









 超级会员免费看
超级会员免费看
从文本中构建知识图谱一直是一个引人入胜的研究领域。随着大型语言模型(LLM)的出现,这一领域获得了更多主流关注。然而,大型语言模型的成本可能相当高昂。另一种方法是对较小的模型进行微调,这种方法得到了学术研究的支持,并产生了更有效的解决方案。今天,我们将探讨罗马萨皮恩扎大学(Sapienza University of Rome)的 NLP 小组开发的 Relik,一个用于运行快速、轻量级信息提取模型的框架。
没有 LLM 的典型信息提取管道如下:
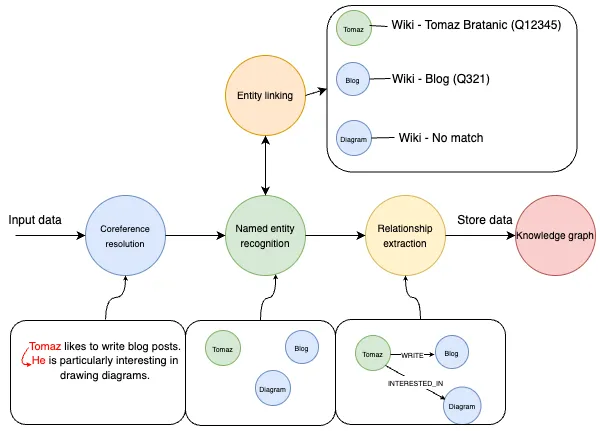
图片说明了信息提取流水线,从输入数据开始,输入数据包括提及 “托马兹喜欢写博客文章 ”的文本。他对画图特别感兴趣"。提取过程从核心参照解析开始,将 “Tomaz ”和 “He ”识别为同一个实体。然后,命名实体识别 (NER) 识别出 “Tomaz”、“Blog ”和 “Diagram ”等实体。
实体链接是 NER 之后的一个过程,将识别出的实体映射到数据库或知识库中的相应条目。例如,“Tomaz ”链接到 “Tomaz Bratanic (Q12345)”,“Blog ”链接到 “Blog (Q321)”,但 “Diagram ”在知识库中没有匹配项。
关系提取是系统识别和提取已识

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











