







实习的时候用到 scrapy,写了一个简单的 demo,建立好 scrapy 项目,写好 spider 以后
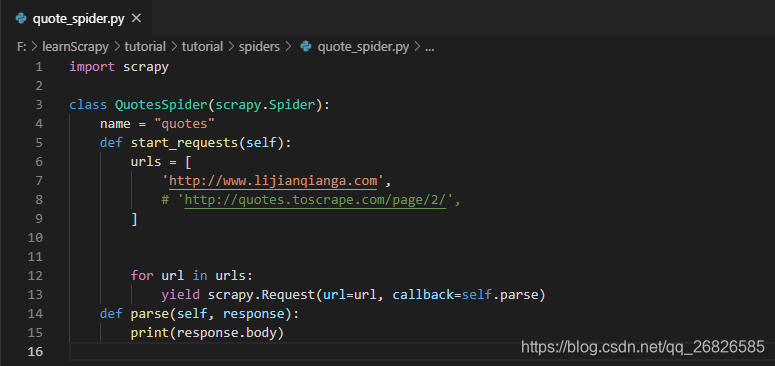
运行 scrapy crawl quotes 的时候,出现了 TCP 链接错误 [10060],试了很多方法,也用了网上的代理,问题还是没有解决

推测是由于公司内网的原因,请求不到目标 url ,这种目标主机[存在]找不到的问题解决方法肯定还是要使用代理,最好使用公司的代理翻出去去访问外网。
就去代理设置找了一下
在局域网里面,看到代理除了自动监测,还使用了自动配置脚本,于是就去这个地址请求了一下。
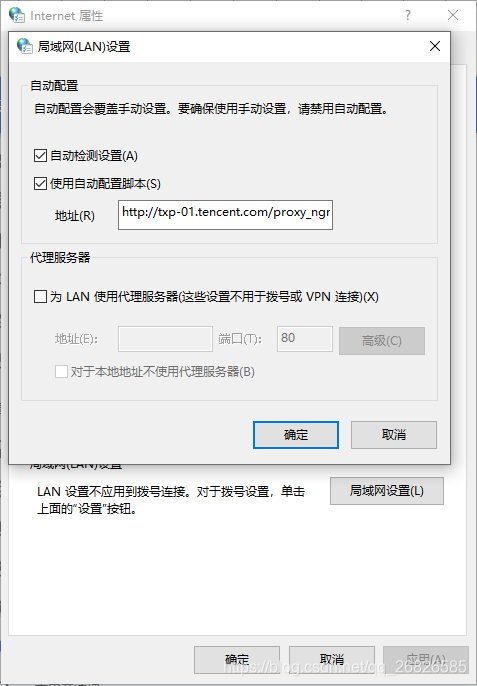
果然,发现了一些东西,在脚本里面找到了公司代理。于是添加到请求的 Request 对象里面。
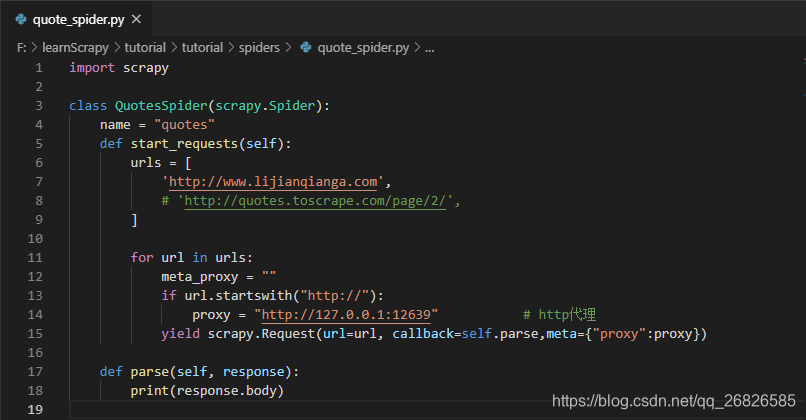
再试着运行了一下项目

可以看到 <GET 目标 url> 返回了 200(这里只是简单打印了 response 对象,没有打印具体信息)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











