加当前的任务,他会自动重复调用 execute() 方法,直到成功。(可能会造成OOM)
2. AbortPolicy :对拒绝任务抛弃处理,并且抛出异常。
3. DiscardPolicy :对拒绝任务直接无声抛弃,没有异常信息。
4. DiscardOldestPolicy :对拒绝任务不抛弃,而是抛弃队列里面等待最久的一个线程,然后把拒绝任务加到队列。
一个任务通过 execute(Runnable) 方法被添加到线程池,任务就是一个 Runnable 类型的对象,任务的执行方法就是 Runnable 类型对象的 run() 方法。
当一个任务通过 execute(Runnable) 方法欲添加到线程池时,线程池采用的策略如下:
1. 如果此时线程池中的数量小于 corePoolSize ,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
2. 如果此时线程池中的数量等于 corePoolSize ,但是缓冲队列 workQueue 未满,那么任务被放入缓冲队列。
3. 如果此时线程池中的数量大于 corePoolSize ,缓冲队列 workQueue 满,并且线程池中的数量小于maximumPoolSize ,建新的线程来处理被添加的任务。
4. 如果此时线程池中的数量大于 corePoolSize ,缓冲队列 workQueue 满,并且线程池中的数量等于maximumPoolSize ,那么通过 handler 所指定的拒绝策略来处理此任务。
处理任务的优先级为:
核心线程 corePoolSize 、任务队列 workQueue 、最大线程 maximumPoolSize ,如果三者都满了,使用 handler处理被拒绝的任务。当线程池中的线程数量大于 corePoolSize 时,如果某线程空闲时间超过 keepAliveTime ,线程将被终止。这样,线程池可以动态的调整池中的线程数。
理解了上面关于 ThreadPoolExecutord 的介绍,应该就基本能了解它的一些使用,不过在 ThreadPoolExocutor里面有个关键的 Worker 类,所有的线程都要经过 Worker 的包装。这样才能够做到线程可以复用而无需重新创建线程。
同时 Executors 类里面有 newFixedThreadPool(),newCachedThreadPool() 等几个方法,实际上也是间接调用了ThreadPoolExocutor ,不过是传的不同的构造参数

各线程之间关系图:
ThreadPoolExecutor执行器中使用的是BlockingQueue阻塞队列
a)SynchronousQueue 并不是一个真正的队列,而是一种在线程之间进行移交的机制。要将一个元素放入SynchronousQueue中,必须有另一个线程正在等待接受这个元素。如果没有线程正在等待,并且线程池的当前大小小于最大值,那么ThreadPoolExecutor将会创建一个新的线程,否则会根据饱和策略拒绝掉这个任务。
b)LinkedBlockingQueue 基于链表的FIFO队列,默认队列大小为Integer.MAX_VALUE,因此是无界队列。当活跃线程等于corePoolSize时,新添加的任务都会被放入队列等待,因此maximumPoolSize就无效了。无界队列可以用来处理瞬时的高并发情况。
为什么叫它无界队列呢? 因为创建线程池时如果没有指定队列大小是使用下面的代码来初始化队列
public LinkedBlockingQueue() {
//默认是Integer的最大值
this(Integer.MAX_VALUE);
}
这样的话就会造成OOM,因为队列足够大,会导致堆内存满了,并且所有的任务都在等待
c)ArrayBlockingQueue 基于数组的FIFO队列,创建时必须指定大小。使用有界队列有助于防止资源耗尽。
其中默认使用LinkedBlockingQeque 无界队列实现的,既然讲到这个那么我们就来聊一聊
threadFactory:线程工厂,每当线程池需要创建一个线程时,都是通过线程工厂方法来完成的。默认的线程工厂方法将会创建一个新的、非守护的线程,并且不包含特殊的配置信息。在ThreadFactory中只定义了一个方法newThread,每当线程池需要创建一个新线程时都会调用这个方法。通常情况下我们都需要去使用自定义的线程工厂方法,自定义的线程工厂可以提供如下功能:
a)为线程取一个有意义的名字,便于后续排查问题。
b)为线程指定UncaughtExceptionHandler来处理线程执行过程中未被捕获的异常。
c)修改线程优先级或者守护状态。
所以说线程池的设置: 核心线程数量,最大线程数量,队列选择,拒绝策略都需要根据具体的业务场景来选择,否则可能会导致OOM或者一些意想不到的错误。
后续继续补。。。。。。。。。。


















 169万+
169万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











