







 超级会员免费看
超级会员免费看
 Crawler类在Scrapy中管理执行引擎和蜘蛛实例,通过SpiderLoader将字符串形式的蜘蛛名转化为蜘蛛类对象。在加载过程中,遍历SPIDER_MODULES配置的包,识别并加载所有继承自scrapy.Spider的类,判断条件包括是否为类、是否为Spider子类、模块名称匹配及是否存在name属性。创建Crawler对象时,通过SpiderLoader.load获取蜘蛛类实例。
Crawler类在Scrapy中管理执行引擎和蜘蛛实例,通过SpiderLoader将字符串形式的蜘蛛名转化为蜘蛛类对象。在加载过程中,遍历SPIDER_MODULES配置的包,识别并加载所有继承自scrapy.Spider的类,判断条件包括是否为类、是否为Spider子类、模块名称匹配及是否存在name属性。创建Crawler对象时,通过SpiderLoader.load获取蜘蛛类实例。
Crawler类是一个爬虫类,主要用来管理整个执行引擎ExecutionEngine类和蜘蛛类实例化。在分析这个类之前,我们先来看一下怎么样调用这个类的,代码如下:

在调用_create_crawler函数时传送的参数spidercls是一个字符串,它的值是quotes。这时候需要把蜘蛛类中的名称转换为蜘蛛类的对象,这个过程是怎么样实现呢?显然就是使用蜘蛛类的加载类,也就是这里的spider_loader对象来实现,因此这里调用了load方法。所以传送给Crawler类的参数spidercls已经是一个蜘蛛类的对象。
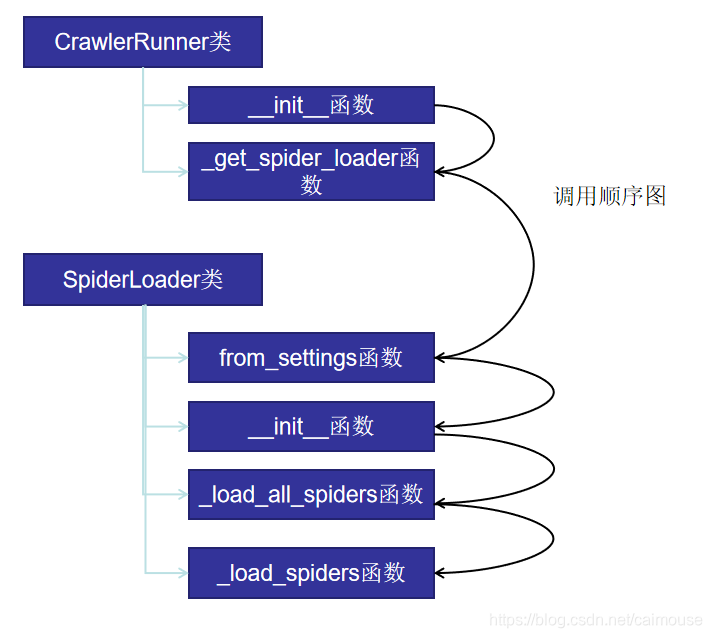
当你去查看load方法时,发现它非常简单,只是从字典里取得对应的蜘蛛类对象。其实它是在SpiderLoader的构造函数时就已经把所有蜘蛛类加载到内存里。大体调用过程是这样:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











