







 本文详细介绍了使用TensorFlow框架下的YoloV3进行目标检测的数据准备、训练及测试过程,包括数据集的组织方式、配置文件的修改、训练参数的调整以及测试阶段的注意事项。
本文详细介绍了使用TensorFlow框架下的YoloV3进行目标检测的数据准备、训练及测试过程,包括数据集的组织方式、配置文件的修改、训练参数的调整以及测试阶段的注意事项。
数据准备:
一般我习惯把数据这样备份:
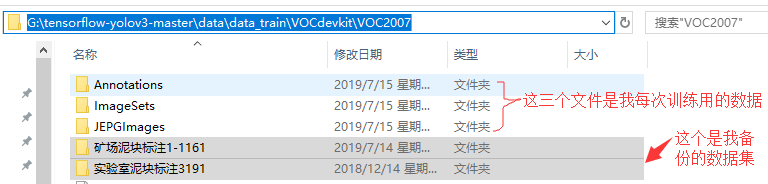
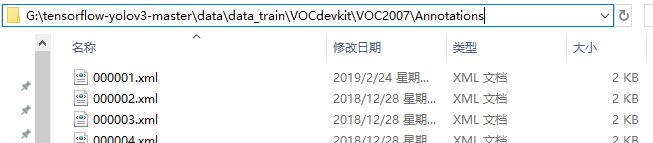
把xml放到这个文件夹里:
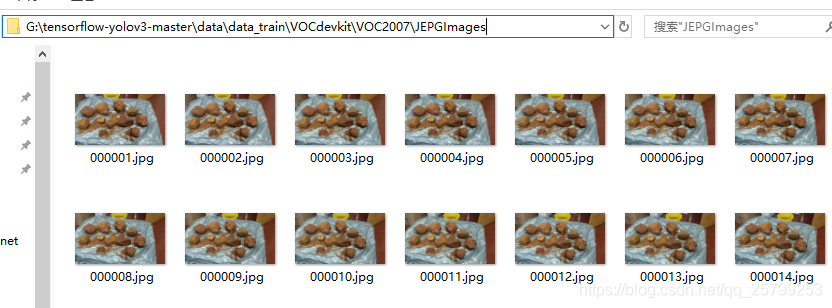
把jpg图像放到这个文件夹里:
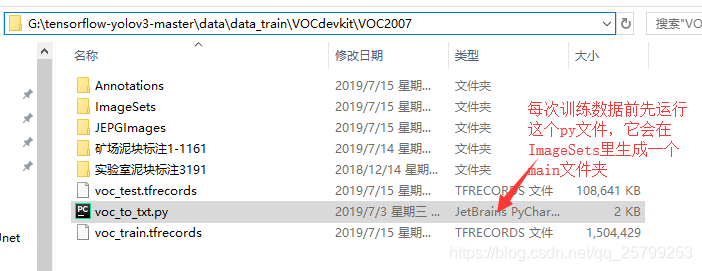
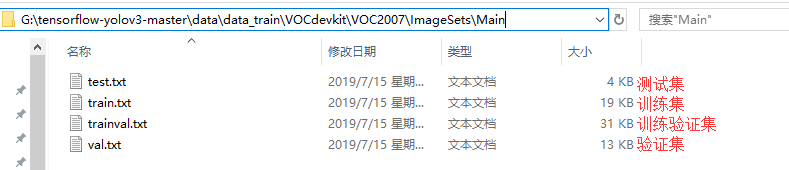
打开ImageSets里的Main文件
打开tensorflow-yolov3/scripts/voc_annotations.py文件
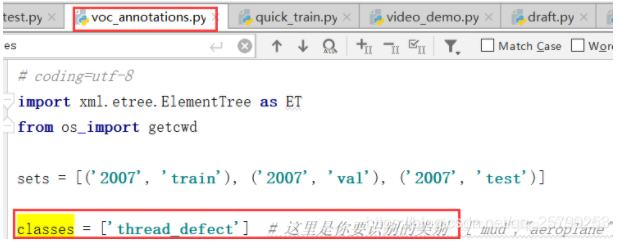
把classes变量里的内容改为自己标注所用到的所有标签。
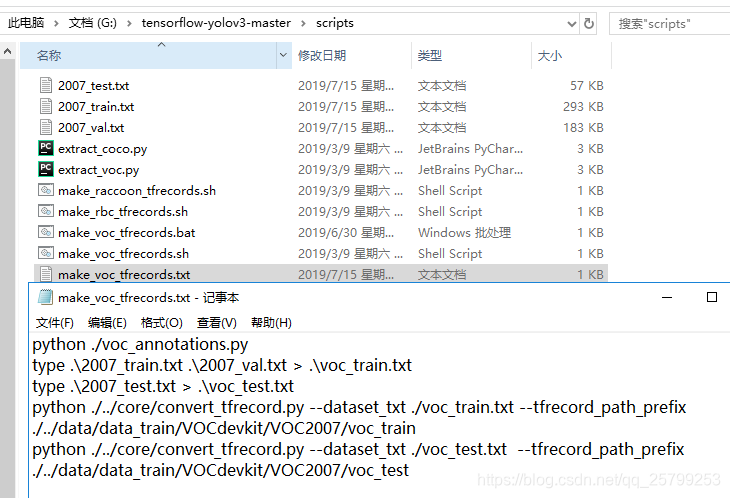
然后进入这个路径:G:\tensorflow-yolov3-master\scripts
打开一个叫make_voc_tfrecords.txt的文件:
打开anaconda prompt:
激活这个环境:
activate tensorflow-gpu-1.10.0anaconda prompt控制台要用cd命令进入scripts这个目录,如果照我这里,如:
cd G:\tensorflow-yolov3-master\scripts把上面make_voc_tfrecords.txt里的命令一行一行地输入anaconda prompt控制台,来运行。
之后在这里会生成两个文件voc_test.txt和voc_train.txt,如果原来有这两个文件则会被覆盖。
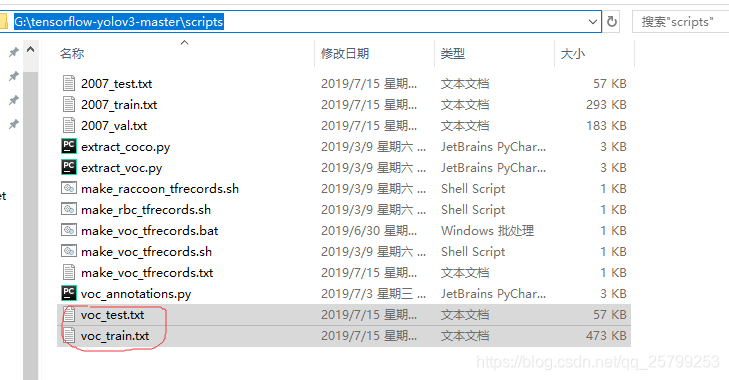
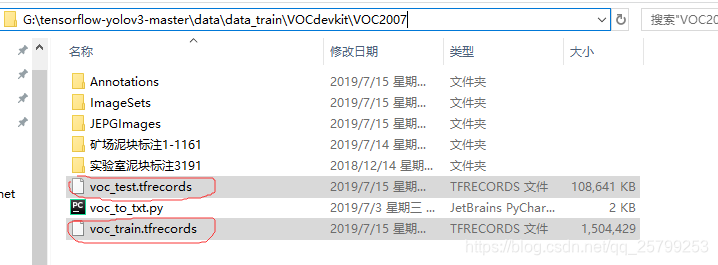
然后在这里也会生成两个文件:voc_test.tfrecords和voc_train.tfrecords,原来的会被覆盖。
训练:
然后运行这个文件开始训练:tensorflow-yolov3-master/train.py
train.py的训练参数在这里:
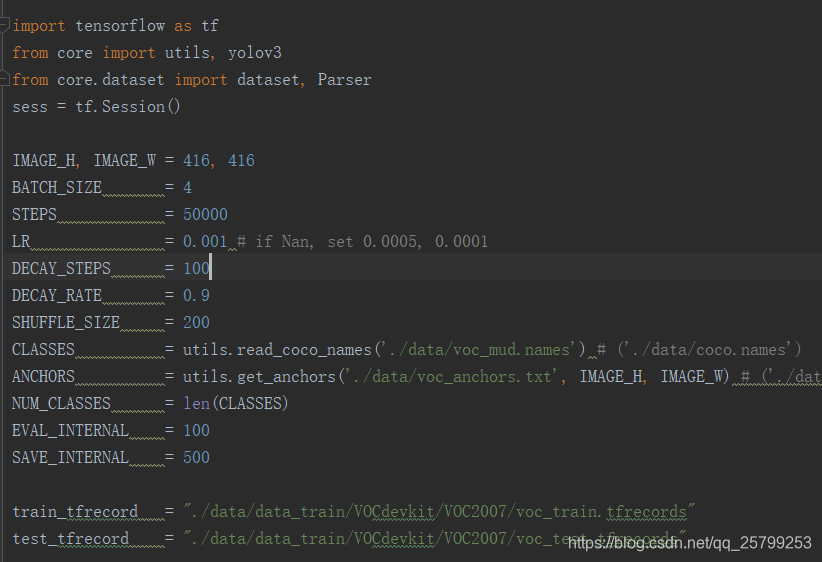
1. BATCH_SIZE是总共训练包的个数,但你训练时出现显存不够(Out of range),或是蓝屏、程序崩溃的时候可以尝试把这个参数调小。
2. STEPS是迭代次数的多少,低则识别率低,反之则否。
测试:
可以用图形界面来测试,运行这个文件:tensorflow-yolov3-master/Main_Dialog.py
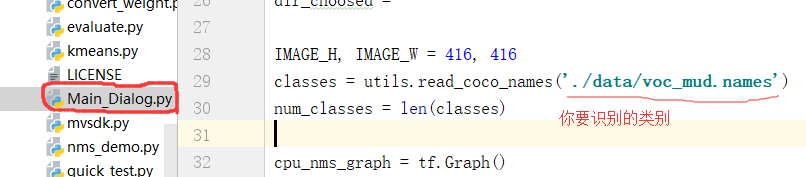
如果你不准备识别泥块,要识别你的类别的话在这里转换识别目标的类别:
ERROR1:无法Import mvsdk模块,你需要去这个网址下载mindvision驱动程序(尽管你没用到工业相机,但是我懒得改代码了):
http://www.mindvision.com.cn/rjxz/list_12.aspx?lcid=138

安装后即可。

















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









