







 循环神经网络(RNN)适用于处理序列数据,如语音识别、音乐生成、感情分类等。RNN解决了传统神经网络无法处理变长序列的问题,但存在梯度消失问题。GRU和LSTM是为了解决这个问题而提出的,BRNN则提供了双向信息流以提高准确性。此外,RNN在语言模型和序列生成任务中也扮演着重要角色。
循环神经网络(RNN)适用于处理序列数据,如语音识别、音乐生成、感情分类等。RNN解决了传统神经网络无法处理变长序列的问题,但存在梯度消失问题。GRU和LSTM是为了解决这个问题而提出的,BRNN则提供了双向信息流以提高准确性。此外,RNN在语言模型和序列生成任务中也扮演着重要角色。
为什么选择序列模型
序列模型可以用于处理序列数据。序列数据的例子有
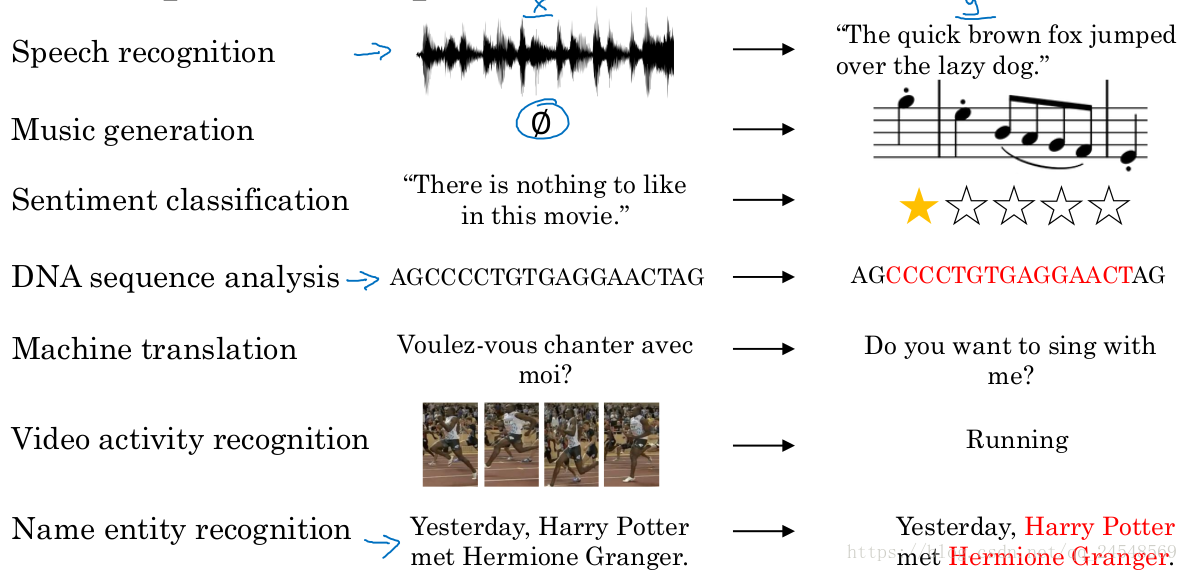
在语音识别中,输入的是语音序列,输出的是对应的句子。
在音乐生成中,输入的是音乐风格或者无,输出的是音乐序列。
在感情分类中,输入的是带有感情的句子,输出的是个人对电影的评价。
在DNA序列分析中,输入DNA片段,输出的是DNA片段对应的名字。
在机器翻译中,输入翻译内容,输出翻译结果。
在视频动作识别中,输入视频序列,输出人物动作。
在名字实体识别中,输入一句话,输出句子中的名字实体。
可以看到许多应用的数据都是序列数据,序列模型有许多广泛的应用。
数学符号
首先设定序列模型中使用的数学符号。
有一个自然语言处理的例子:识别出句子中的人名。输入x为:”Harry Potter and Hermione Granger invented a new spell.”。输出y应该是:1 1 0 1 1 0 0 0 0。1表示单词是人名,0表示单词不是人名。对于”Harry”和”Potter”,要识别出这两个人名单词是连在一起的。使用上标 <t> < t > <script type="math/tex" id="MathJax-Element-234"> </script>来表示句子中第t个单词。例如 x<1> x < 1 > 表示”Harry”, y<1> y < 1 > 表示”Harry”是人名单词。 Tx T x 表示句子的单词数量,在这个例子中是9。
表示句子中的单词的方式是,首先建立一个词典,记录数据中所有出现的单词,该词典可以组成一个词典向量,单词所处的位置置为1,其他元素置为0,这样每个单词可以使用一个向量表示,如下图所示
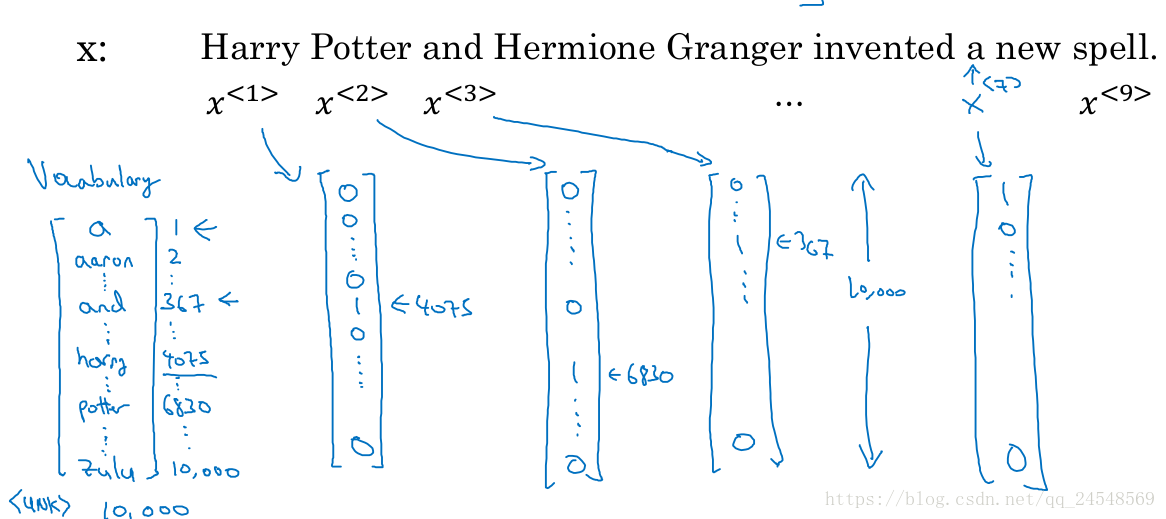
这个词典的数据比较大,可能有10000个单词。一般词典的单词数能够到达30000到50000,商用的词典可能达到百万级以上。如果某个单词没有收录到词典中,就设置词典的UNK标志为1(未知单词)。
循环神经网络RNN模型
对于上述的名字实体识别例子,使用标准神经网络是不可行的,因为直接输入 x=(x<1>,⋯,x<9>) x = ( x < 1 > , ⋯ , x < 9 > ) ,输出 y=(y<1>,⋯,y<9>) y = ( y < 1 > , ⋯ , y < 9 > ) ,9不是固定的,不适合所有的样本。每个样本中的单词数不同,输出的结果也就不同。而且,标准神经网络不能够共享文本在不同位置的特征。
循环神经网络可以解决上面的两个缺点。循环神经网络的结构如下
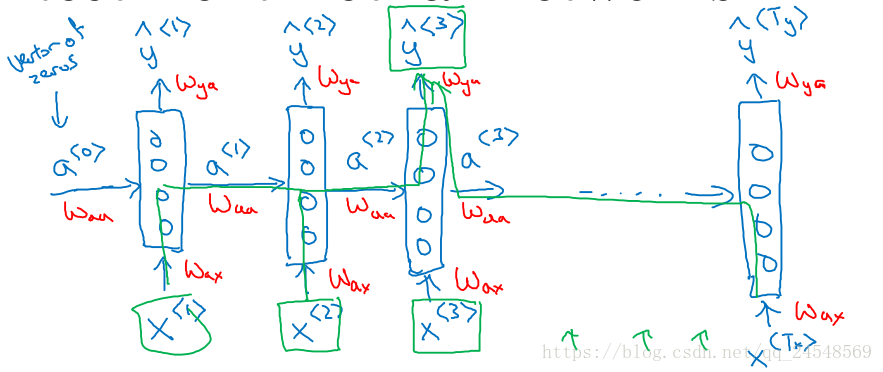
在第1时间步,首先输入 x<1> x < 1 > ,判断 x<1> x < 1 > 是否是人名,输出 y<1> y < 1 > 。然后第2时间步,输入 x<2> x < 2 > ,同时输入上一时间步中计算的 a<1> a < 1 > ,计算出 y<2> y < 2 > 。如此类推,直到计算最后一个 x<Ty> x < T y > 。循环神经网络是根据输入的 x<t> x < t > 和上一时间步计算的 a<t−1> a < t − 1 > 来判断单词 x<t> x < t > 是否是人名。这相当于通过上下文的上文来判断单词是否是人名。开始的 a<0> a < 0 > 是一个全0的向量,x的参数是 Wax W a x ,a的参数是 Waa W a a ,计算y的参数是 Wya W y a 。在每个时间步,参数都是相同的。
循环神经网络结构的另外一种画法是
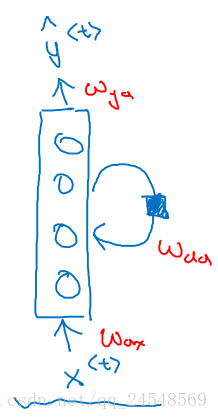
可以看出循环神经网络有循环的结构。
前向传播
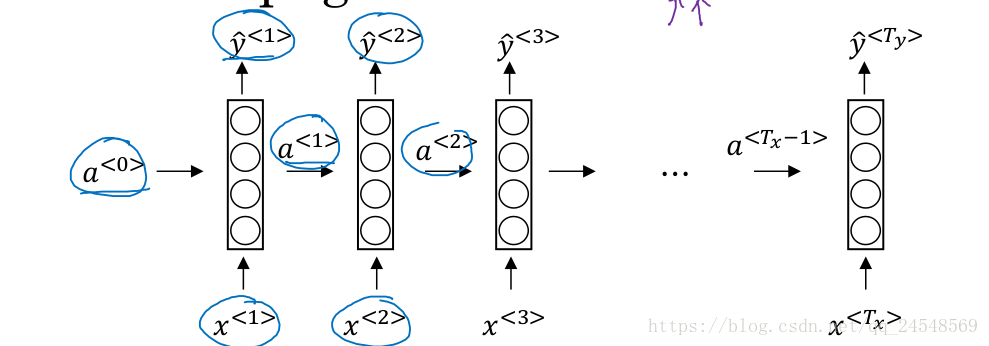
计算第1时间步的 a<1> a < 1 >
其中激活函数 g1 g 1 一般是tanh函数。
计算 y<1> y < 1 >
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









