









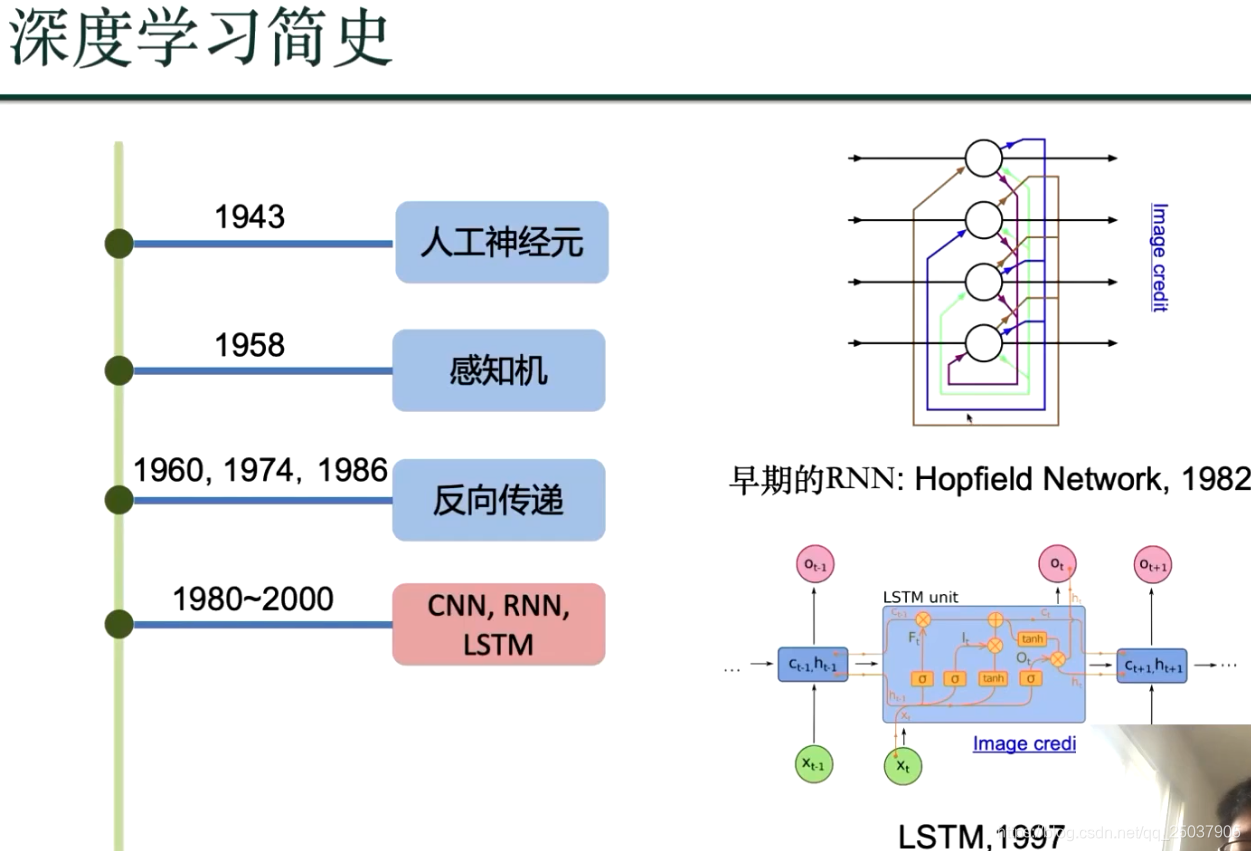

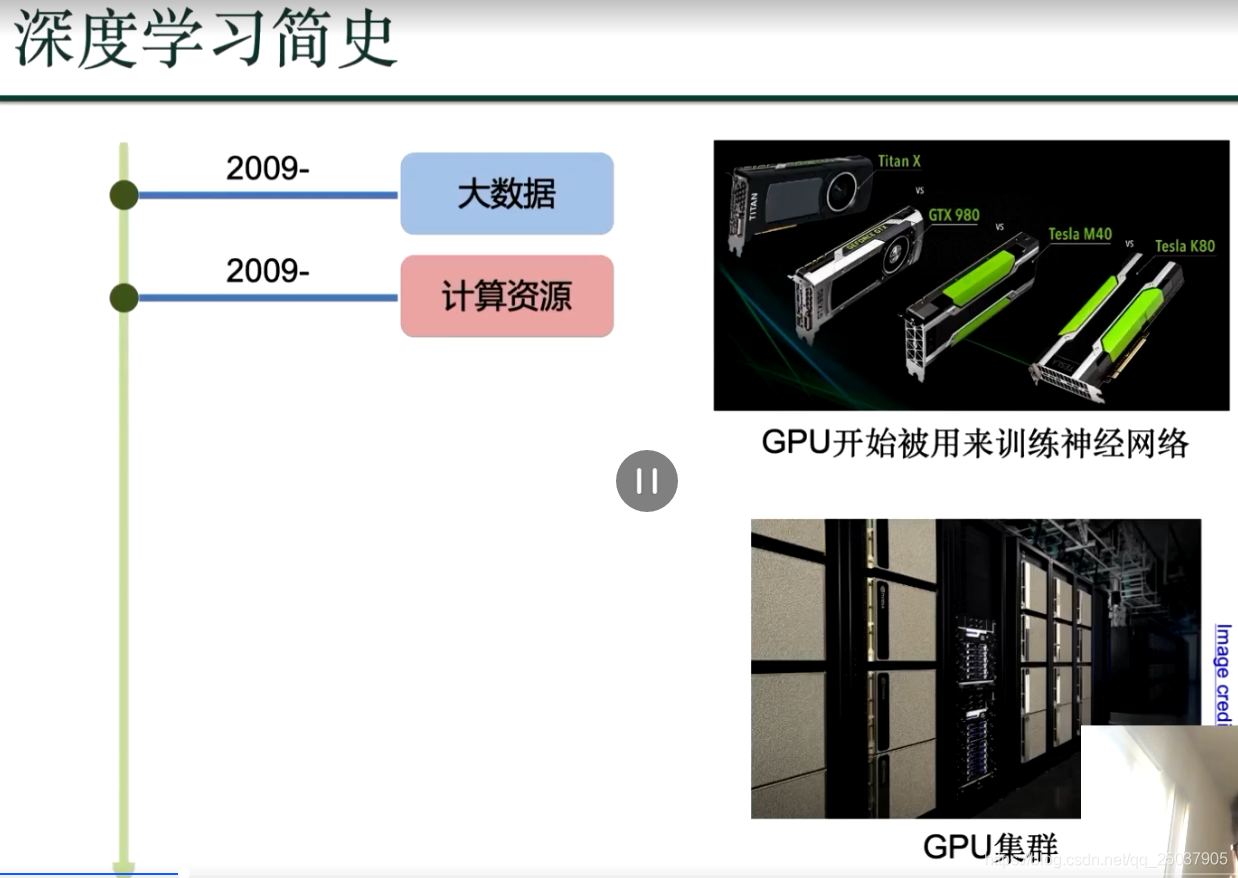
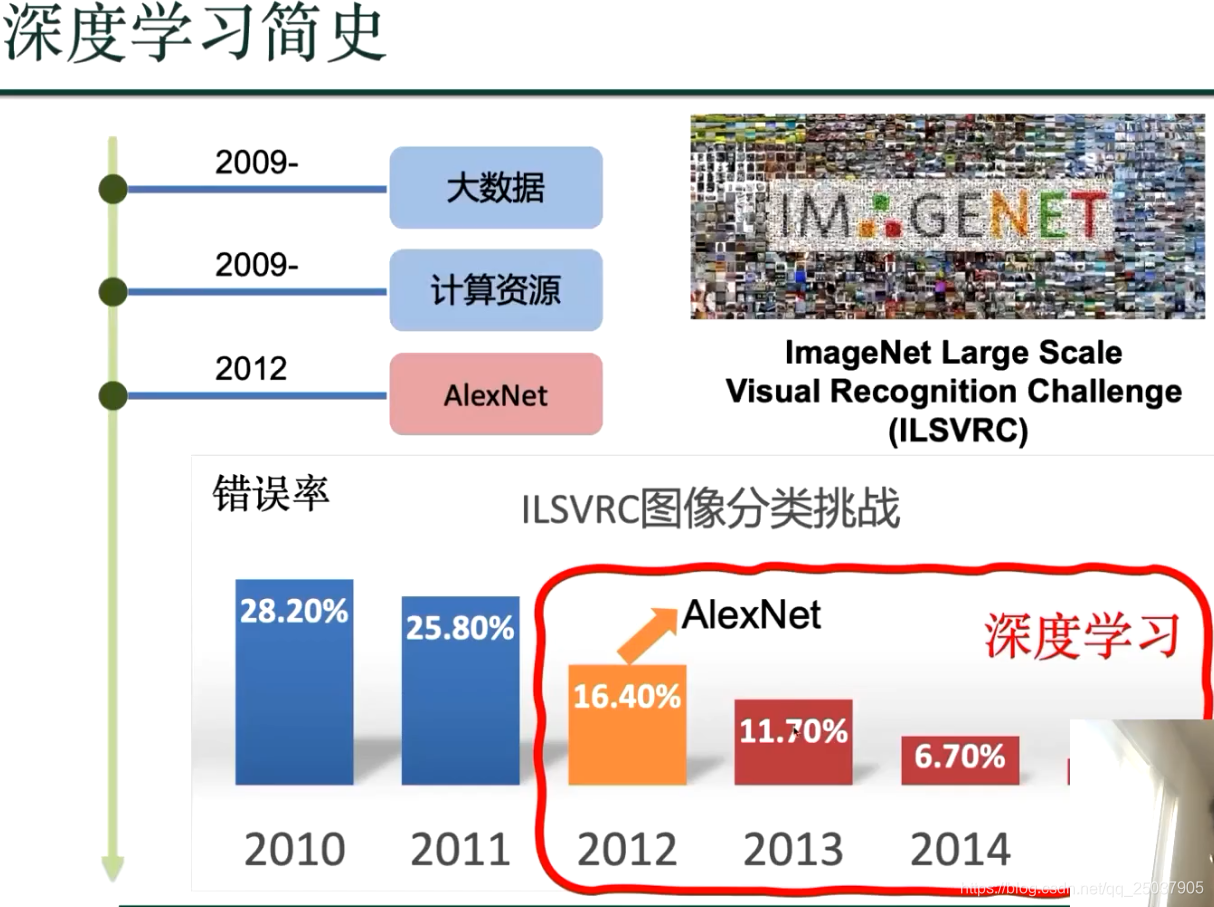
以下到文末都是前馈神经网络知识: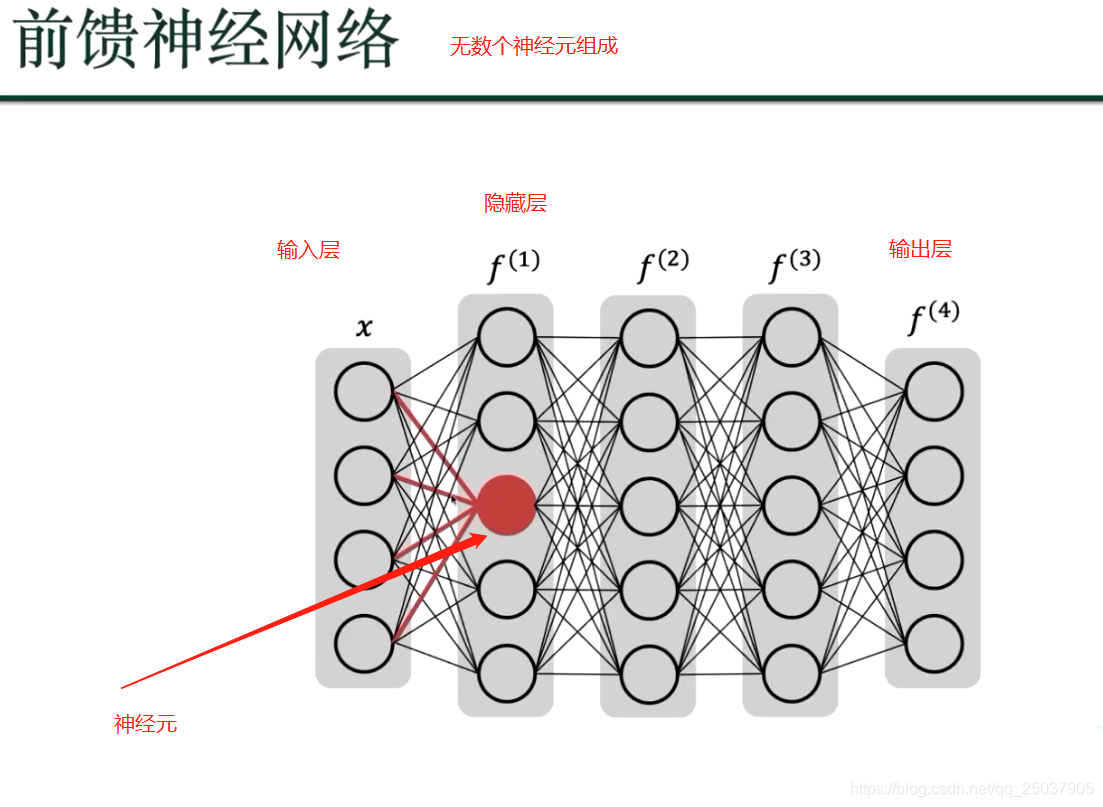
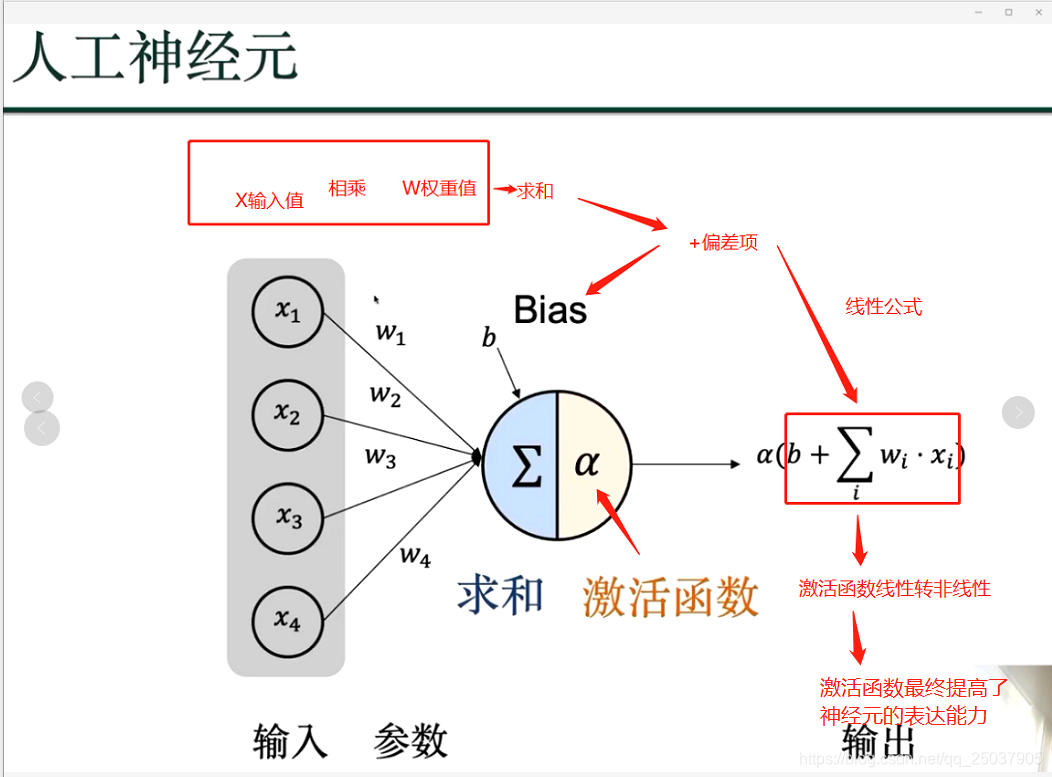
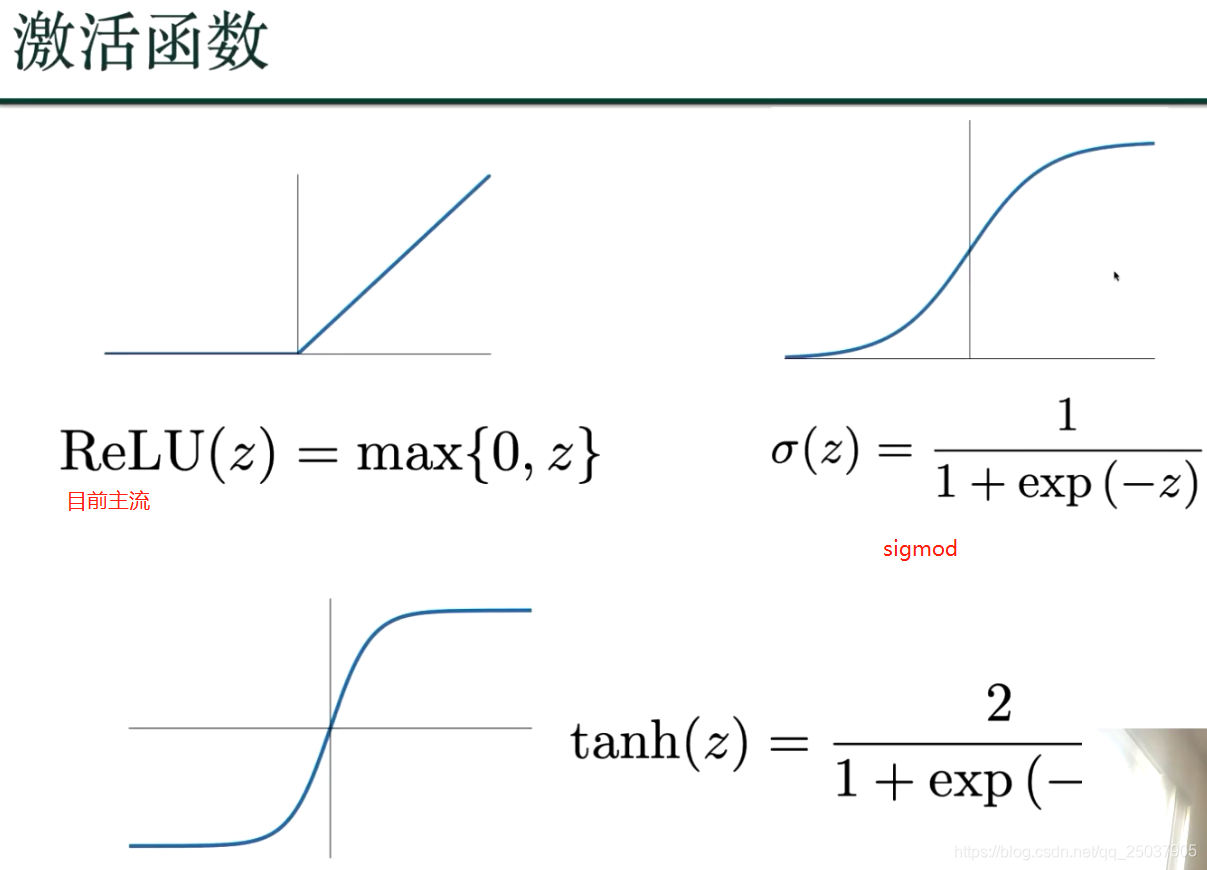
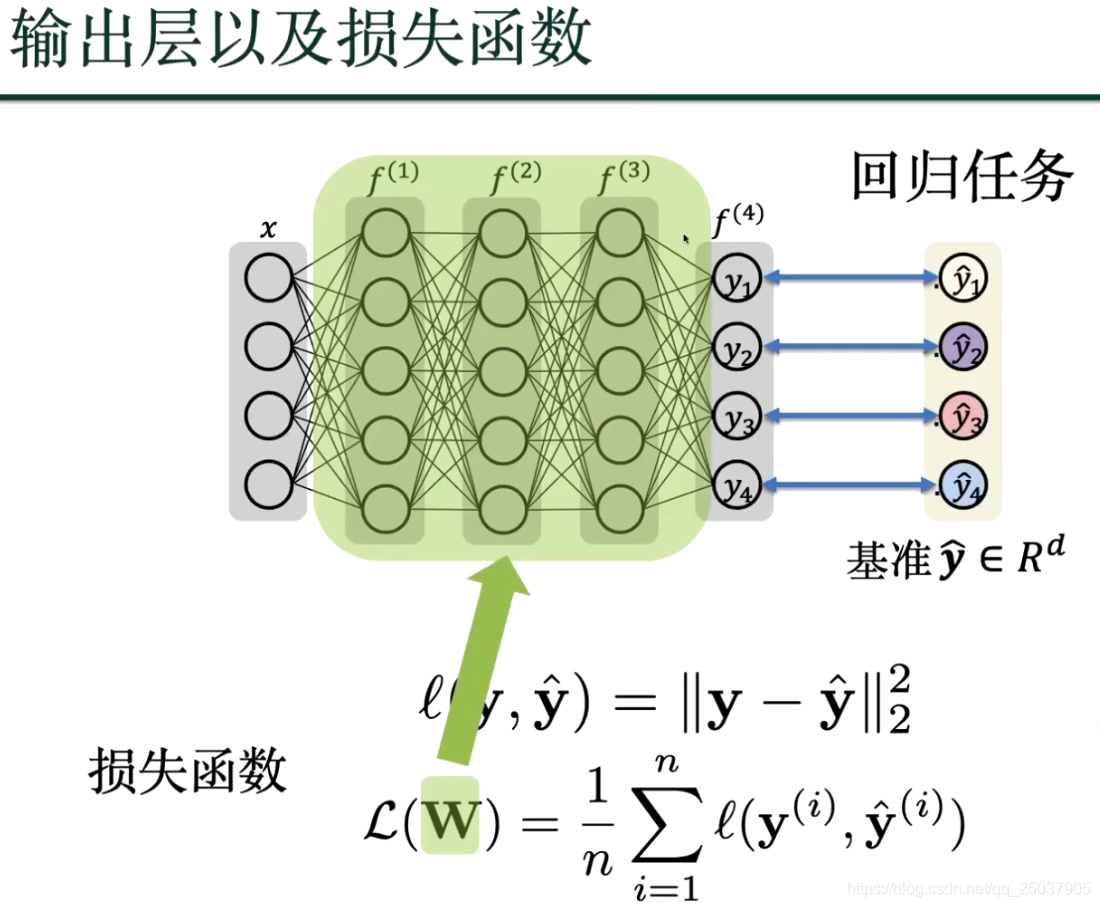
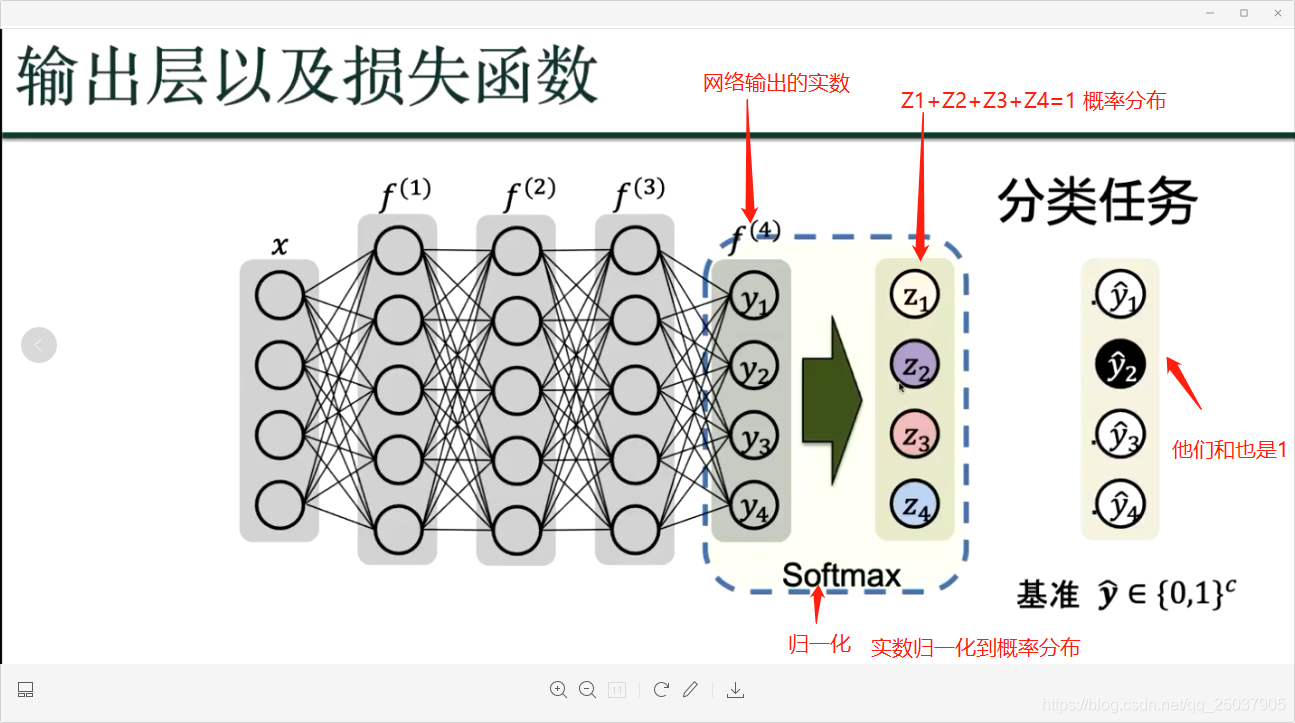
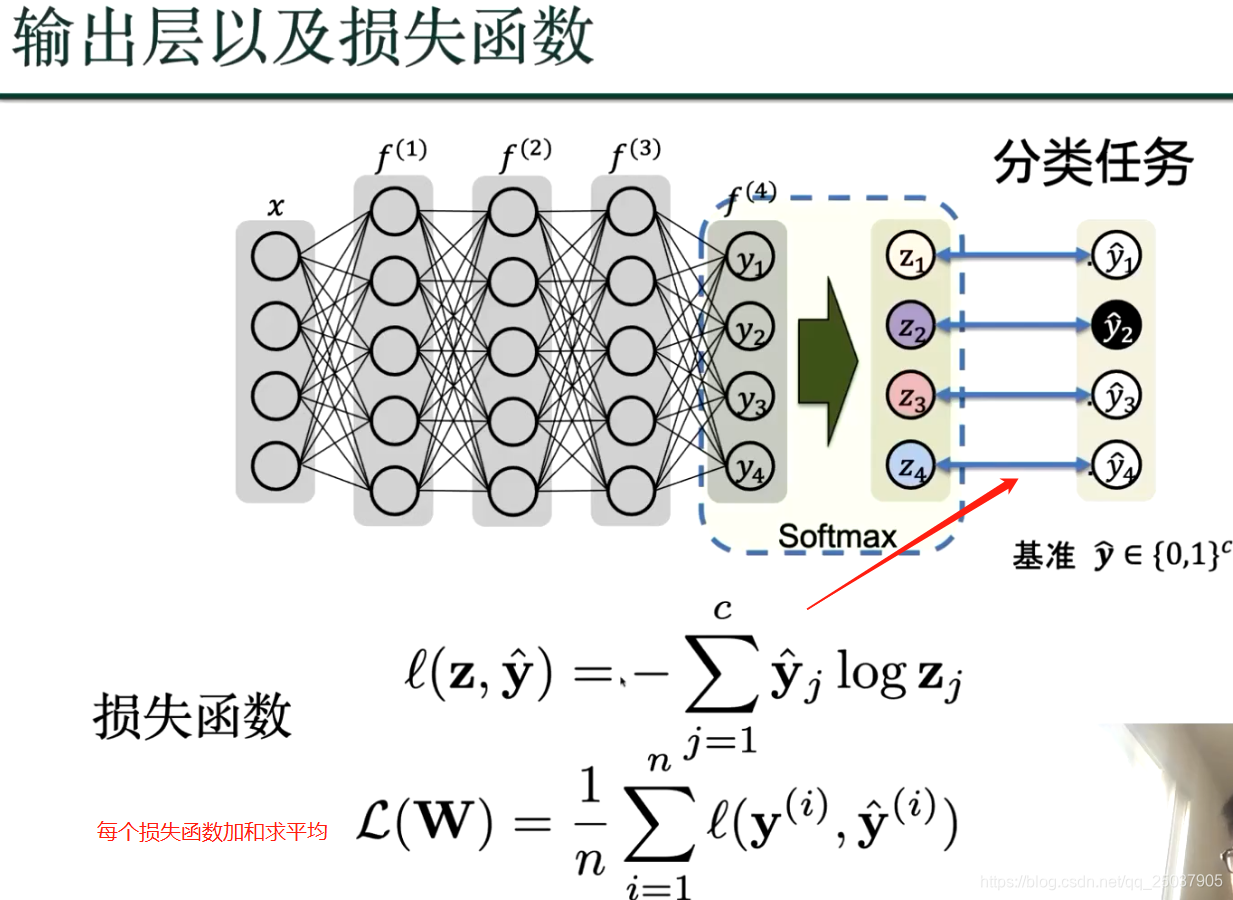
我们的目标是得到损失函数的最小值,越小则代表深度学习的值和基准值最接近;深度学习的结果就越接近真实结果;
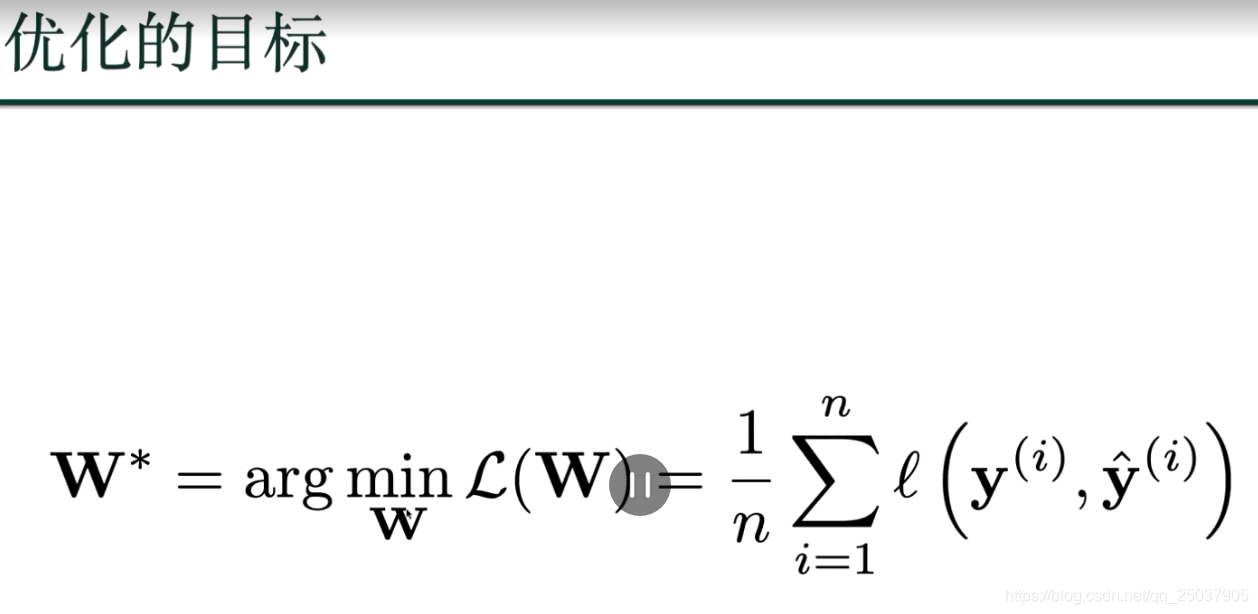 优化的方法:梯度下降法, 对最终的损失函数进行寻找最小值;一般随机的抽样一些,不把所有的计算;
优化的方法:梯度下降法, 对最终的损失函数进行寻找最小值;一般随机的抽样一些,不把所有的计算;
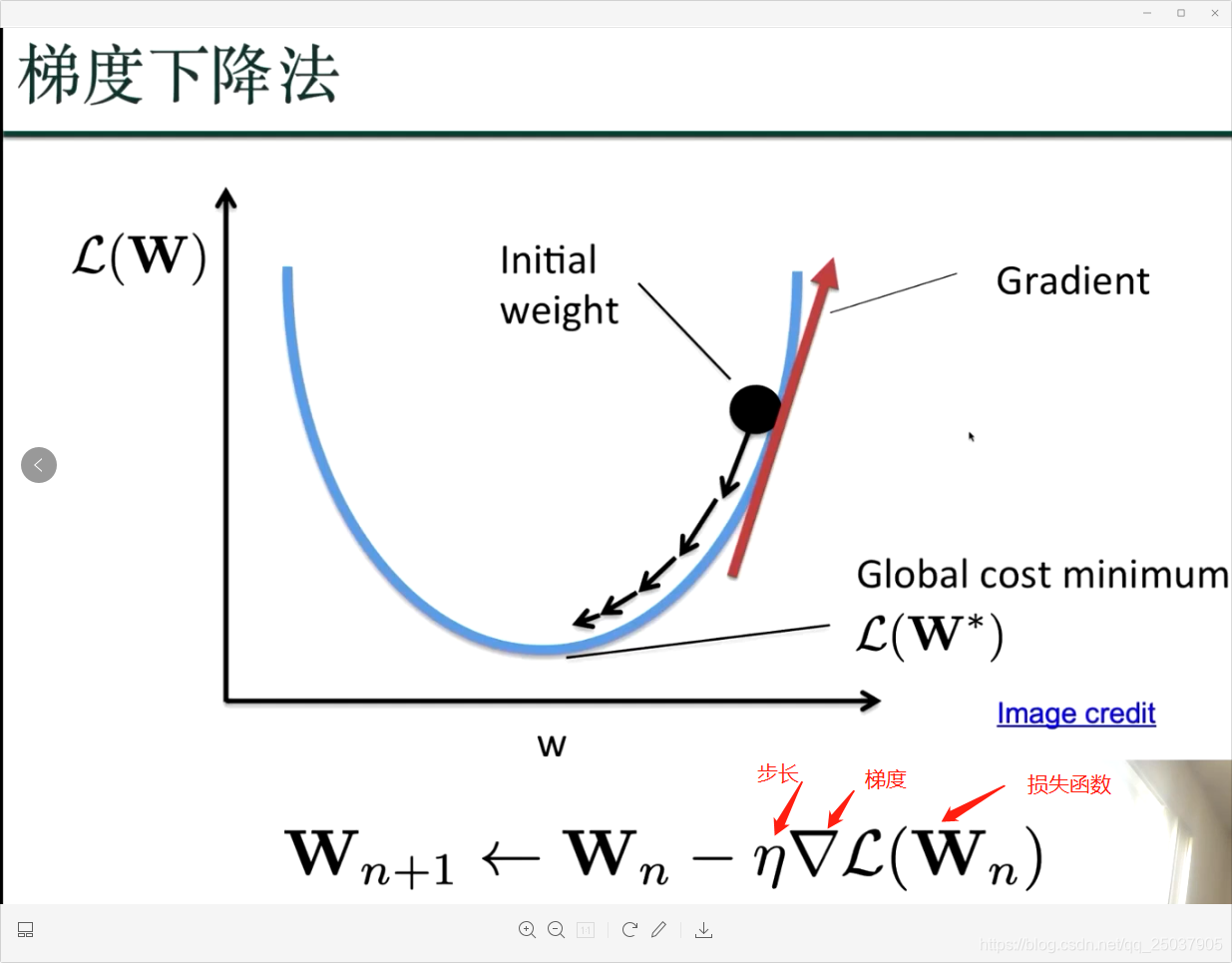
如何优化?梯度下降如何计算?用反向传播:损失函数往前逐个2节点间的参数进行求偏导数;
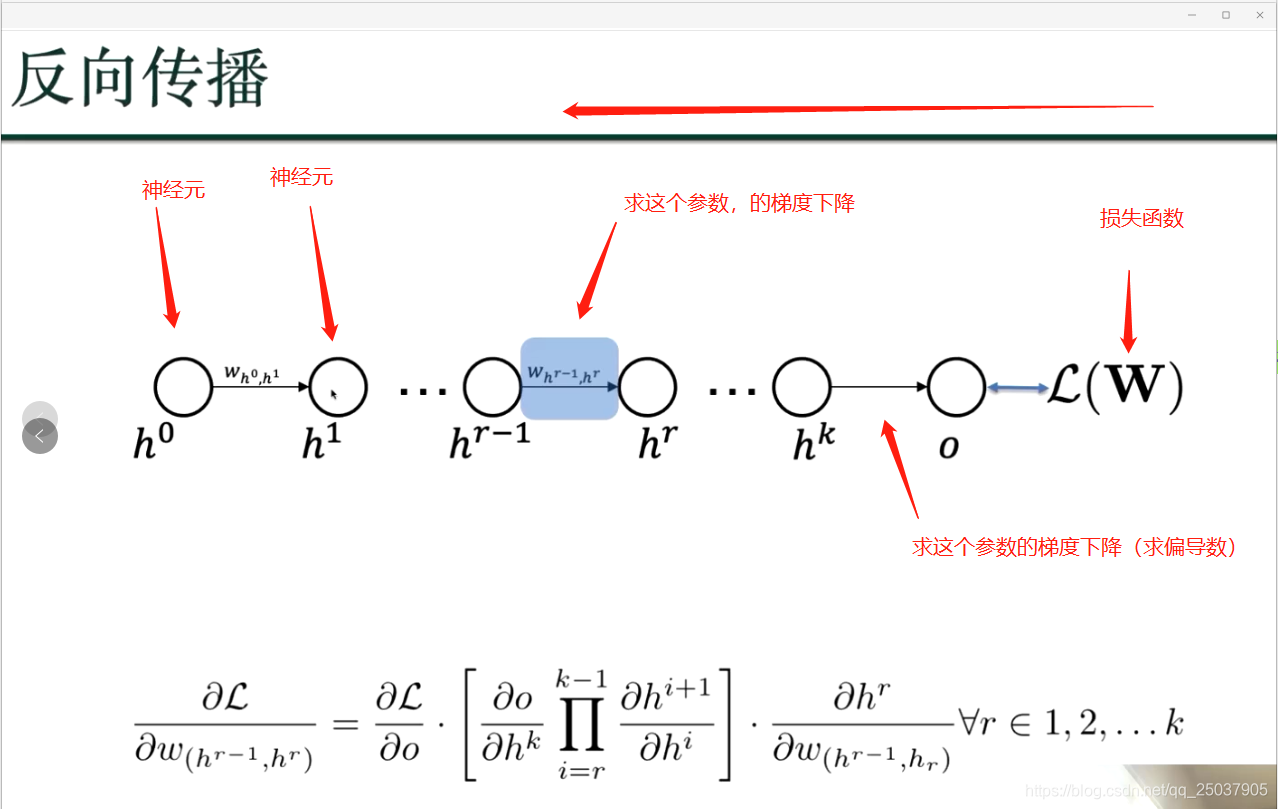
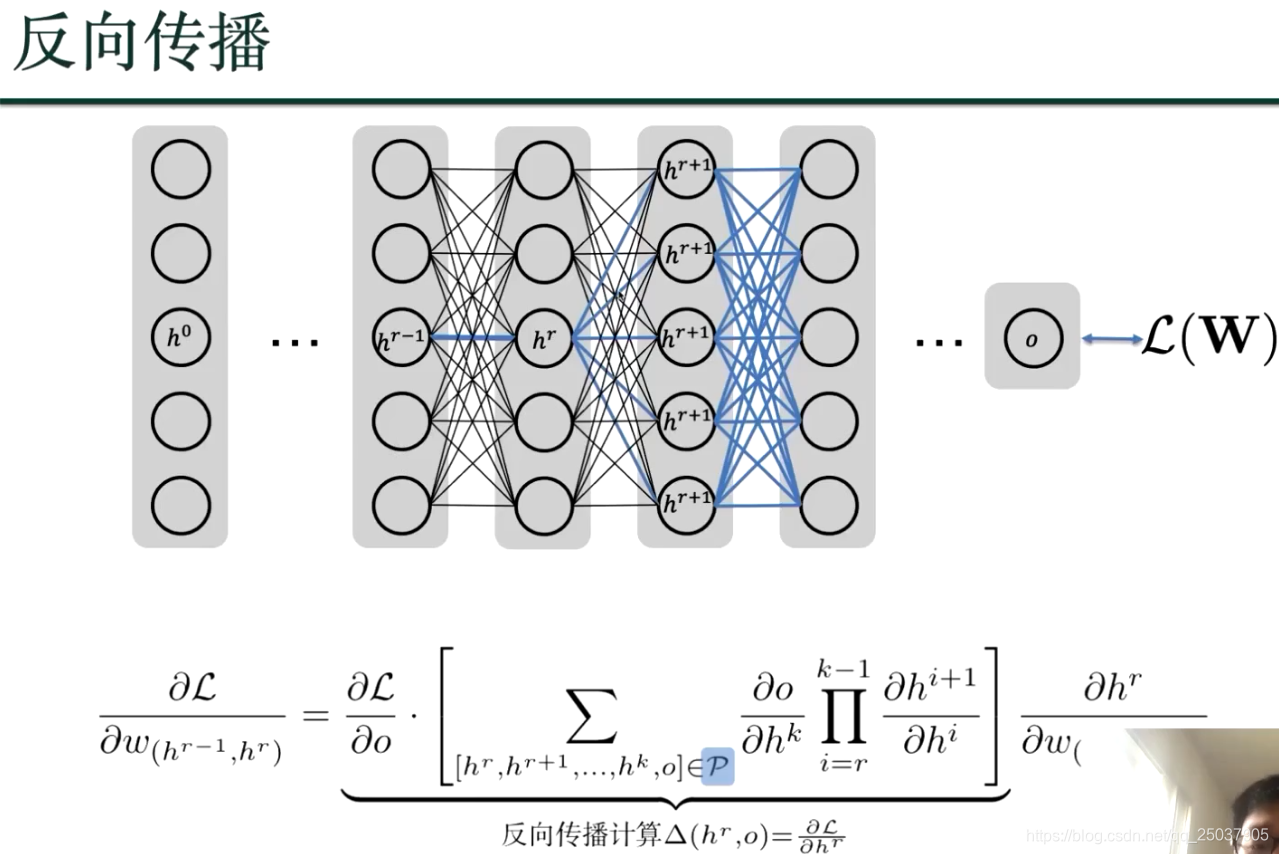
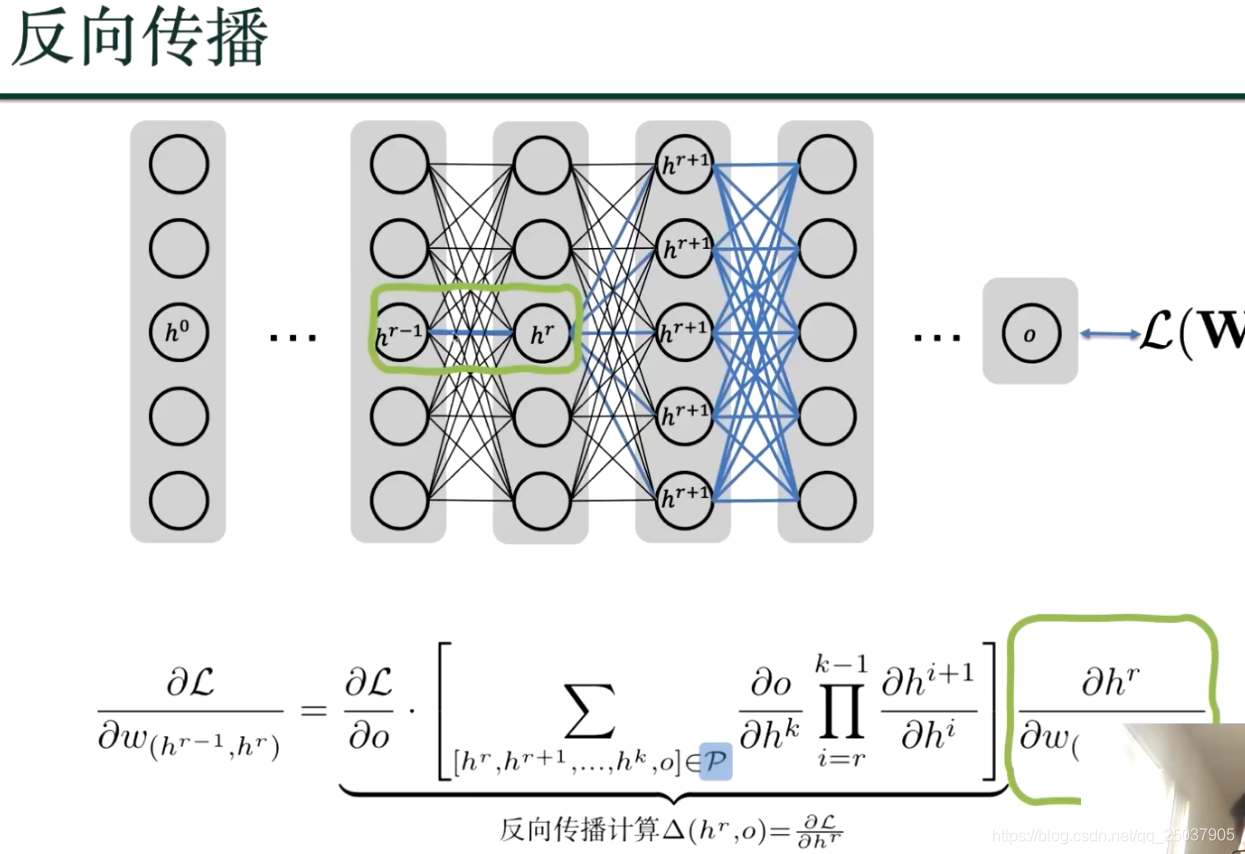
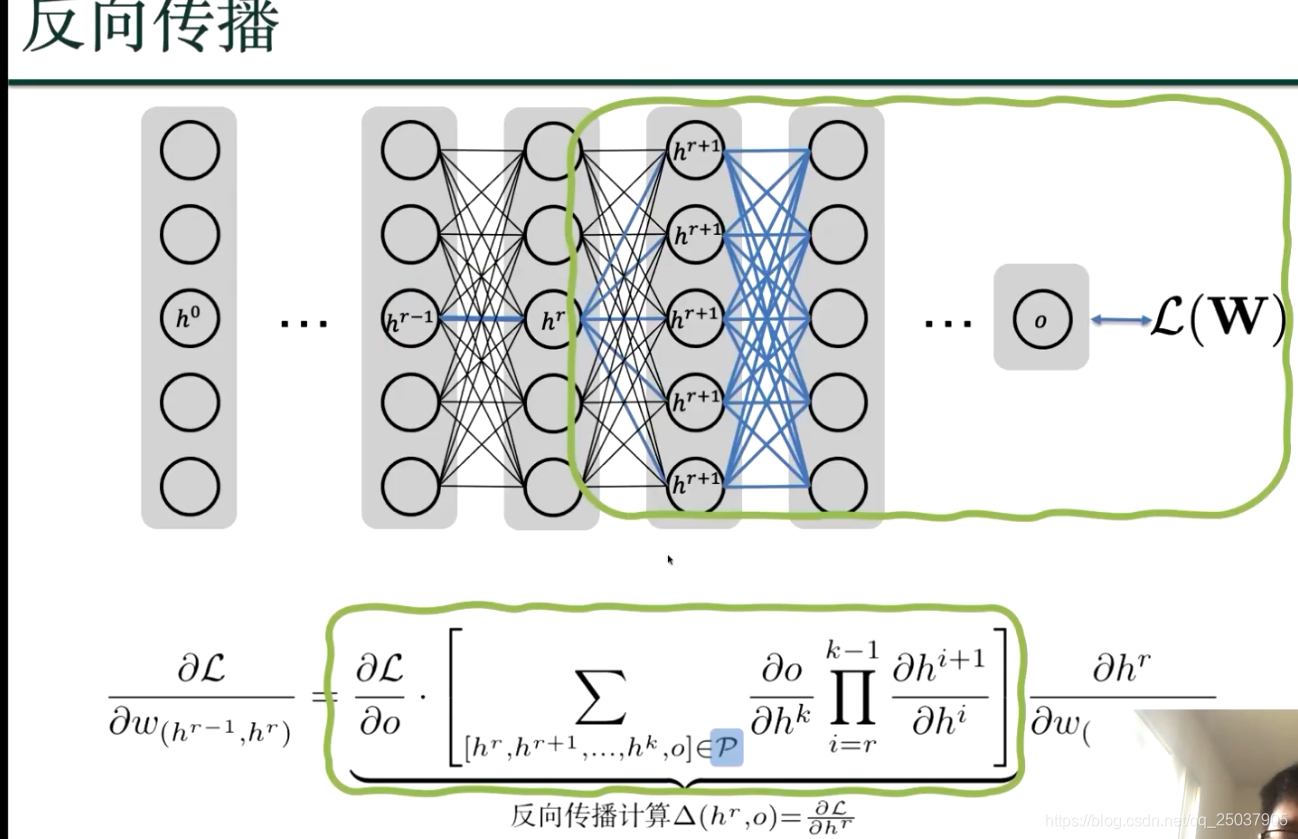
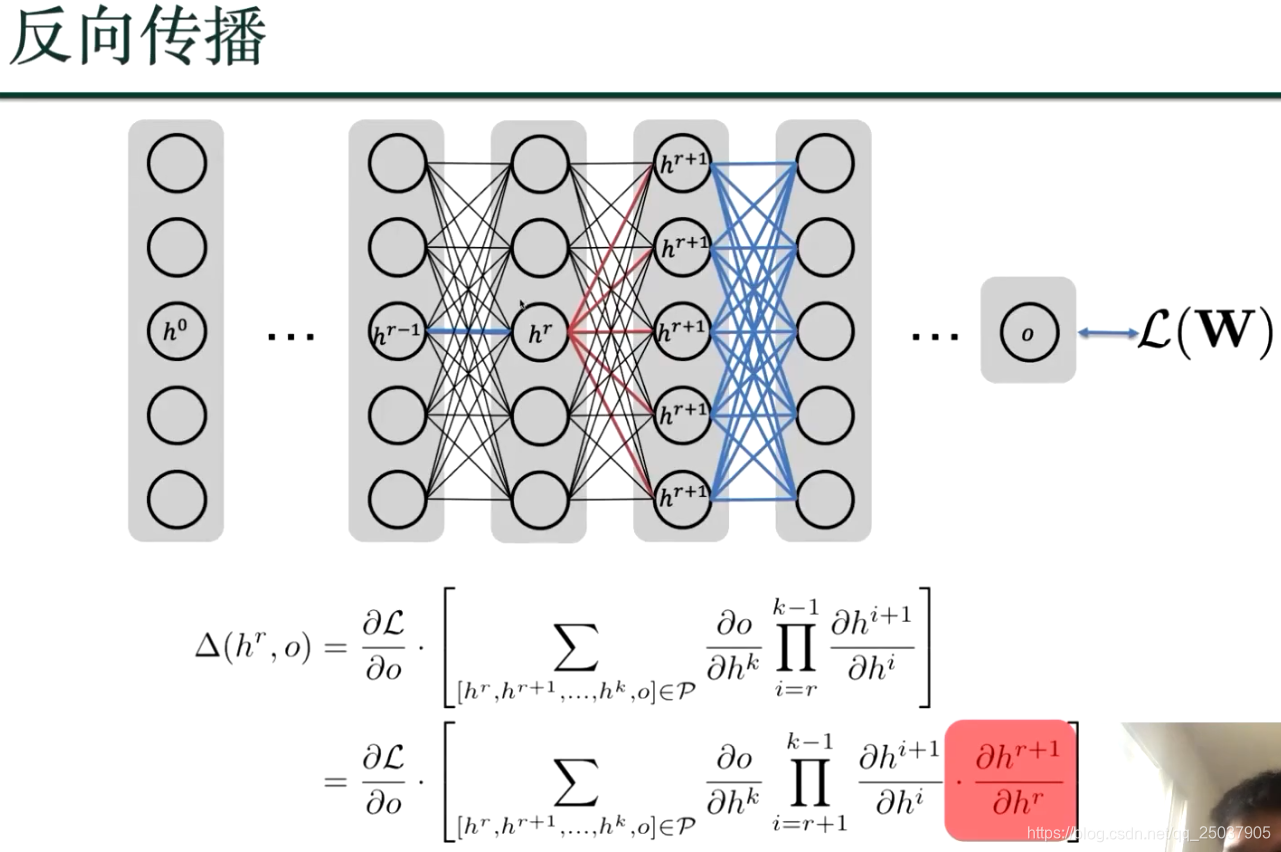
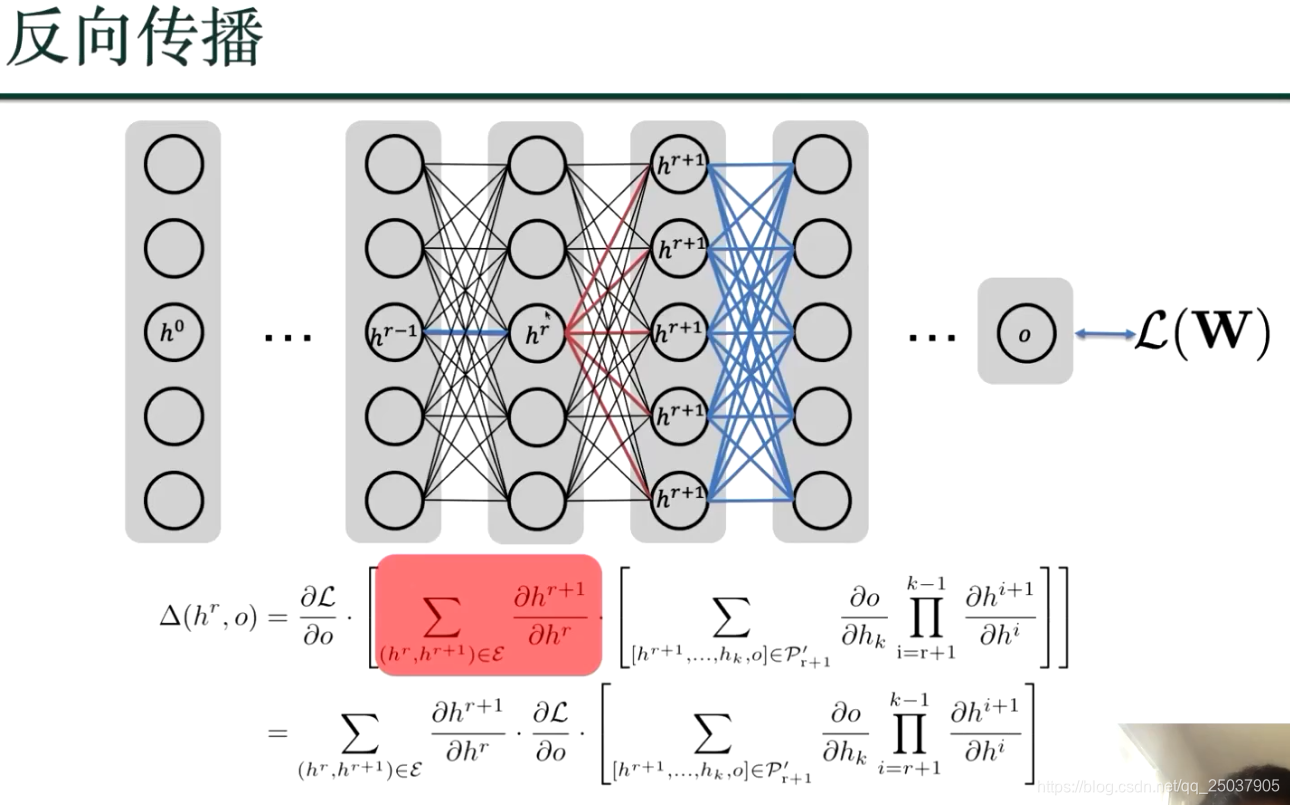
利用动态规划,来算损失函数到hr 的偏导数;
通过以上计算完了梯度,对损失函数进行了优化;
我们的目标是得到损失函数的最小值,越小则代表深度学习的值和基准值最接近;深度学习的结果就越接近真实结果;
优化的方法:梯度下降法, 对最终的损失函数进行寻找最小值;一般随机的抽样一些,不把所有的计算;
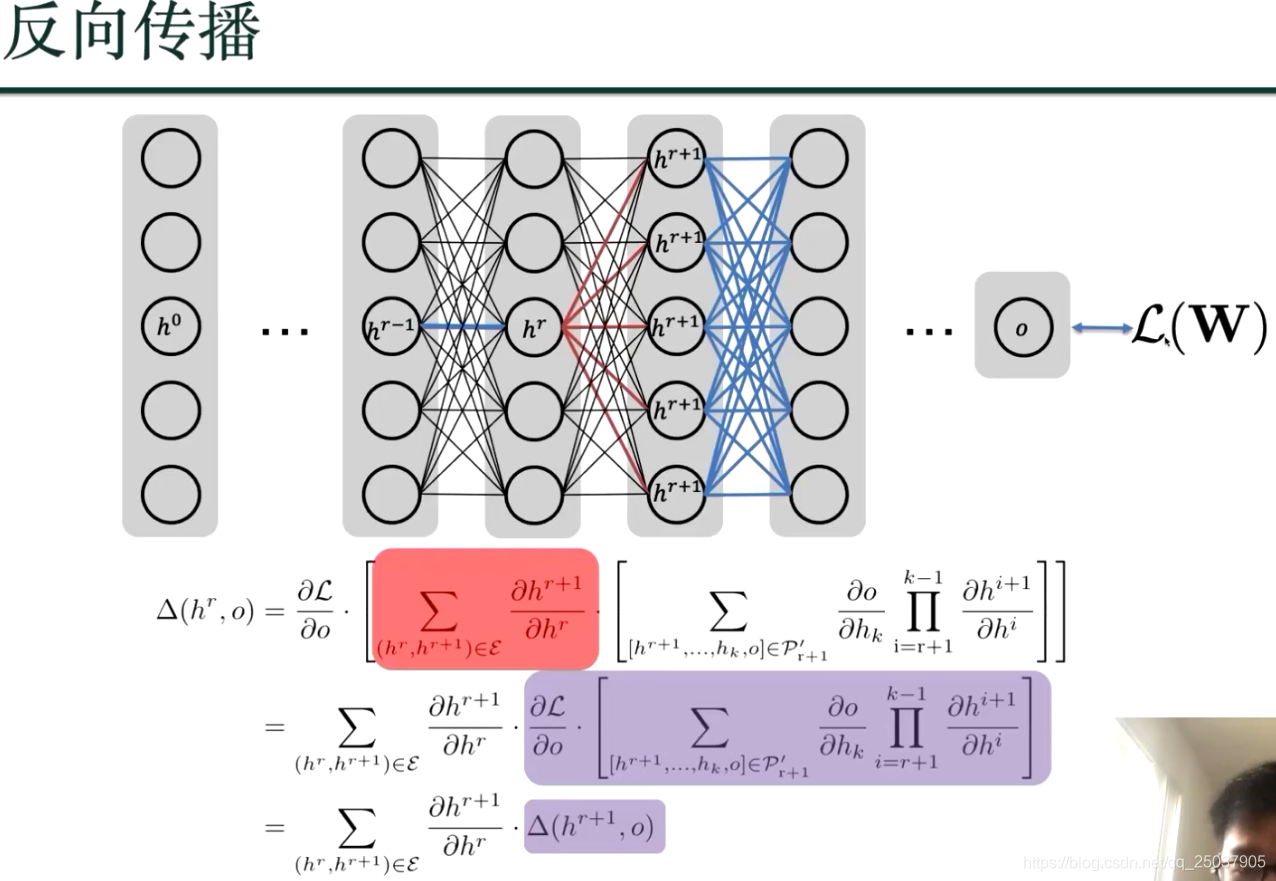
利用动态规划,来算损失函数到hr 的偏导数;
通过以上计算完了梯度,对损失函数进行了优化;

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























