







 本文介绍了风控建模中的卡方分箱算法,包括初始化阶段和自底向上的合并阶段。详细讲解了卡方值计算公式,并通过Excel演示了分箱过程。文章还提供了步骤讲解和对应的代码实现,强调了建模服务于业务的重要性。
本文介绍了风控建模中的卡方分箱算法,包括初始化阶段和自底向上的合并阶段。详细讲解了卡方值计算公式,并通过Excel演示了分箱过程。文章还提供了步骤讲解和对应的代码实现,强调了建模服务于业务的重要性。
最重要的事情开始都会讲:建模是始终服务于业务的,没有业务的评分卡就没有灵魂
卡方分箱算法
主要包括两个阶段:初始化阶段和自底向上的合并阶段
卡方值计算公式:
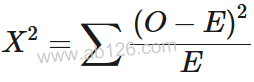
O =观测频率
E =期望频率
∑ =总和
X2 =卡方值
卡方分箱excel计算演示
- 1 对数据进行排序
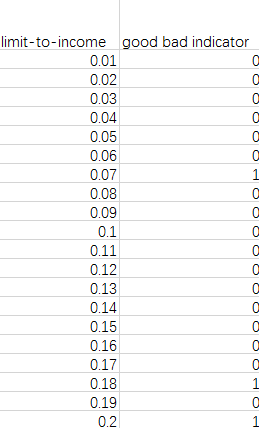
- 2 对数据进行分组(比如10组)
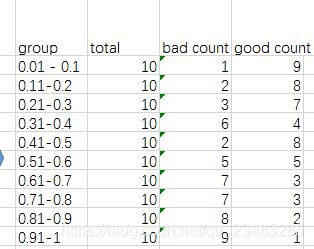
- 3 计算相邻两箱的期望值数据
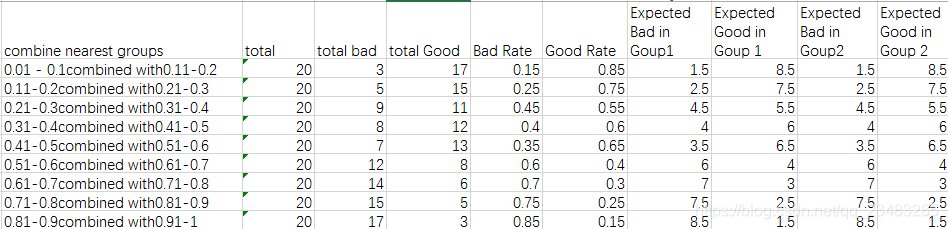
- 4 选择最小卡方值进行合并

如果结果所示 group0.61-0.7 与 group0.71-0.8两组差异化最小卡方值最小,进行合并
步骤讲解以及对应代码
- 1 初始化阶段:首先按照属性值的大小进行排序
- 1.1 建议数据从超过100组,设置为100组方组,方便提高后期数据处理效率
def SplitData(df, col, numOfSplit, special_attribute=[]):
'''
:param df: 按照col排序后的数据集
:param col: 待分箱的变量
:param numOfSplit: 切分的组别数
:param special_attribute: 在切分数据集的时候,某些特殊值需要排除在外
:return: 在原数据集上增加一列,把原始细粒度的col重新划分成粗粒度的值,便于分箱中的合并处理
'''
df2 = df.copy()
if special_attribute != []:
df2 = df.loc[~df[col].isin(special_attribute)]
N = df2.shape[0]
n = N//numOfSplit
splitPointIndex = [i*n for i in range(1,numOfSplit)]
rawValues = sorted(list(df2[col]))
splitPoint = [rawValues[i] for i in splitPointIndex]
splitPoint = sorted(list(set(splitPoint)))
return splitPoint
- 1.2 对于非连续特征,需要先做Bad_Rate转换排序,空值占比问题同样需要考虑,这里设定空值占比 为0.05
#非有序变量单调性检验
def BinBadRate(df, col, target, grantRateIndicator=0):
'''
:param df: 需要计算好坏比率的数据集
:param col: 需要计算好坏比率的特征
:param target: 好坏标签
:param grantRateIndicator: 1返回总体的坏样本率,0不返回
:return: 每箱的坏样本率,以及总体的坏样本率(当grantRateIndicator==1时)
'''
total = df.groupby([col])[target].count()
total = pd.DataFrame({'total': total})
bad = df.groupby([col])[target].sum()
bad = pd.DataFrame({'bad': bad})
regroup = total.merge(bad, left_index=True, right_index=True, how='left')
regroup.reset_index(leve 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









