DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
Parameters:
value : scalar, dict, Series, or DataFrame
Value to use to fill holes (e.g. 0), alternately a dict/Series/DataFrame of values specifying which value to use for each index (for a Series) or column (for a DataFrame). (values not in the dict/Series/DataFrame will not be filled). This value cannot be a list.
method : {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
Method to use for filling holes in reindexed Series pad / ffill: propagate last valid observation forward to next valid backfill / bfill: use NEXT valid observation to fill gap
axis : {0 or ‘index’, 1 or ‘columns’}
inplace : boolean, default False
If True, fill in place. Note: this will modify any other views on this object, (e.g. a no-copy slice for a column in a DataFrame).
limit : int, default None
If method is specified, this is the maximum number of consecutive NaN values to forward/backward fill. In other words, if there is a gap with more than this number of consecutive NaNs, it will only be partially filled. If method is not specified, this is the maximum number of entries along the entire axis where NaNs will be filled. Must be greater than 0 if not None.
downcast : dict, default is None
a dict of item->dtype of what to downcast if possible, or the string ‘infer’ which will try to downcast to an appropriate equal type (e.g. float64 to int64 if possible)
Returns:
filled : DataFrame








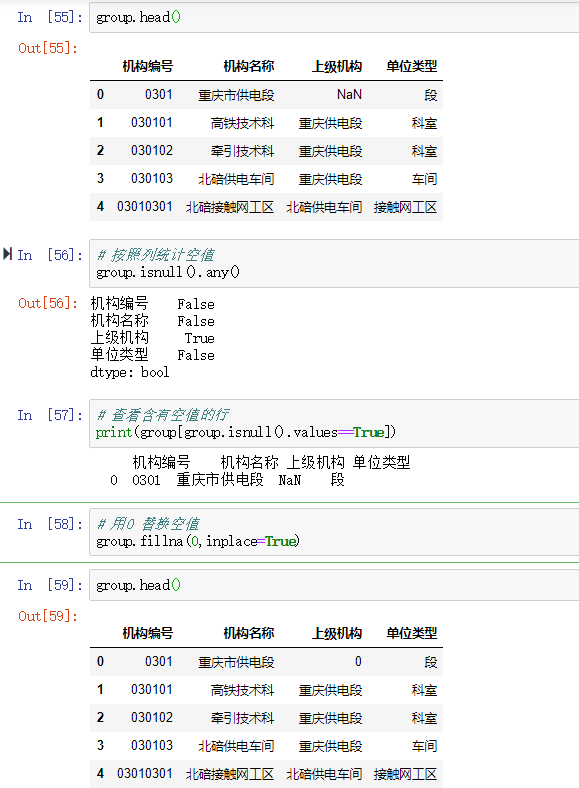
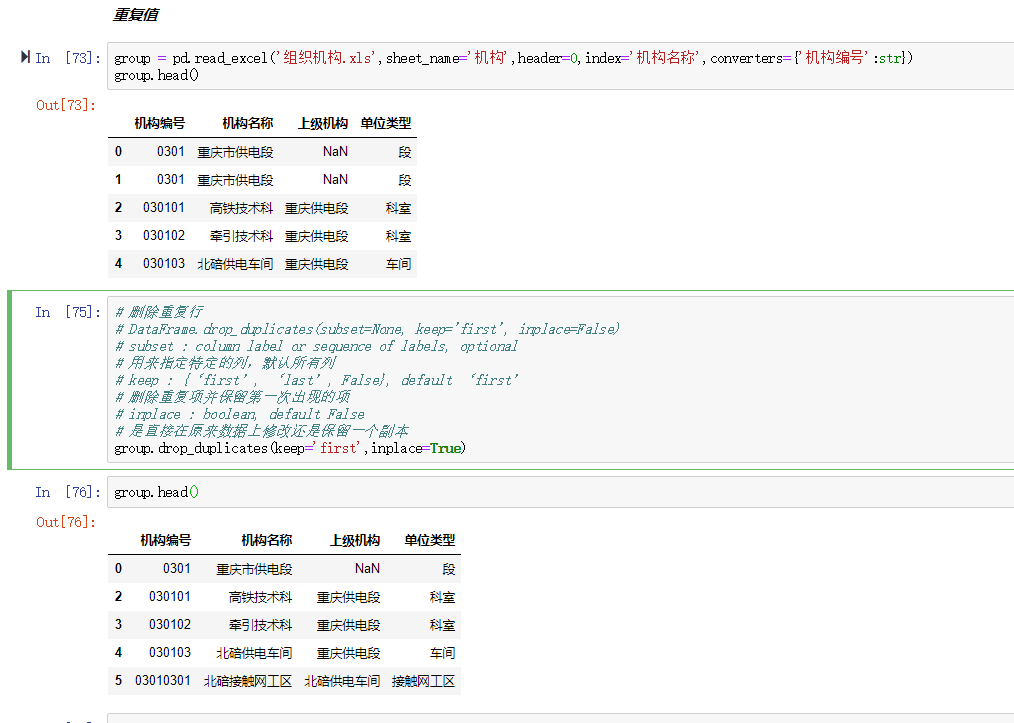
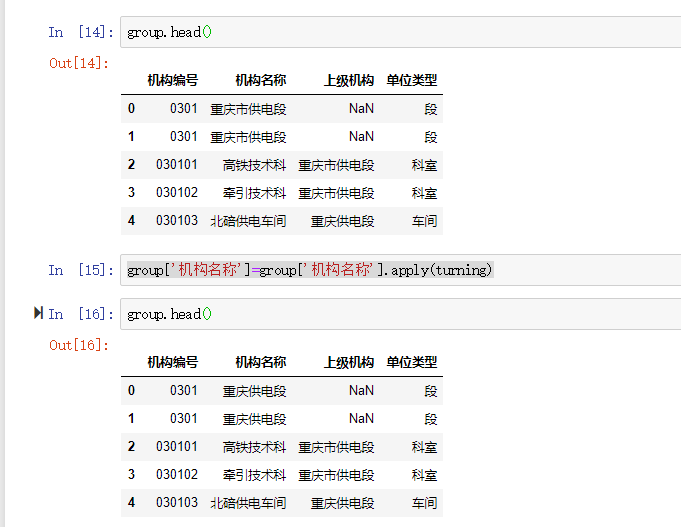
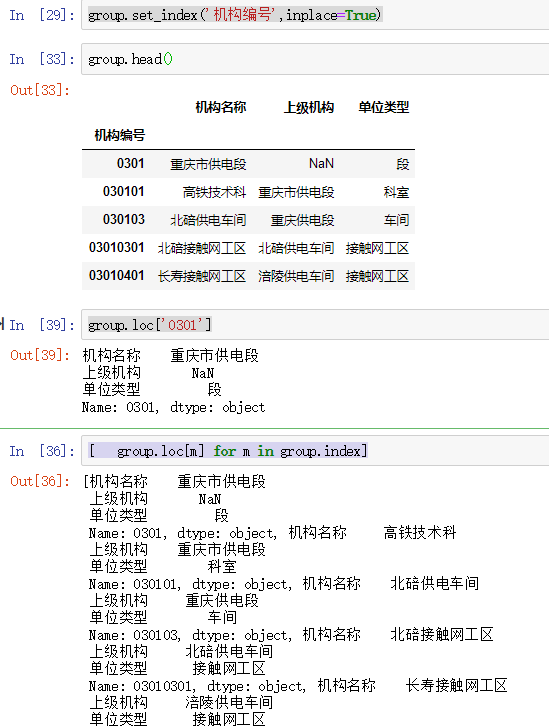
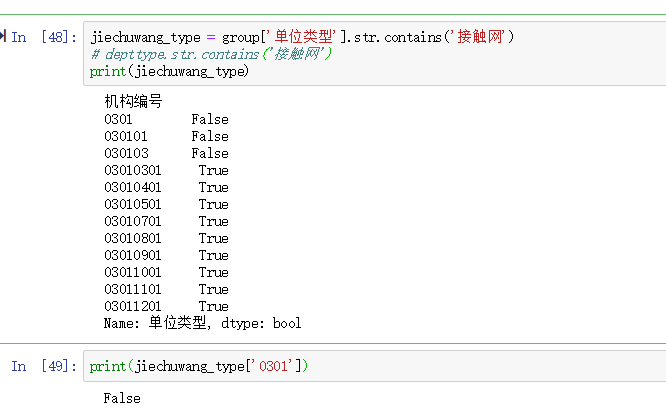
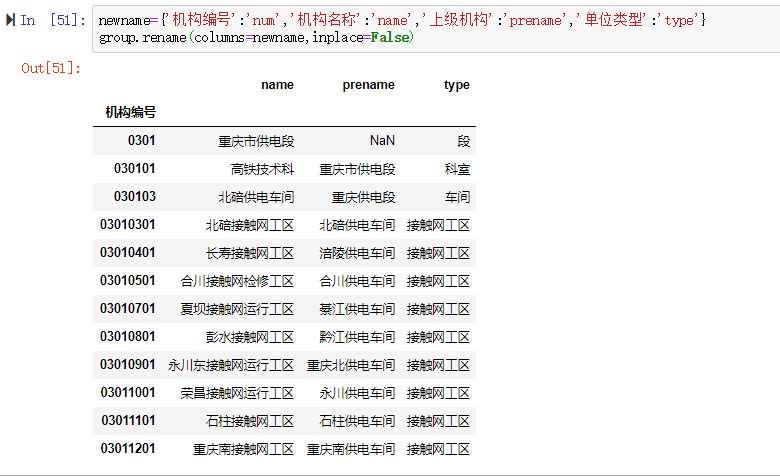
 博客介绍了使用Pandas进行数据清洗的相关内容,包括处理空值(如使用df.fillna,有删除、替换、填充等方式)、处理重复值和异常值,还涉及删除特定列、改变index、用.str()方法清洗columns以及重命名columns等操作。
博客介绍了使用Pandas进行数据清洗的相关内容,包括处理空值(如使用df.fillna,有删除、替换、填充等方式)、处理重复值和异常值,还涉及删除特定列、改变index、用.str()方法清洗columns以及重命名columns等操作。


















 1529
1529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









