



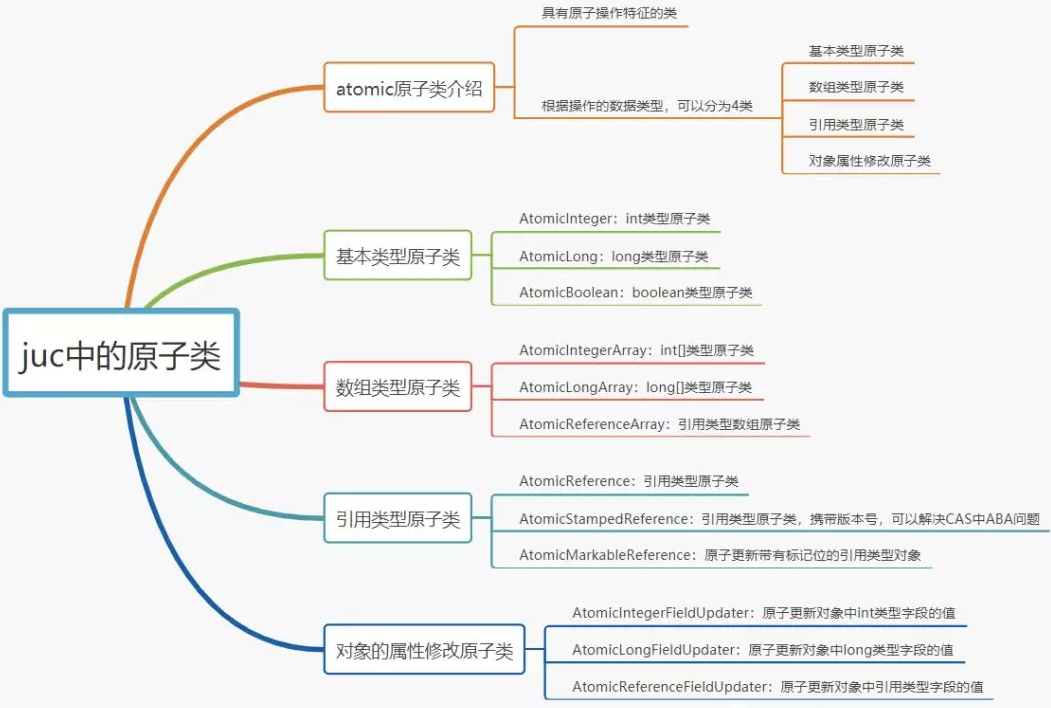
一、原子类简介
在我们这里 atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰,所以,所谓原子类说简单点就是具有原子操作特征的类,原子操作类提供了一些修改数据的方法,这些方法都是原子操作的,在多线程情况下可以确保被修改数据的正确性
这些类位于java.util.concurrent.atomic包中
二、基本类型原子类
简介
使用原子的方式更新基本类型
- AtomicInteger:int类型原子类
- AtomicLong:long类型原子类
- AtomicBoolean :boolean类型原子类
上面三个类提供的方法几乎相同,这里以 AtomicInteger 为例子来介绍
AtomicInteger 类常用方法
public final int get()//获取当前的值
public final int getAndSet(int newValue)//获取当前的值,并设置新的值
public final intgetAndIncrement()//获取当前的值,并自增
public final intgetAndDecrement()//获取当前的值,并自减
public final intgetAndAdd(int delta)//获取当前的值,并加上预期的值
boolean compareAndSet(int expect, int update)//如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
public final voidlazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值
部分源码
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
2个关键字段说明:
value:使用volatile修饰,可以确保value在多线程中的可见性。
valueOffset:value属性在AtomicInteger中的偏移量,通过这个偏移量可以快速定位到value字段,这个是实现AtomicInteger的关键。
getAndIncrement源码:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
内部调用的是Unsafe类中的getAndAddInt方法,我们看一下getAndAddInt源码:
// var1是this, var4是1, var2是旧的预期值
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
//var5是新的真实值
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
说明:
this.getIntVolatile:可以确保从主内存中获取变量最新的值。
compareAndSwapInt:CAS操作,CAS的原理是拿期望的值和原本的值作比较,如果相同则更新成新的值,可以确保在多线程情况下只有一个线程会操作成功,不成功的返回false。
上面有个do-while循环,compareAndSwapInt返回false之后,会再次从主内存中获取变量的值,继续做CAS操作,直到成功为止。
getAndAddInt操作相当于线程安全的count++操作,如同:
synchronize(lock){
count++;
}
count++操作实际上是被拆分为3步骤执行:
1. 获取count的值,记做A:A=count
2. 将A的值+1,得到B:B = A+1
3. 让B赋值给count:count = B
多线程情况下会出现线程安全的问题,导致数据不准确。
synchronize的方式会导致占时无法获取锁的线程处于阻塞状态,性能比较低。CAS的性能比synchronize要快很多。
三、数组类型原子类
简介
使用原子的方式更新数组里的某个元素,可以确保修改数组中数据的线程安全性。
- AtomicIntegerArray:整形数组原子操作类
- AtomicLongArray:长整形数组原子操作类
- AtomicReferenceArray :引用类型数组原子操作类
上面三个类提供的方法几乎相同,所以我们这里以 AtomicIntegerArray 为例子来介绍
AtomicIntegerArray类常用方法
public final int get(int i)//获取 index=i 位置元素的值
public final int getAndSet(int i, int newValue)//返回 index=i 位置的当前的值,并将其设置为新值:newValue
public final int getAndIncrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自增
public final int getAndDecrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自减
public final int getAndAdd(int delta)//获取 index=i 位置元素的值,并加上预期的值
boolean compareAndSet(int expect, int update)//如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
public final void lazySet(int i, int newValue)//最终 将index=i 位置的元素设置为newValue,使用 lazySet 设置之后可能导
四、引用类型原子类
简介
基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用 引用类型原子类。
- AtomicReference:引用类型原子类
- AtomicStampedRerence:原子更新引用类型里的字段原子类
- AtomicMarkableReference:原子更新带有标记位的引用类型
AtomicReference和AtomicInteger非常类似,不同之处在于AtomicInteger是对整数的封装,而AtomicReference则是对应普通的对象引用,它可以确保你在修改对象引用时的线程安全性。在介绍AtomicReference的同时,我们先来了解一个有关原子操作逻辑上的不足。
ABA问题
之前我们说过,线程判断被修改对象是否可以正确写入的条件是对象的当前值和期望值是否一致。这个逻辑从一般意义上来说是正确的,但是可能出现一个小小的例外,就是当你获得当前数据后,在准备修改为新值钱,对象的值被其他线程连续修改了两次,而经过这2次修改后,对象的值又恢复为旧值,这样,当前线程就无法正确判断这个对象究竟是否被修改过,这就是所谓的ABA问题,可能会引发一些问题。
AtomicStampedReference
创建
AtomicStampedReference<String> asr=new AtomicStampedReference("djy",0);
源码为:

注:
这里可以看出AtomicStampedReference能够解决所谓的ABA问题,很简单版本号控制
解决ABA问题
/**
* 类说明:演示带版本戳的原子操作类
*/
public class UseAtomicStampedReference {
static AtomicStampedReference<String> asr
= new AtomicStampedReference("djy", 0);
public static void main(String[] args) throws InterruptedException {
//拿到当前的版本号(旧)
final int oldStamp = asr.getStamp();
final String oldReference = asr.getReference();
System.out.println(oldReference + "============" + oldStamp);
Thread rightStampThread = new Thread(new Runnable() {
@Override
public void run() {
asr.compareAndSet(oldReference, "java", oldStamp, oldStamp + 1);
}
});
Thread errorStampThread = new Thread(new Runnable() {
@Override
public void run() {
String reference = asr.getReference();
int stamp = asr.getStamp();
asr.compareAndSet(reference, "C++", stamp, stamp + 1);
}
});
rightStampThread.start();
//让线程充分运行完毕
rightStampThread.join();
errorStampThread.start();
errorStampThread.join();
System.out.println(asr.getReference() + "============" + asr.getStamp());
}
}
AtomicMarkableReference
用法与AtomicStampedReference基本一致
AtomicMarkableReference 与 AtomicStampedReference的区别?
AtomicStampedReference
构造方法中initialStamp(时间戳)用来唯一标识引用变量,在构造器内部,实例化了一个Pair对象,Pair对象记录了对象引用和时间戳信息,采用int作为时间戳,实际使用的时候,要保证时间戳唯一(一般做成自增的),如果时间戳如果重复,还会出现ABA的问题。
AtomicStampedReference中的每一个引用变量都带上了pair.stamp这个时间戳,这样就可以解决CAS中的ABA的问题。
/**
* Creates a new {@code AtomicStampedReference} with the given
* initial values.
*
* @param initialRef the initial reference
* @param initialStamp the initial stamp
*/
public AtomicStampedReference(V initialRef, int initialStamp) {
pair = Pair.of(initialRef, initialStamp);
}
AtomicMarkableReferenceAtomicStampedReference可以知道,引用变量中途被更改了几次。有时候,我们并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了AtomicMarkableReference。
AtomicMarkableReference的唯一区别就是不再用int标识引用,而是使用boolean变量——表示引用变量是否被更改过。
构造函数
/**
* Creates a new {@code AtomicMarkableReference} with the given
* initial values.
*
* @param initialRef the initial reference
* @param initialMark the initial mark
*/
public AtomicMarkableReference(V initialRef, boolean initialMark) {
pair = Pair.of(initialRef, initialMark);
}


















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









