






目录
参考资料
目标检测 YOLOv5 - 多机多卡训练_西西弗Sisyphus的博客-优快云博客_store = tcpstore(master_addr, master_port, world_s
pytorch分布式编程_qq_27172615的博客-优快云博客_master_addr
多机分布式
方式一:用多进程启动
代码:
def example(local_rank, node_rank, local_size, world_size):
print(f'local_rank: {local_rank}, node_rank:{node_rank}, local_size:{local_size}, world_size:{world_size}')
rank = local_rank + node_rank * local_size
print(f'rank:{rank}')
torch.cuda.set_device(local_rank)
dist.init_process_group("nccl",
init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=rank,
world_size=world_size)
def main():
local_size = 4
node_rank = 1
world_size = 4
print("local_size: %s" % local_size)
mp.spawn(example,
args=(node_rank, local_size, world_size,),
nprocs=local_size,
join=True)
if __name__ == "__main__":
main()打印结果:
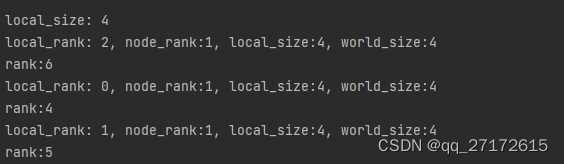
很明显dist.init_process_group,初始化是一个进程一个进程的初始化。
启动方式:
假设一共有两台机器(节点1和节点2),每个节点上有8张卡,节点1的IP地址为192.168.0.1 占用的端口22335(端口可以更换),启动的方式如下:
python python demo.py --world_size=16 --node_rank=0 --master_addr="192.168.0.1" --master_port=22335
>>> #节点2
>>>python python demo.py --world_size=16 --node_rank=1 --master_addr="192.168.0.1" --master_port=22335基础概念:
group: 进程组,大部分情况下,ddp的各个进程都是在一个group下面。
如何理解进程组?
dist.init_process_group 把进程添加到组里面。一般就一个组。注意一下rank的生成方式。
例如:2机8GPU。 local_rank = 8。然后根据local_rank创建8个进程, 进程第一个参数就表示 当前进程的编号(从0开始), node_rank表示第几号机器(第一台机器设置为0)
那么rank = local_rank[0_7] + node_rank(0) * local_size。
当node_rank = 0时, rank = 0, 1, 2, 3 ....7
当node_rank = 1 时, rank = 8, 9, 10...15
然后分别把它们放在进程组里面。注意,代码都在各自进程里面跑的。
MASTER_ADDR: 主机地址
MASTER_PORT:主机端口
node_rank 表示当前机器的序号从0开始
world_size:总的进程数量,一般一个进程占用一个GPU。
rank: 当前进程的序号,用于进程之间的通信,rank=0的主机为master节点。
local_rank:当前进程对应的gpu号。
方式二:利用launch 通过环境变量。
基础概念:
nproc_per_node 表示每台机器有多少张显卡
nnodes 表示一共有多少机器参与训练
代码:
import argparse
import os
import torch.distributed as dist
import torch
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 2))
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
args = parser.parse_args()
print(args.local_rank)
torch.cuda.set_device(args.local_rank)
def main():
parse_opt()
getpid_X = os.getpid()
print(f'当前进程id:{getpid_X}')
print(f'local_rannk:{LOCAL_RANK}, rannk:{RANK}, world_size:{WORLD_SIZE}')
if LOCAL_RANK != -1:
print(f'local_rank:{LOCAL_RANK}')
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
if __name__ == "__main__":
main()kaggle上 单机双卡:
!python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr="localhost" --master_port=12355 ../input/hellow1/dist_test1.py 
当使用单进程时
!python ../input/hellow1/dist_test1.py
和方式一,完全一样的,只不过屏蔽了多进程实现。
总结:
yolo出现大量这样的判断语句:
if LOCAL_RANK != -1:
if RANK in {-1, 0}:当使用单进程, 单机多卡模式 ,DP模式的时候。 RANK, LOCAL_RANK初始化就是-1.
但是使用多进程,多机多卡, DDP模式的时候。 这个时候不能把训练代码,当成单进程来看待,实际是多进程。一般的策略。主进程(0, -1)打印日志,统计数据,或者dataload切割的时候,主进程要负责数据的切割。

















 8759
8759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









