







 本文探讨了RAdam和LookAhead优化器的互补性,并介绍了将两者结合的Ranger优化器。RAdam通过动态整流器提供预热过程,而LookAhead通过维护两套权重进行探索与稳定性的平衡。Ranger优化器在实验中显示了出色的稳定性和准确性,尤其是在ImageNet上的20个epoch训练中超越了FastAI的榜首结果。
本文探讨了RAdam和LookAhead优化器的互补性,并介绍了将两者结合的Ranger优化器。RAdam通过动态整流器提供预热过程,而LookAhead通过维护两套权重进行探索与稳定性的平衡。Ranger优化器在实验中显示了出色的稳定性和准确性,尤其是在ImageNet上的20个epoch训练中超越了FastAI的榜首结果。
把RAdam和LookAhead合二为一
2019年08月28日 09:58:57 床长 阅读数 65更多
分类专栏: 人工智能
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.youkuaiyun.com/jiangjunshow/article/details/100113434
朋友们,我是床长! 如需转载请标明出处:http://blog.youkuaiyun.com/jiangjunshow
RAdam 和 LookAhead 有可能形成互补吗?
毋庸置疑,在训练的初始阶段,RAdam 能为优化器提供最棒的基础值。借助一个动态整流器,RAdam 可以根据变差大小来调整 Adam 优化器中的自适应动量,并且可以提供一个高效的自动预热过程;这些都可以针对当前的数据集运行,从而为深度神经网络的训练提供一个扎实的开头。
LookAhead 的设计得益于对神经网络损失空间理解的最新进展,为整个训练过程的鲁棒、稳定探索都提供了突破性的改进。用 LookAhead 论文作者们自己的话说,LookAhead「减少了超参数调节的工作量」,同时「在许多不同的深度学习任务中都有更快的收敛速度、最小的计算开销」。还有,「我们通过实验表明,LookAhead 可以显著提高 SGD 和 Adam 的表现,即便是用默认的超参数直接在 ImageNet、CIFAR-10/100、机器翻译任务以及 Penn Treebank 上运行」。
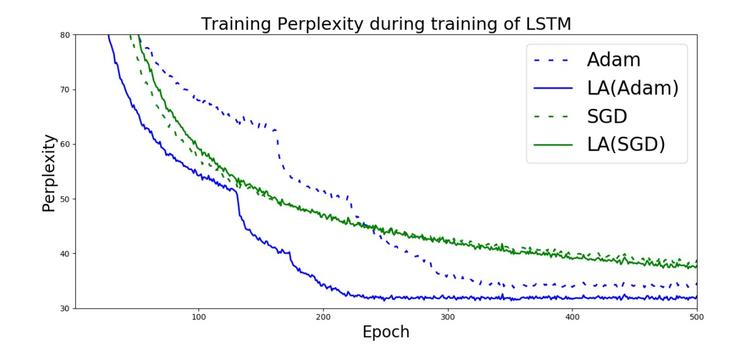
那么,既然两种方法是从不同的角度对深度学习的优化过程提供了改进,我们全完可以猜测两者合并以后可以起到协同作用,带来更棒的结果;也许这就是我们在寻找更稳定更鲁棒的优化方法之路上的最新一站。
在下文中,作者将会在 RAdam 介绍的基础上解释 LookAhead 的原理,以及如何把 RAdam 和 LookAhead 集成到同一个优化器(Ranger)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









