




Hive 常见属性配置
1.1Hive 数据仓库位置配置
1)Default 数据仓库的最原始位置是在 hdfs 上的:/user/hive/warehouse 路径下
2)在仓库目录下,没有对默认的数据库 default 创建文件夹。如果某张表属于 default 数据库,直接在数据仓库目录下创建一个文件夹。
3)修改 default 数据仓库原始位置(将 hive-default.xml.template 如下配置信息拷贝到 hive-site.xml 文件中)
<property>
<name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
1.2 查询后信息显示配置
1)在 hive-site.xml 文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
2)重新启动 hive,对比配置前后差异
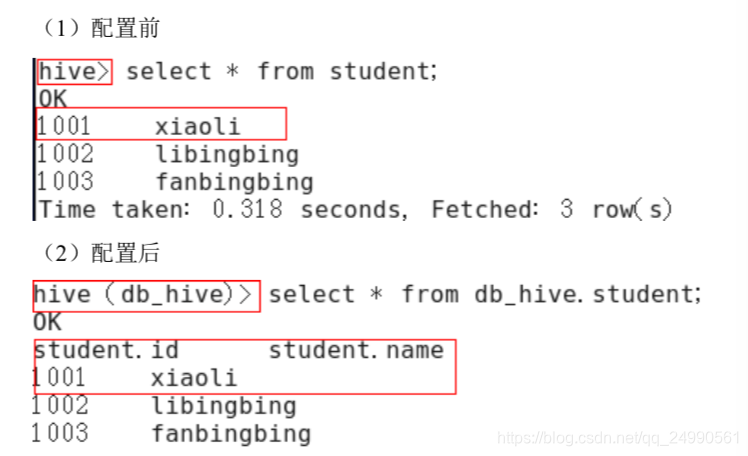
1.3 Hive 运行日志信息配置
1)Hive 的 log 默认存放在/tmp/atguigu/hive.log 目录下(当前用户名下)。
2)修改 hive 的 log 存放日志到/opt/module/hive/logs
(1)修改/opt/module/hive/conf/hive-log4j.properties.template 文件名称为hive-
log4j.properties
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf
[atguigu@hadoop102 conf]$ mv hive-log4j.properties.template hive-log4j.properties
(2)在 hive-log4j.properties 文件中修改 log 存放位置 hive.log.dir=/opt/module/hive/logs
1.4 参数配置方式
1)查看当前所有的配置信息 hive>set;
2)参数的配置三种方式 (1)配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml 注意:用户自定义配置会覆盖默认配置。另外,Hive 也会读入 Hadoop 的配置,因
为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。配置文件 的设定对本机启动的所有 Hive 进程都有效。
(2)命令行参数方式
启动 Hive 时,可以在命令行添加-hiveconf param=value 来设定参数。 例如:
[atguigu@hadoop103 hive]$ bin/hive -hiveconf mapred.reduce.tasks=10; 注意:仅对本次 hive 启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;
(3)参数声明方式
可以在 HQL 中使用 SET 关键字设定参数
例如:
hive (default)> set mapred.reduce.tasks=100;
注意:仅对本次 hive 启动有效。
查看参数设置hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些 系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会 话建立以前已经完成了。

















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









