









 博主分享了Fast.ai课程的第三周笔记,涵盖多标签预测、CamVid图像分割、BIWI头部姿势回归和IMDB文本分类等内容。讨论了预训练模型在不同通道数据上的应用,强调了progressive resizing训练策略和混合精度训练的重要性。
博主分享了Fast.ai课程的第三周笔记,涵盖多标签预测、CamVid图像分割、BIWI头部姿势回归和IMDB文本分类等内容。讨论了预训练模型在不同通道数据上的应用,强调了progressive resizing训练策略和混合精度训练的重要性。
注: 此博客仅为博主复习之用,省去了大量细节和博主已在其他地方做记录的知识点;有兴趣学习fast.ai课程的同学建议扎实学习Howard的视频以及Forum中的资源!共勉!
2019/6/28
课前热身
介绍了Andrew Ng的ML课程:内容部分虽然稍微过时,但大部分还是非常excellent,其采用自底向上模式,结合fast.ai自顶向下模式,可以更好地学习!
combine bottom-up style and top-down style and meet somewhere in the middle.
当然Howard也介绍了自己的ML课程,约为DL课程的两倍时长;(涉及很多基础知识)
学习建议:All these courses together if you want really dig deeply into the material,DO ALL OF THEM. A lot of people who have had end up saying: oh I got more out of each one by doing the whole lot。
Production
Howard提供了部署web app的简单方案!前端javascript,后端数据JSON;链接在课程导航页左侧的production菜单中;
show works!
值得去Forum一一回看,会给你很多启发!!! (不一定视频,有GitHub详细笔记!)
- What car!

- 识别视频中的人物表情 or 手势
查找Forum和资料,弄懂如何实现图片到视频的跨越 - yourcityfrom
通过卫星图像识别出是哪个城市! - 识别面部表情的类别–结合2013年一篇论文
| Multi-label prediction
dataset: Planet Amazon dataset (satellite images), from Kaggle
很多人已经在深度学习中使用satellite images, but only scratching the surface!
Get dataset from Kaggle
按照notebook教程做即可
Create DataBunch - use data block API
DataBunch(train_dl: DataLoader(datasets(), batchsize = 8), valid_dl: 同) : 即一层一层作为参数传入!
注: fastai 所有文档 都是notebook,可以clone下来在Jupyter上练习!具体怎么打开可以回看lesson3-29`
----------------up to 56` min
| Image Segmentation with CamVid
注意点:调整图片时,mask也要相应调整,否则不匹配了!
训练方法: progressive resizing
从size较少的数据集先训练(更快更容易),然后transfer learning,逐步增大图片的size; 但是目前还没有准确的理论指出每个level的大小应该设为多少,Howard经验:
低于64x64往往没有帮助
fit_one_cycle()原理
简单来说,就是让lr_rate先变大变小!
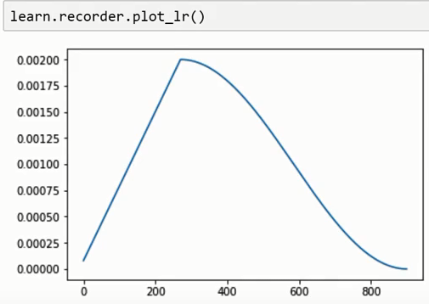
Loss的形态类似于下图,
变大的目的:helping the model to explore the whole function surface and try and find areas where both the loss is low and also it`s not bumpy! 防止困在某个局部最优处!(所以传入fit_one_cycle()的其实是max learning rate)

所以如果用fit_one_cycle(),Loss的变化会如下,也就是说,如果你发现:
if you find that it’s just getting a little bit worse and then it gets a lot better, you’ve found a really good maximum learning rate.
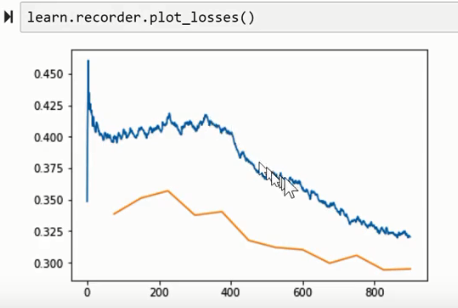
那如果你发现:Loss一直下降,可以稍微上调一下学习率
so if you find that Loss is kind of always going down, particularly after you unfreeze, that suggests you can probably bump your learning rate up a little bit.
Because you really want to see this kind of shape! It’s going to train faster and generalize better.
Howard: 知道这个理论和真正运用的差距,你需要看大量这种情况的变化图!
所以每次训练完,看Loss的变化情况,good results怎样,bad results怎样,不但调整learning rate 和epochs,观察图像变化!
Mixed precision training
如果训练时遇到内存超限的问题,可以尝试使用16bit精度的浮点数进行训练!
means: Instead of using single-precision floating-point numbers, you can do most of the calculations in your model with half-precision floating-point numbers.
So, 16 bits instead of 32 bits. 因为比较新,所以你可能需要最新的硬件(CUDA drivers, etc)才行,fastai提供了接口,只需在create_learner的末尾加上to_fp16()即可
----------------up to 94` min
| Regression with BIWI head pose dataset
【Image Regression Model: find the center of the face,two float numbers】
Regression: any kind of model where your output is some continuous number or set of numbers.
----------------up to 101` min
| NLP quick version - IMDB
第一个学生提问: 没太听懂,回看!
----------------up to 110` min
最后提到了Michael Nielsen的书 《Neural Network and Deep Learning》 中的动画:
If you have enough little matrix multiplications followed by sigmoid(ReLU), you can create arbitrary shapes. Combinations of linear functions and nonlinearities can create arbitrary shapes
Universal approximation theory: If you have stacks of linear functions and nonlinearities, you can approximate any function arbitrarily, closely.
之前这本书看到一半扔下来,看来要捡起来才行!里面有很多细节值得一看!
Question: 如果图片数据是2 channel或者4channel的,如何使用3channel的 pretrained model?
Howard表示之后会在fastai中加入此功能;
2 channel的数据: there is few things you can do, but basically you can create a third channel as either being all zeros or being the average of the other two other channels.
4 channel的数据: 当然不能丢弃 4th channel的数据, 所以只能修改你的model,简单来说就是给weight tensor多加一维,赋值为0或随机值;后面课程会细讲!

















 2497
2497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









