







一、DeepSeek R1 简介
DeepSeek R1 是一款开源 AI 模型,其性能可与 OpenAI 的 GPT-4 和 Claude 3.5 Sonnet 等顶级模型媲美,尤其在数学、编程和推理等任务上表现出色。最重要的是,它是免费、私密的,可以在本地硬件上离线运行。
DeepSeek R1 提供多个参数规模的版本,从轻量级的 1.5B 参数模型到高性能的 70B 版本。它基于 Qwen 7B 架构的精简优化版本,既保持强大性能,又具备更高的计算效率。
其主要亮点包括:- 完全开源,可自由使用。- 支持本地运行,无需依赖云服务器。- 数据完全可控,确保隐私安全。
二、为什么选择本地部署?
本地运行 AI 模型有以下优势:
-
隐私保障:所有数据均存储在本地,避免敏感信息泄露。
-
零额外成本:DeepSeek R1 免费运行,无需订阅或额外费用。
-
完全控制:可以进行微调和本地优化,无需外部依赖。
三、硬件选型要求
不同版本特点、适用场景及硬件配置对照表
| DeepSeek模型版本 | 参数量 | 特点 | 适用场景 | 硬件配置 |
| DeepSeek-R1-1.5B | 1.5B | 轻量级模型,参数量少,模型规模小 | 适用于轻量级任务,如短文本生成、基础问答等 | 4核处理器、8G内存,无需显卡 |
| DeepSeek-R1-7B | 7B | 平衡型模型,性能较好,硬件需求适中 | 适合中等复杂度任务,如文案撰写、表格处理、统计分析等 | 8核处理器、16G内存,Ryzen7或更高,RTX 3060(12GB)或更高 |
| DeepSeek-R1-8B | 8B | 性能略强于7B模型,适合更高精度需求 | 适合需要更高精度的轻量级任务,比如代码生成、逻辑推理等 | 8核处理器、16G内存,Ryzen7或更高,RTX 3060(12GB)或4060 |
| DeepSeek-R1-14B | 14B | 高性能模型,擅长复杂的任务,如数学推理、代码生成 | 可处理复杂任务,如长文本生成、数据分析等 | i9-13900K或更高、32G内存,RTX 4090(24GB)或A5000 |
| DeepSeek-R1-32B | 32B | 专业级模型,性能强大,适合高精度任务 | 适合超大规模任务,如语言建模、大规模训练、金融预测等 | Xeon 8核、128GB内存或更高,2-4张A100(80GB)或更高 |
| DeepSeek-R1-70B | 70B | 顶级模型,性能最强,适合大规模计算和高复杂任务 | 适合高精度专业领域任务,比如多模态任务预处理。这些任务对硬件要求非常高,需要高端的 CPU 和显卡,适合预算充足的企业或研究机构使用 | Xeon 8核、128GB内存或更高,8张A100/H100(80GB)或更高 |
| DeepSeek-R1-671B | 671B | 超大规模模型,性能卓越,推理速度快,适合极高精度需求 | 适合国家级 / 超大规模 AI 研究,如气候建模、基因组分析等,以及通用人工智能探索 | 64核、512GB或更高,8张A100/H100 |
3.1、参数规模
参数规模的区别,模型越大参数数量逐渐增多,参数数量越多,模型能够学习和表示的知识就越丰富,理论上可以处理更复杂的任务,对各种语言现象和语义理解的能力也更强。比如在回答复杂的逻辑推理问题、处理长文本上下文信息时,70B的模型可能会比1.5B的模型表现得更出色。
-
671B:参数数量最多,模型容量极大,能够学习和记忆海量的知识与信息,对各种复杂语言模式和语义关系的捕捉能力最强。
-
1.5B-70B:参数数量相对少很多,模型容量依次递增,捕捉语言知识和语义关系的能力也逐渐增强,但整体不如671B模型丰富。
3.2、准确性和泛化能力
随着模型规模的增大,在各种基准测试和实际应用中的准确性通常会有所提高。例如在回答事实性问题、进行文本生成等任务时,大规模的模型如 70B、32B 可能更容易给出准确和合理的答案,并且对于未曾见过的数据和任务的泛化能力也更强。小模型如 1.5B、7B 在一些简单任务上可能表现尚可,但遇到复杂或罕见的问题时,准确性可能会降低。
-
671B:在各类任务上的准确性通常更高,如在数学推理、复杂逻辑问题解决、长文本理解与生成等方面,能更准确地给出答案和合理的解释。
-
1.5B-70B:随着参数增加准确性逐步提升,但小参数模型在面对复杂任务或罕见问题时,准确性相对较差,如 1.5B、7B、8B 模型可能在一些简单任务上表现尚可,但遇到复杂问题容易出错。
3.3、训练成本
模型参数越多,训练所需的计算资源、时间和数据量就越大。训练70B的模型需要大量的GPU计算资源和更长的训练时间,相比之下,1.5B的模型训练成本要低得多。
-
671B:训练需要大量的计算资源,如众多的高性能 GPU,训练时间极长,并且需要海量的数据来支撑,训练成本极高。
-
1.5B-70B:训练所需的计算资源和时间相对少很多,对数据量的需求也相对较小,训练成本较低。
3.4、推理成本
推理成本在实际应用中,推理阶段大模型需要更多的内存和计算时间来生成结果。例如在部署到本地设备或实时交互场景中,1.5B、7B等较小模型可能更容易满足低延迟、低功耗的要求,而 70B、32B等大模型可能需要更高性能的硬件支持,或者在推理时采用量化等技术来降低资源需求。
-
671B:推理时需要更多的内存来加载模型参数,生成结果的计算时间也较长,对硬件性能要求很高。
-
1.5B-70B:在推理时对硬件要求相对较低,加载速度更快,生成结果的时间更短,能更快速地给出响应。
3.5、适用场景
轻量级应用,需要快速响应需求可以选择1.5B、7B 这样的小模型可以快速加载和运行,能够在较短时间内给出结果,满足用户的即时需求,小模型适合一些对响应速度要求高、硬件资源有限的场景,如手机端的智能助手、简单的文本生成工具等;在科研、学术研究、专业内容创作等对准确性和深度要求较高的领域,选择70B、32B等大模型更适合。
-
671B:适用于对准确性和性能要求极高、对成本不敏感的场景,如大型科研机构进行前沿科学研究、大型企业进行复杂的商业决策分析等。
-
1.5B-7B:适合对响应速度要求高、硬件资源有限的场景,如移动端的简单智能助手、轻量级的文本生成工具等,可快速加载和运行。
-
8B-14B:可用于一些对模型性能有一定要求,但又没有超高性能硬件支持的场景,如小型企业的日常文本处理、普通的智能客服等。
-
32B-70B:能满足一些对准确性有较高要求,同时硬件条件相对较好的场景,如专业领域的知识问答系统、中等规模的内容创作平台等。
四、本地部署
环境:rocky9.5
4.1、安装Ollama
Ollama官网地址:Download Ollama on macOS
Ollama教程:Ollama 安装 | 菜鸟教程
curl -fsSL https://ollama.com/install.sh | shollama 修改监听0.0.0.0地址,要想被docker访问需要修改ollama监听的IP。
ollama可以通过环境变量OLLAMA_HOST设置监听的IP,但是通过.bashrc设置后重启ollama run命令监听IP并没有被修改。通过检查发现,ollama服务是systemctl启动的,需要的服务的配置里修改才可以。
vim /etc/systemd/system/ollama.service在文件中添加
Environment="OLLAMA_HOST=0.0.0.0:11434"
结果如下
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
[Install]
WantedBy=default.target然后重启ollama服务
systemctl daemon-reload
systemctl restart ollama.service4.2、下载并部署DeepSeek模型
下载并运行DeepSeek模型。例如,下载7B版本的命令为:
ollama run deepseek-r1:7b4.3、启动Ollama服务(可选):
在终端运行以下命令启动Ollama服务:
ollama serve服务启动后,可以通过访问 http://IP:11434 来与模型进行交互。
4.4、使用Open Web UI
Open-WebUI官网(https://openwebui.com),教程:🏡 Home | Open WebUI
为了更直观地与DeepSeek模型进行交互,可以使用Open Web UI。以下是安装和使用步骤:
-
安装Docker:确保你的机器上已安装Docker。
-
运行Open Web UI:
在终端运行以下命令安装并启动Open Web UI:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main五、使用
5.1、通过web页面使用
首次部署后等五分钟之后访问web页面,http://IP:3000/ 根据提示创建管理员账户,登录然后登录使用
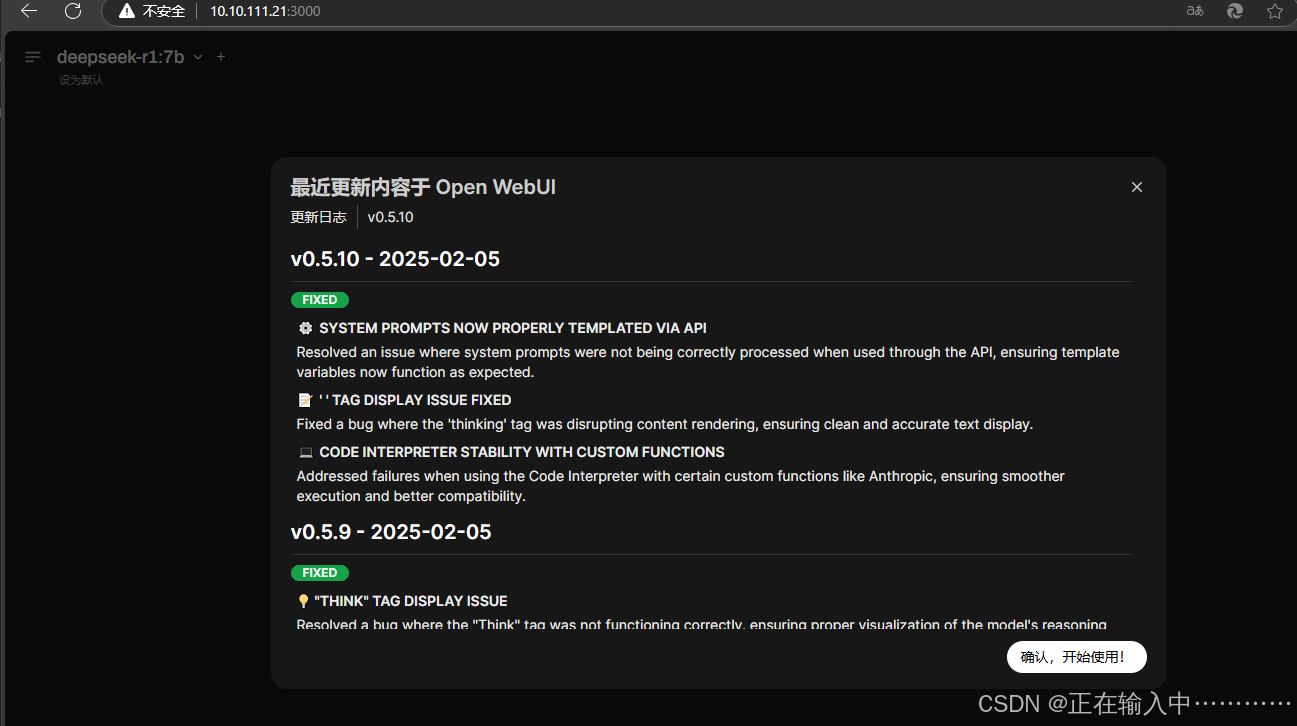
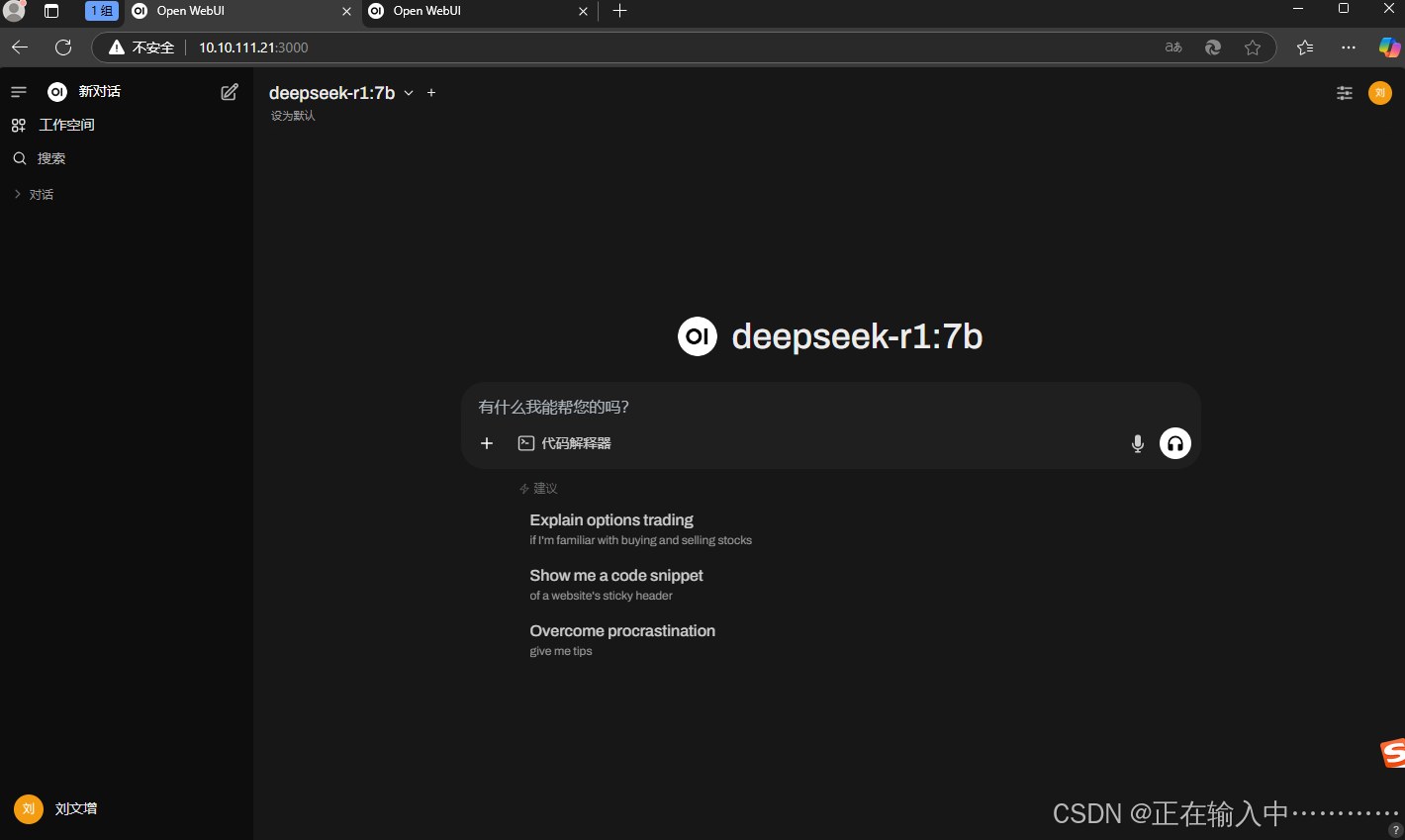
5.2、通过客户端使用
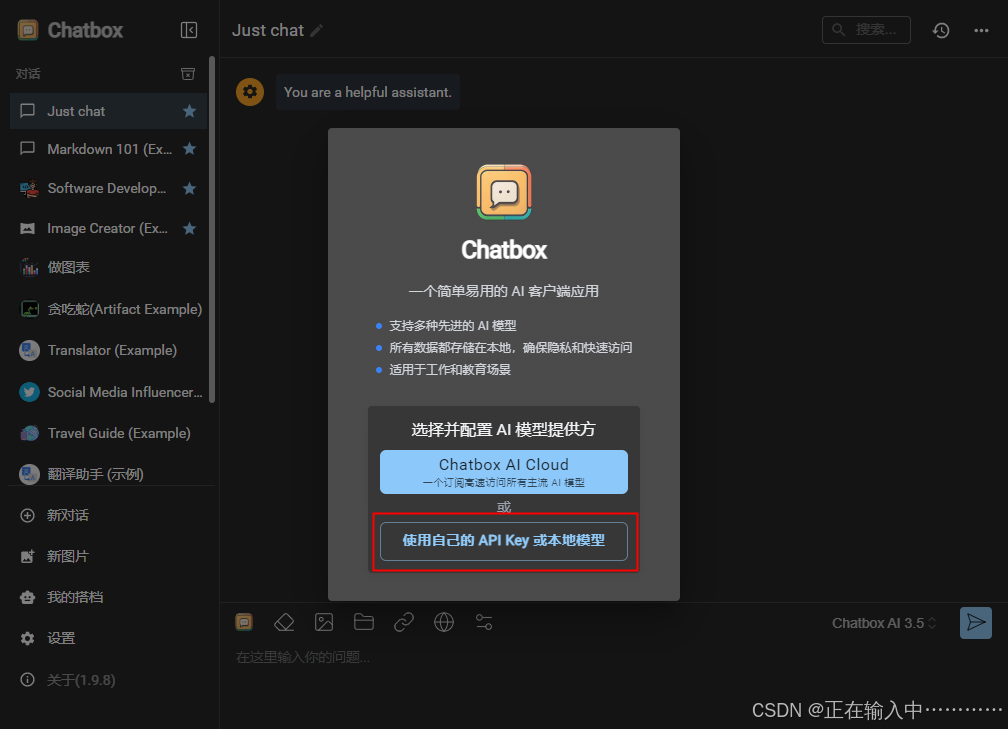
安装 Chatbox,官网:Chatbox AI: Your AI Copilot, Best AI Client on any device, Free Download
为了获得更好的交互体验,可以安装 Chatbox 作为 GUI 界面。
-
下载地址:https://chatboxai.app/en#
-
安装完成后,进行以下配置:
-
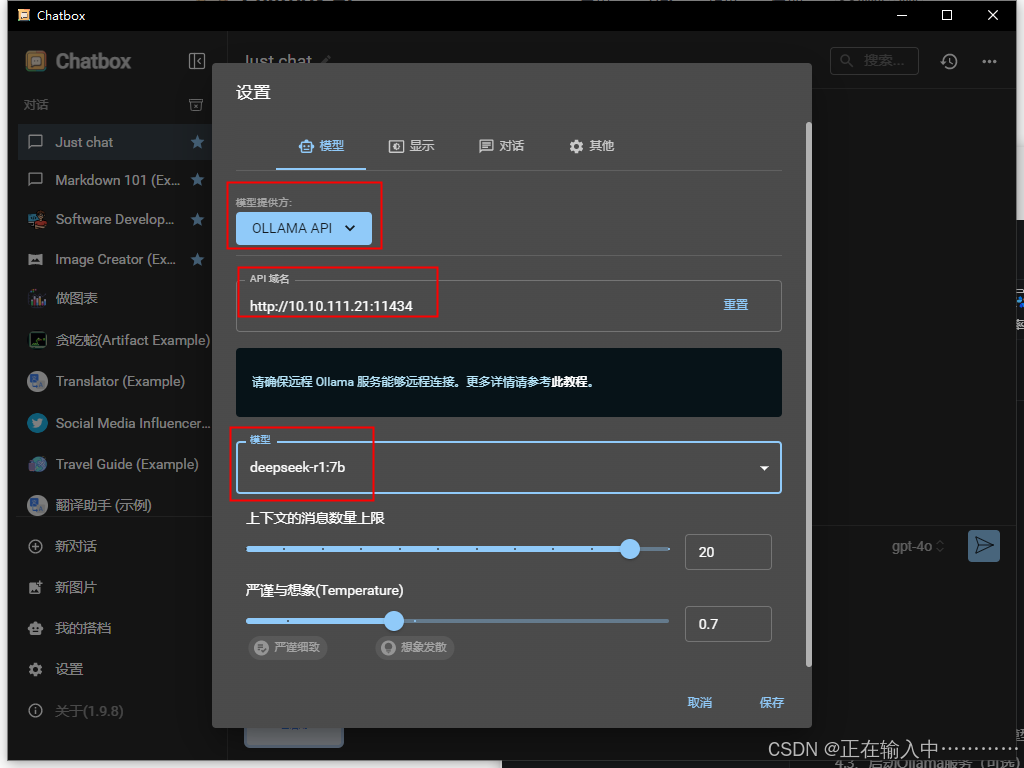
在“配置 API 模型”选项中选择 Ollama API。
-
设置 API 主机为:http://IP:11434
-
选择 DeepSeek R1 作为默认模型。
-
保存设置。
-



















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











