







提到数据库索引,我想你并不陌生,在日常工作中会经常接触到。比如某一个SQL查询比较慢,分析完原因之后,你可能就会说“给某个字段加个索引吧”之类的解决方案。但到底什么是索引,索引又是如何工作的呢?今天就让我们一起来聊聊这个话题吧。
数据库索引的内容比较多,我分成了上下两篇文章。索引是数据库系统里面最重要的概念之一,所以我希望你能够耐心看完。在后面的实战文章中,我也会经常引用这两篇文章中提到的知识点,加深你对数据库索引的理解。
一句话简单来说,索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。一本500页的书,如果你想快速找到其中的某一个知识点,在不借助目录的情况下,那我估计你可得找一会儿。同样,对于数据库的表而言,索引其实就是它的“目录”。
索引的常见模型
索引的出现是为了提高查询效率,但是实现索引的方式却有很多种,所以这里也就引入了索引模型的概念。可以用于提高读写效率的数据结构很多,这里我先给你介绍三种常见、也比较简单的数据结构,它们分别是哈希表、有序数组和搜索树。下面我主要从使用的角度,为你简单分析一下这三种模型的区别。
哈希表是一种以键-值(key-value)存储数据的结构,我们只要输入待查找的值即key,就可以找到其对应的值即Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把key换算成一个确定的位置,然后把value放在数组的这个位置。
不可避免地,多个key值经过哈希函数的换算,会出现同一个值的情况。处理这种情况的一种方法是,拉出一个链表。
假设,你现在维护着一个身份证信息和姓名的表,需要根据身份证号查找对应的名字,这时对应的哈希索引的示意图如下所示:
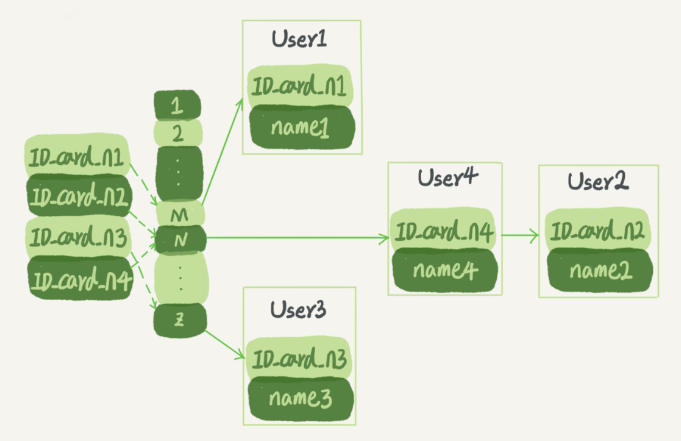
图中,User2和User4根据身份证号算出来的值都是N,但没关系,后面还跟了一个链表。假设,这时候你要查ID_card_n2对应的名字是什么,处理步骤就是:首先,将ID_card_n2通过哈希函数算出N;然后,按顺序遍历,找到User2。
需要注意的是,图中四个ID_card_n的值并不是递增的,这样做的好处是增加新的User时速度会很快,只需要往后追加。但缺点是,因为不是有序的,所以哈希索引做区间查询的速度是很慢的。
你可以设想下,如果你现在要找身份证号在[ID_card_X, ID_card_Y]这个区间的所有用户,就必须全部扫描一遍了。
所以,哈希表这种结构适用于只有等值查询的场景,比如Memcached及其他一些NoSQL引擎。
而有序数组在等值查询和范围查询场景中的性能就都非常优秀。还是上面这个根据身份证号查名字的例子,如果我们使用有序数组来实现的话,示意图如下所示:
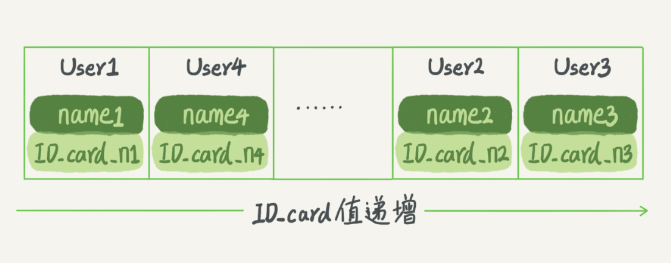
这里我们假设身份证号没有重复,这个数组就是按照身份证号递增的顺序保存的。这时候如果你要查ID_card_n2对应的名字,用二分法就可以快速得
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











