










1、树
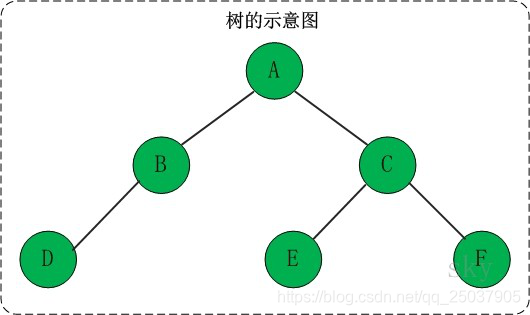
然后树这种结构,如何在计算机当中存储呢?数组和链表的数据类型可以存储;如下图:
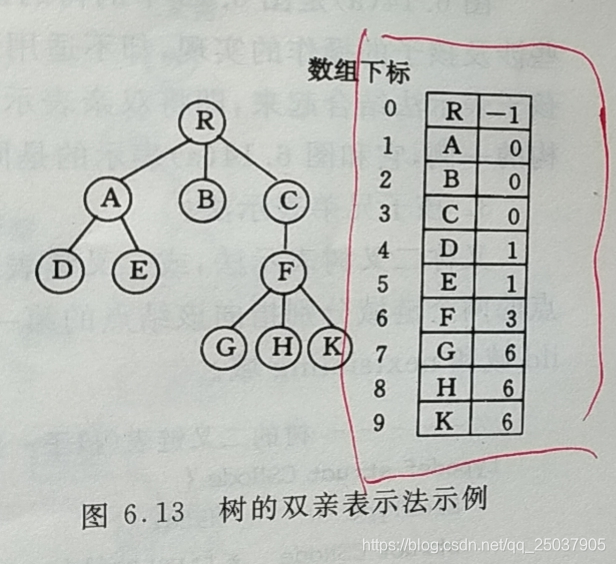
树变换为数组结构:
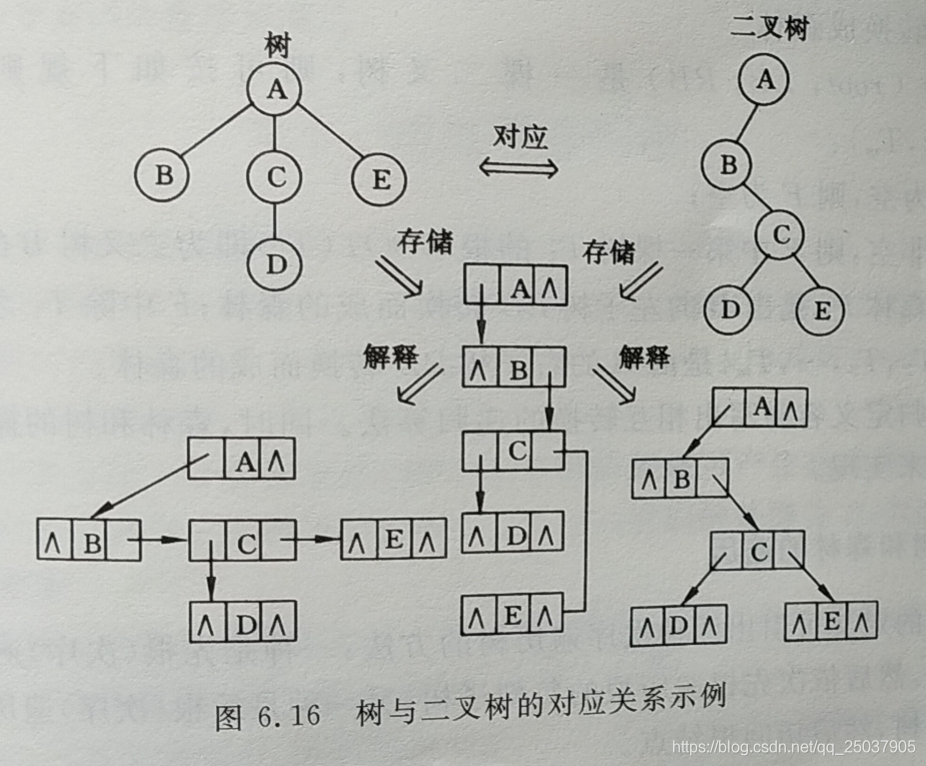
树变换为链表结构:
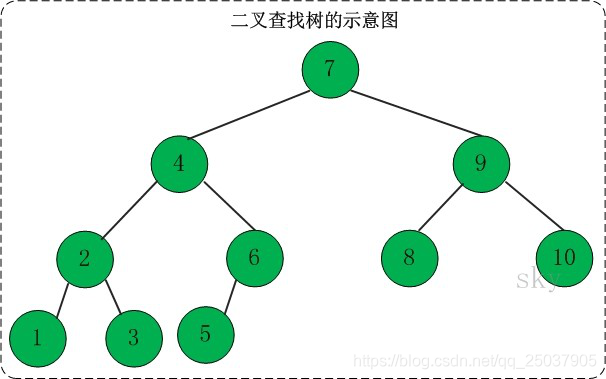
2、二叉查找树BST;包含左子树和右子树的树,节点下最大有俩个子树,左子树节点都小于根节点,右子树节点都大于根节点。
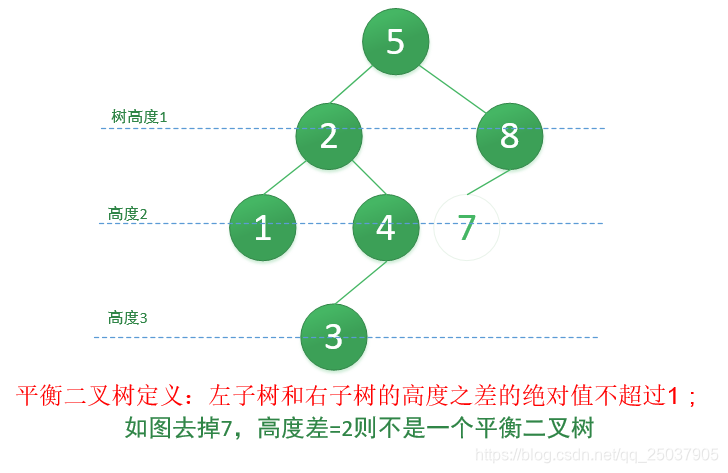
3、平衡二叉查找树AVL;它的作用是优化了二叉树减少计算量,普通的二叉搜索树是有缺陷的;如果左子树和右子树高度相差巨大,那么在运算的高度就会越多。
所以左子树和右子树的高度差不超过1,就能把降低高度,把更多节点安排在层内。从而减少计算量。
当发生不平衡的情况,需要旋转来使它平衡,旋转分为:单旋转和双旋转:
单旋转
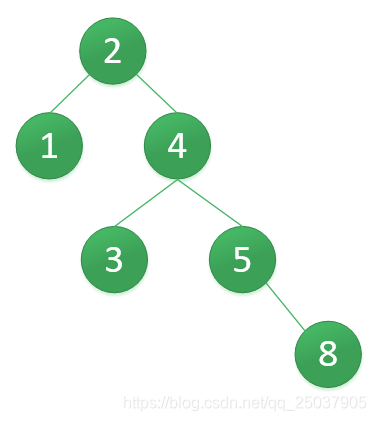
第一次右单旋得到
第二次左单旋得到
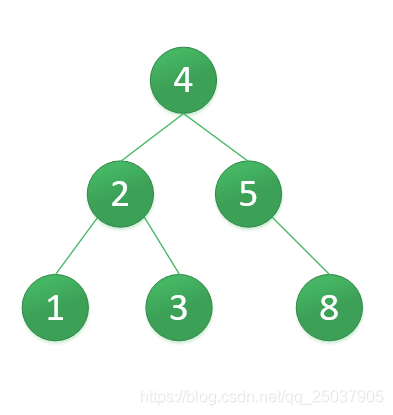
最终我们得到一个高度2的平衡二叉搜索树,如下:
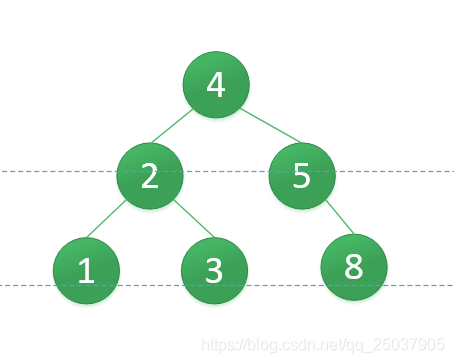
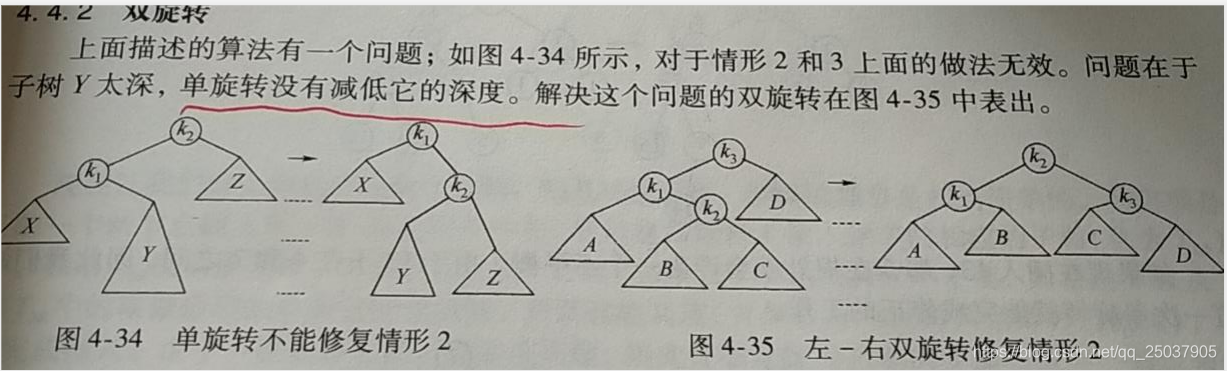
双旋转
Y高度过大,无法通过单旋转搞定AVL的平衡树;Y拆成B和C俩个节点,然后单旋转;
4、红黑树;它是一个自平衡的二叉搜索树,通过红色和黑色来标识节点;红黑树通过变色、左旋和右旋来保持平衡,任何不平衡都会在三次旋转之内解决;它不是一个严格的平衡二叉搜索树AVL,因此它在插入和删除的时候旋转的次数少;
- 节点是红色或黑色。
- 根节点是黑色。
- 每个叶子节点都是黑色的空节点(NIL节点)。
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。(完全二叉树)

5、B树;考虑磁盘IO的性能问题,B树的思路是把多个节点的数据聚合到一个节点内;
先看一下一个平衡二叉树的磁盘IO过程,每个节点在磁盘上占用一个数据页(物理磁盘上叫块,页是操作系统映射块的指针。);
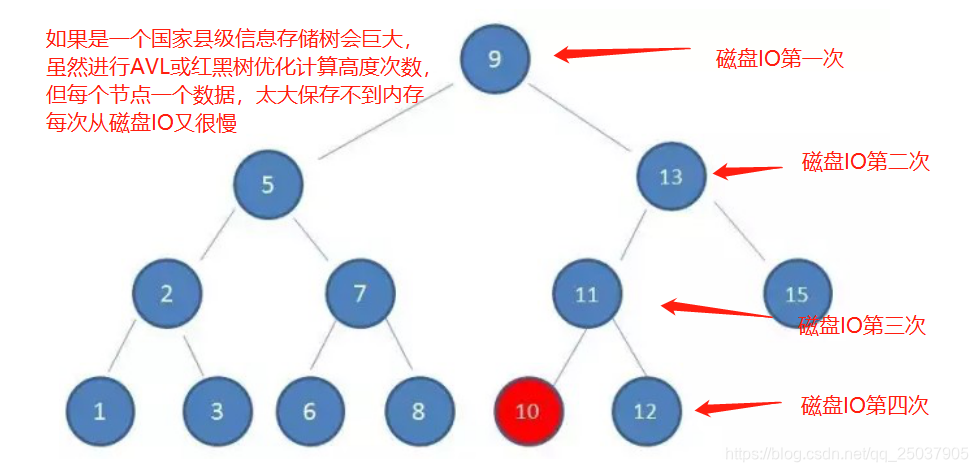
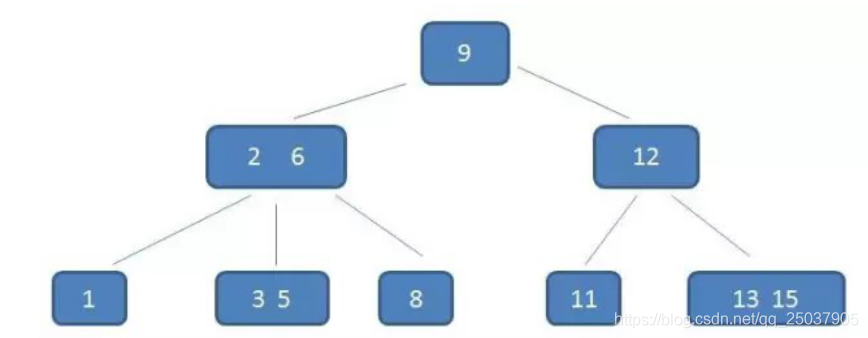
然后看一下B树是怎么优化性能的。看它的结构如下,4层树压缩到3层树。通过节点合并,增加了每个页的存储数量,减少了页的数量,因此磁盘IO的次数减少了,查询效率更高。
2-6,3-5,13-15,加载在内存中进行查找。
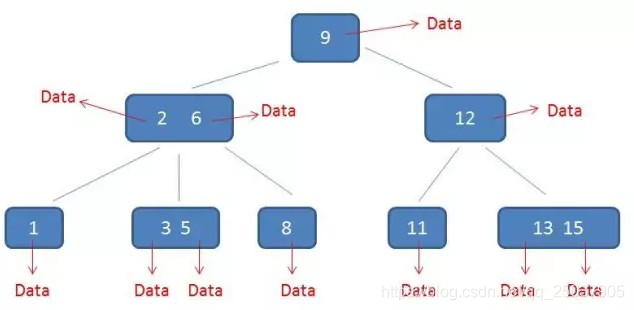
6、B+树;是B树的优化,性能更高;主要解决了B树内存占用过大。
每个元素不保存数据,只用来索引,所有数据 都保存在叶子节点。
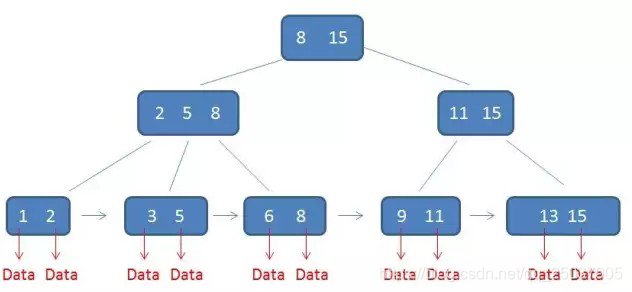
不同点:
1、只有叶子节点存储数据
2、各个叶子节点形成一个链表,可以范围查询
3、处理叶子节点,其他节点都保存的索引,很小,内存占用空间少;
总结一下:
1、内存计算最优的是红黑树,内存计算次数最少;
2、磁盘计算最优的是B+树,磁盘IO最少,内存计算次数少,占用内存少;
应用场景:
- CocurrentHashMap 他是java的一个线程安全额的数据结构,数据结构都存在内存里的内存计算,所以用红黑树设计最优;
- mysql的数据存储,B+树;超大规模的数据就不能用内存了,需要磁盘存储,因此B+树适合数据库存储的设计;所以MYSQL的索引和B+树的关系可以理解了。
- 字符串的查找(过滤);建立一个表存放过滤的文本,我们知道有几种方法:
- 查找”我是中国人“,我,从内存表里查一遍,是从内存表里查一遍。。。。。。
- 采用hash表建立表
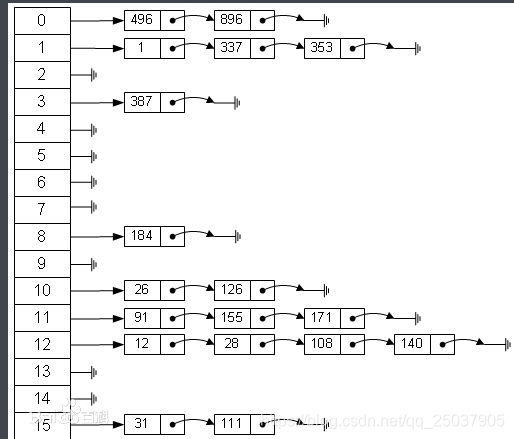 ,通过我的hash值去表里找,好处不用遍历所有表里的数据;
,通过我的hash值去表里找,好处不用遍历所有表里的数据; - 字典树方式建立表;常用词先放在数组里排序,然后构成一个字典树,最后通过先序遍历即可找到元素。
- 还有一种设计,叫跳表,也是用来做大规模的数据存储;他简化了B+的设计,它是用线性数据结构来实现类似的B+树功能,但是它不是一颗树;
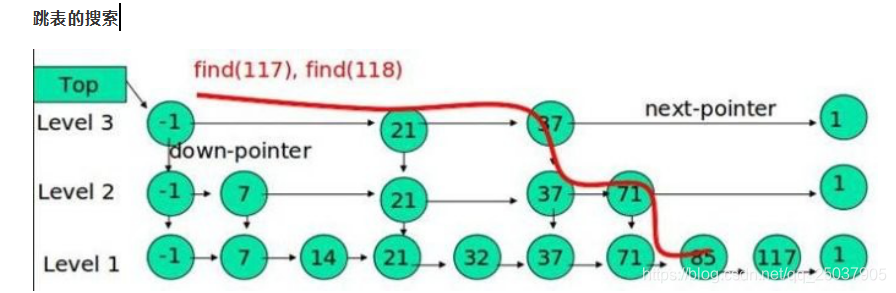
level 2,level 3是存储的索引,也就是序号;level 存储的是序号+数据;
如图查找到85的数据,先查询一级索引level3,查找到85是37-120之内;再二级索引,它的序号粒度比一级索引更小更多,找到71是最接近85的;然后第三层查找找到85;
在真实设计当中,是俩个文件,把索引文件(存放序号的文件)和数据文件分开;比如:index-30-100.log ,2021_6_7_data1000.log;
第一次检索,查找文件名85是找index-30-100.log这个文件;
第二次检索,查找index-30-100.log文件里的71对应的data.log是什么?找到它存放在2021_6_7_data1000.log;文件内;这个data数据是满1000条存一个;映射关系存在index-30-100.log文件里;
第三次检索,2021_6_7_data1000.log里找到序号85映射的数据;返回该数据完成查找;
跳表可以快速的从海量数据里查找数据,但是跳表的删除和插入较慢(磁盘IO来写入和删除文件);
因此跳表的设计简化了B+,但是不适合CURD的场景,只适用R查多的场景;因此在kafka的设计当中,使用了跳表来做队列消息的持久化;用来做消息队列系统的HA;流程是:
当生产者发送消息到kafka时消息内容是根据TOPIC和SLOT存在不同的队列数据类型当中,有一个线程会从队列数据类型里读取消息内容,然后存在跳表的index.log和data.log文件当中,
这样当kafka宕机再重启的时候,会快速的从跳表文件把数据恢复到队列数据类型中;我们发现删除索引的操作几乎很少,因此跳表设计满足kafka的持久化设计需求;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









