







一条查询语句的执行过程一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎。
那么,一条更新语句的执行流程又是怎样的呢?
之前你可能经常听DBA同事说,MySQL可以恢复到半个月内任意一秒的状态,惊叹的同时,你是不是心中也会不免会好奇,这是怎样做到的呢?
我们还是从一个表的一条更新语句说起,下面是这个表的创建语句,这个表有一个主键ID和一个整型字段c:
create table T(ID int primary key, c int);
如果要将ID=2这一行的值加1,SQL语句就会这么写:
update T set c=c+1 where ID=2;
MySQL的逻辑架构图如下,首先,可以确定的说,查询语句的那一套流程,更新语句也是同样会走一遍。
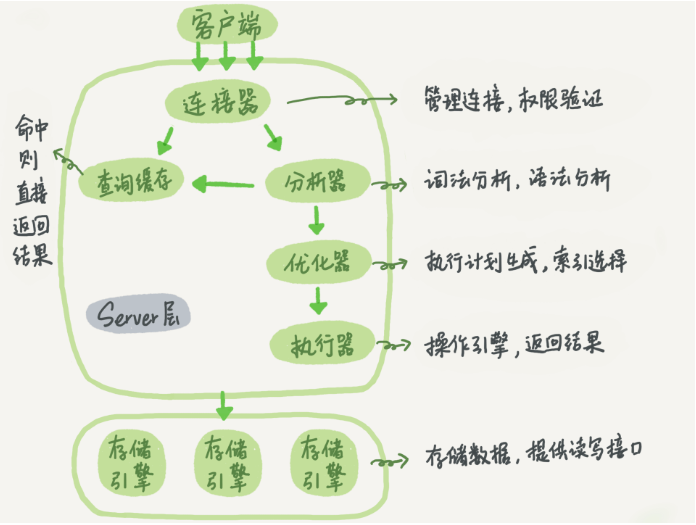
你执行语句前要先连接数据库,这是连接器的工作。
在一个表上有更新的时候,跟这个表有关的查询缓存会失效,所以这条语句就会把表T上所有缓存结果都清空。这也就是我们一般不建议使用查询缓存的原因。
接下来,分析器会通过词法和语法解析知道这是一条更新语句。优化器决定要使用ID这个索引。然后,执行器负责具体执行,找到这一行,然后更新。
与查询流程不一样的是,更新流程还涉及两个重要的日志模块,它们正是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











