





1.访问ollama.com模型官网,下载安装对应的客户端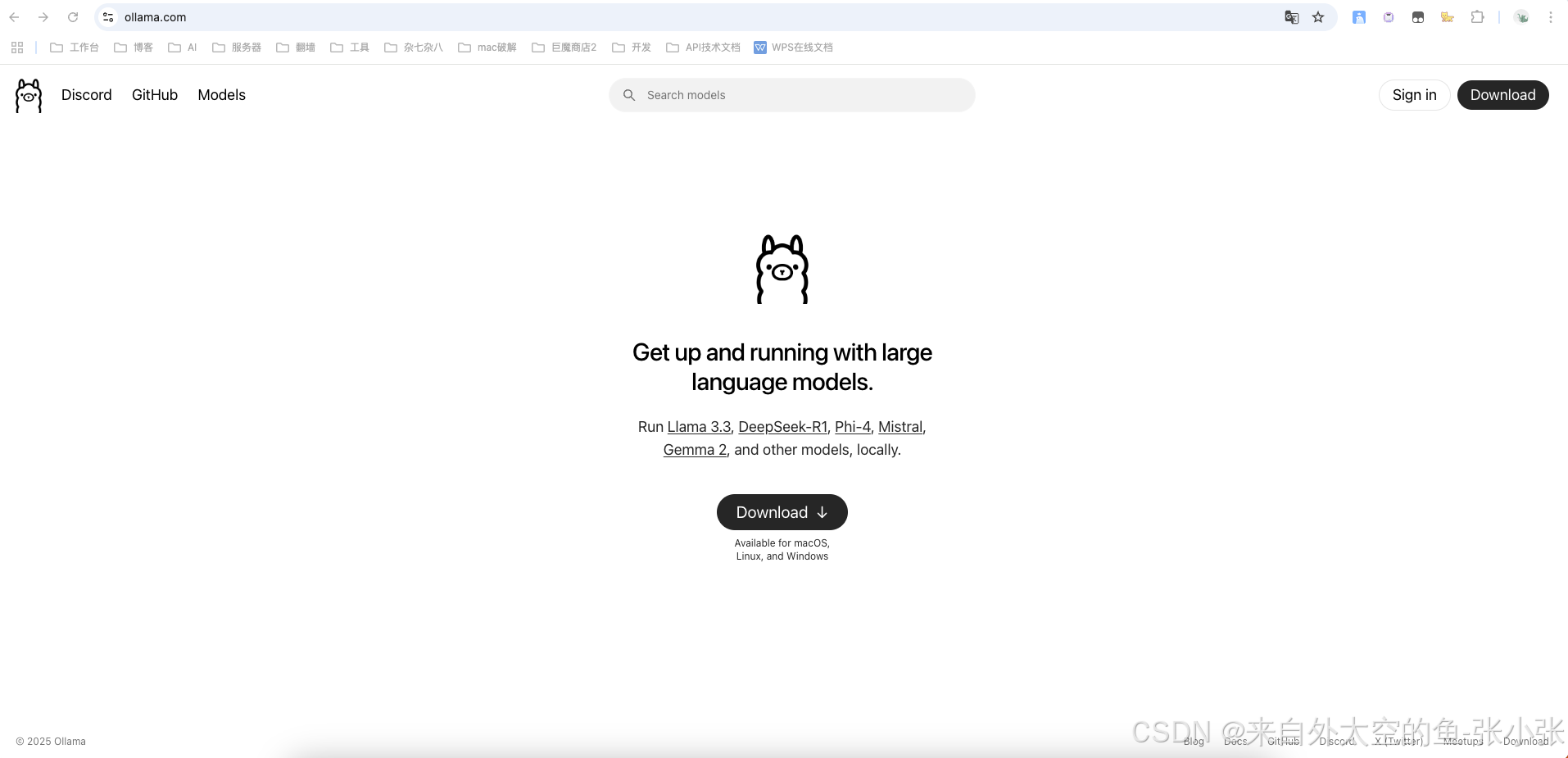
2.安装好客户端后到ollama官网去搜索对应的模型,这里选择deepseek-r1模型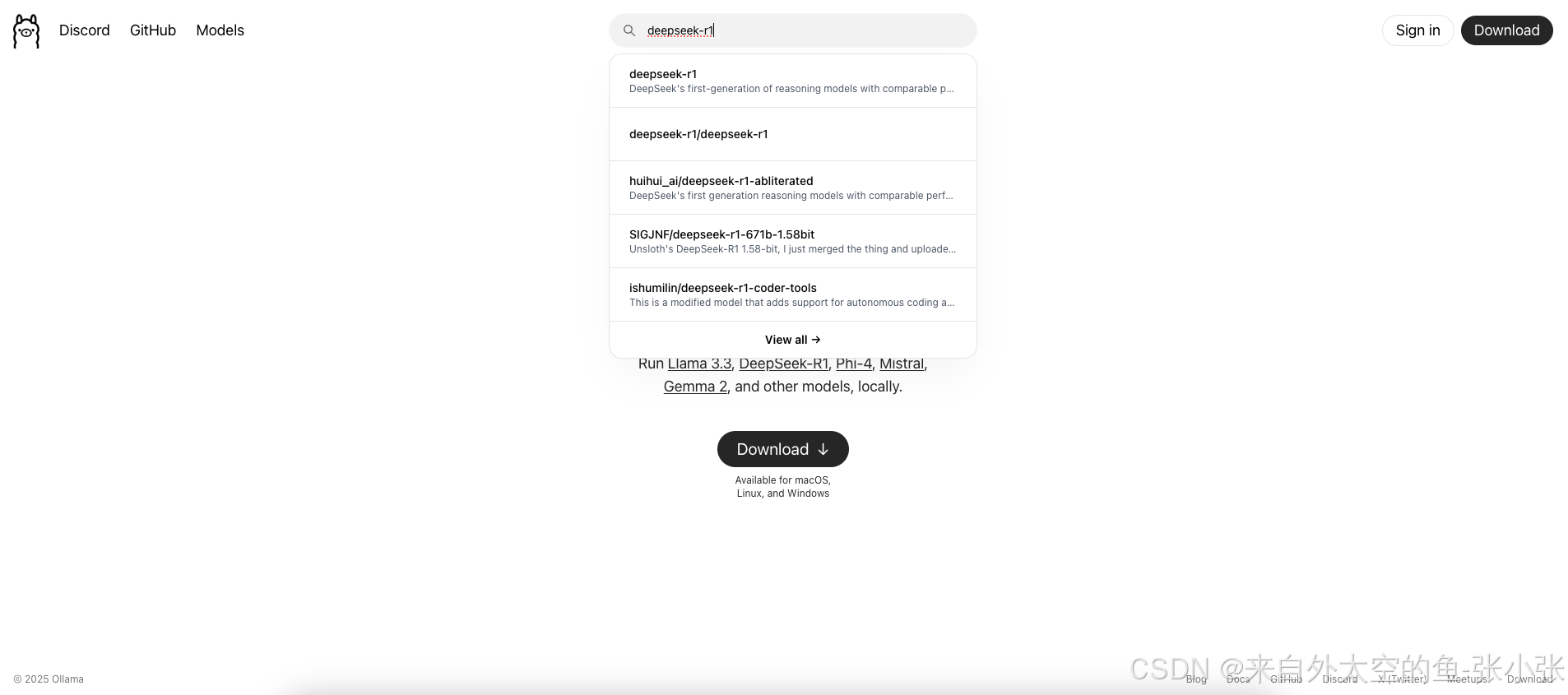 3.选择模型大小,复制下载的命令,运行开始下载
3.选择模型大小,复制下载的命令,运行开始下载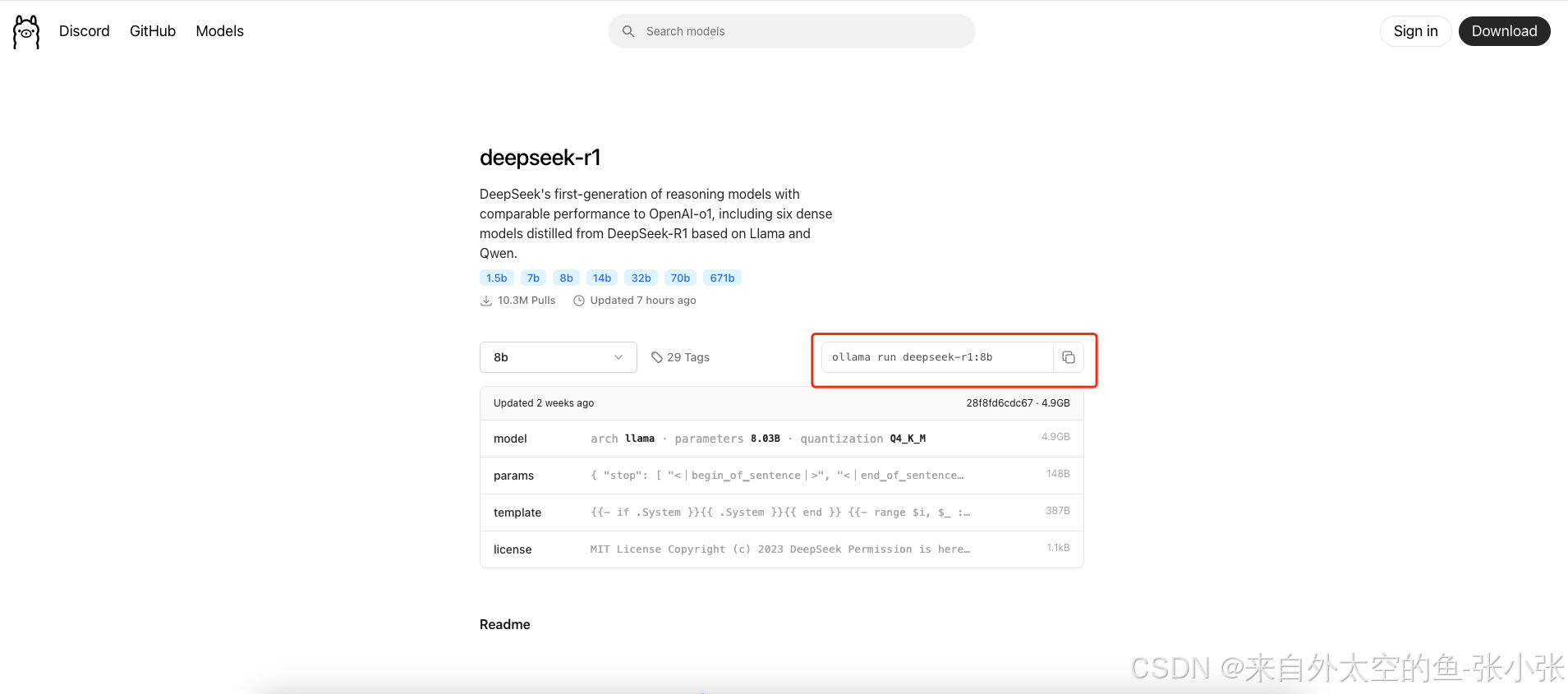
4.安装完成后运行ollama list查看本地模型,出现模型名称代表下载成功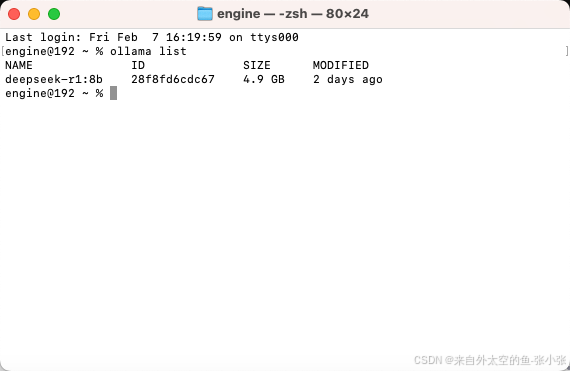
5.安装可视化界面平台 也可以启动网页版
Chatbox AI官网
6.配置Chatbox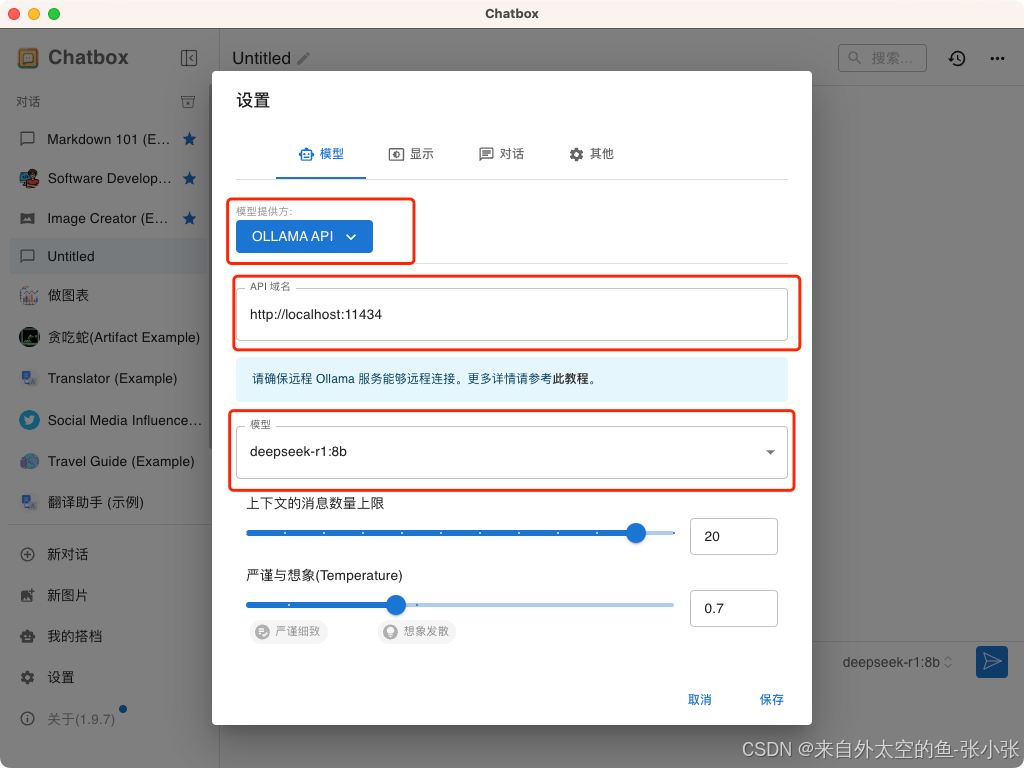

1.访问ollama.com模型官网,下载安装对应的客户端
2.安装好客户端后到ollama官网去搜索对应的模型,这里选择deepseek-r1模型3.选择模型大小,复制下载的命令,运行开始下载
4.安装完成后运行ollama list查看本地模型,出现模型名称代表下载成功
5.安装可视化界面平台 也可以启动网页版
Chatbox AI官网
6.配置Chatbox
 3829
3829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























