







 本文介绍了使用PyTorch实现TextCNN进行文本分类的过程,包括数据预处理、模型构建、训练脚本等步骤。通过数据预处理,将文本转换为固定长度的词向量输入模型。模型结构包括Embedding层、CNN层和全连接层。在训练过程中,随着准确率提高,损失(loss)可能增大,这是由于分类结果与训练集分布接近导致。
本文介绍了使用PyTorch实现TextCNN进行文本分类的过程,包括数据预处理、模型构建、训练脚本等步骤。通过数据预处理,将文本转换为固定长度的词向量输入模型。模型结构包括Embedding层、CNN层和全连接层。在训练过程中,随着准确率提高,损失(loss)可能增大,这是由于分类结果与训练集分布接近导致。
pytorch实现textCNN
1. 原理
2014年的一篇文章,开创cnn用到文本分类的先河。Convolutional Neural Networks for Sentence Classification
原理说简单也简单,其实就是单层CNN加个全连接层:
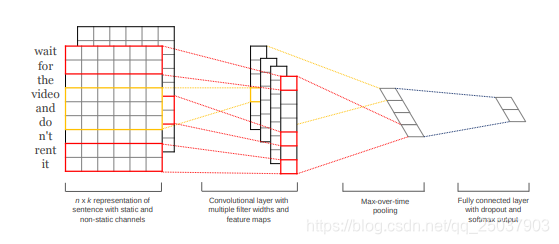
不过与图像中的cnn相比,改动为将卷积核的宽固定为一个词向量的维度,而长度一般取2,3,4,5这样。上图中第一幅图的每个词对应的一行为一个词向量,可以使用word2vec或者glove预训练得到。本例中使用随机初始化的向量。
2. 数据预处理
手中有三个文件,分别为train.txt,valid.txt,test.txt。其中每一行是一个字符串化的字典,格式为{‘type’: ‘xx’, ‘text’:‘xxxxx’}。
2.1 转换为csv格式
首先将每个文件转换为csv文件,分为text和label两列。一共有4种label,可以转换为数字表示。代码如下:
# 获取文件内容
def getData(file):
f = open(file,'r')
raw_data = f.readlines()
return raw_data
# 转换文件格式
def d2csv(raw_data,label_map,name):
texts = []
labels = []
i = 0
for line in raw_data:
d = eval(line) #将每行字符串转换为字典
if len(d['type']) <= 1 or len(d['text']) <= 1: #筛掉无效数据
continue
y = label_map[d['type']] #根据label_map将label转换为数字表示
x = d['text']
texts.append(x)
labels.append(y)
i+=1
if i%1000 == 0:
print(i)
df = pd.DataFrame({'text':texts,'label':labels})
df.to_csv('data/'+name+'.csv',index=False,sep='\t') # 保存文件
label_map = {'执行':0,'刑事':1,'民事':2,'行政':3}
train_data = getData('data/train.txt') #22000+行
d2csv(train_data,label_map,'train')
valid_data = getData('data/valid.txt') # 2000+行
d2csv(valid_data,label_map,'valid')
test_data = getData('data/test.txt') # 2000+行
d2csv(test_data,label_map,'test')
2.2 观察数据分布
对于本任务来说,需要观察每个文本分词之后的长度。因为每个句子是不一样长的,所以需要设定一个固定的长度给模型,数据中不够长的部分填充,超出部分舍去。训练的时候只有训练数据,因此观察训练数据的文本长度分布即可。分词可以使用jieba分词等工具。
train_text = []
for line in train_data:
d = eval(line)
t = jieba.cut(d['text'])
train_text.append(t)
sentence_length = [len(x) for x in train_text] #train_text是train.csv中每一行分词之后的数据
%matplotlib notebook
import matplotlib.pyplot as plt
plt.hist(sentence_length,1000,normed=1,cumulative=True)
plt.xlim(0,1000)
plt.show()
得到长度的分布图:
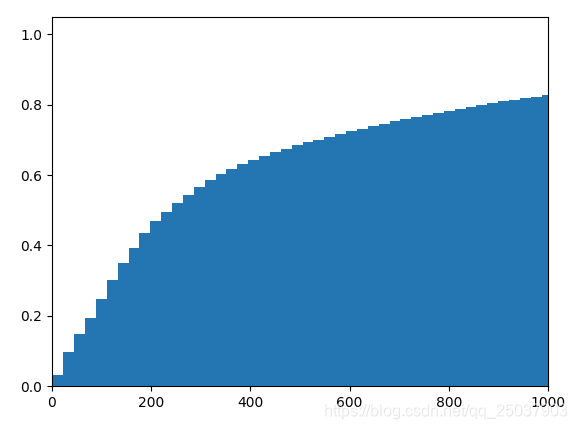
可以看到长度小于1000的文本占据所有训练数据的80%左右,因此训练时每个文本固定长度为1000个词。
2.3 由文本得到训练用的mini-batch数据
目前我们手里的数据为csv形式的两列数据,一列字符串text,一列数字label。label部分不需要再处理了,不过text部分跟可训练的数据还差得远。
假设每个词对应的词向量维度为 D i m Dim Dim,每一个样本的分词后的长度已知设为 W = 1000 W=1000 W=1000,每个mini-batch的大小为 N N N。那么我们希望得到的是一个个维度为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8925
8925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









