







 本文介绍两种提高Python元组使用效率的方法:通过命名索引和使用collections.namedtuple。这两种方法能够帮助开发者更直观地管理和访问元组中的数据。
本文介绍两种提高Python元组使用效率的方法:通过命名索引和使用collections.namedtuple。这两种方法能够帮助开发者更直观地管理和访问元组中的数据。
比如使用元祖存储信息时 如在信息系统中 使用固定格式存储个人信息
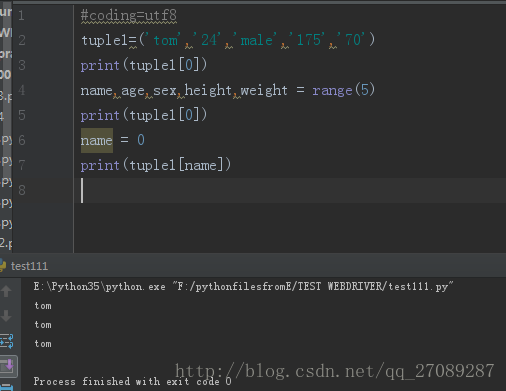
(姓名,年龄,性别,身高,体重)
tuple1=('tom','24','male','175','70')
此时若想读取关于这个学生的某一项信息数据时 则需使用索引(index),
就是这样 tuple[0],tuple[1],tuple[2]代码中含有大量的索引,调试程序不方便,也不清楚对应哪一项数据
现在有2种方法解决该问题 ,第一 给索引命名 。第二 使用标准库中的 collections.namedtuple 代替内置tuple。
方法1 给索引命名
如 name=0 ,age=1,sex=2,height=3,weight=4
当然更方便的是 使用 range 即 name,age,sex,height,weight=range(5)
这样调用时 使用tuple[name],tuple[age]这样即可。
输出结果是一样的 ,但是使用命名的方法 代码读起来一目了然。
方法二 使用标准库中collections.namedtuple代替内置tuple
namedtuple(类名,索引名称) 返回一个内置元组的子类,第一个参数为新创建的类的类名,第二个参数为对应索引的名称。
namedtuple('Student',['name','age','height','weight'])
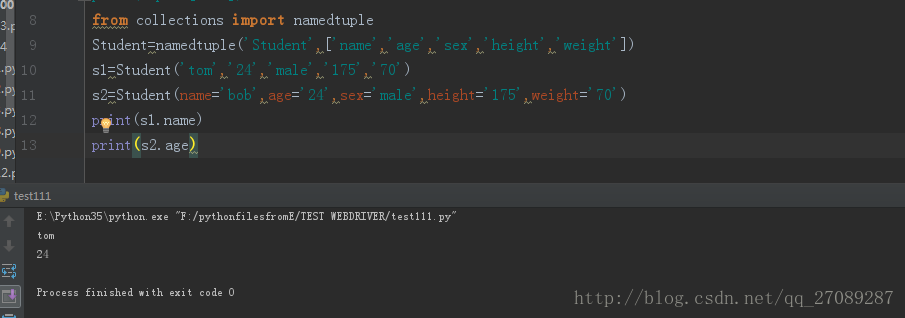
from collections import namedtuple
Student=namedtuple('Student',['name','age','sex','height','weight'])
s1=Student('tom','24','male','175','70') 使用位置传参
s2=Student(name='bob',age='24',sex='male',height='175',weight='70') 使用关键字传参
print(s1.name)
print(s2.age) 可以直接调用类中的属性 不在使用0-4的索引

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









