







单模式匹配
单模式字符串匹配就是一个字符串a和另一个字符串b进行匹配,一般而言,a的长度n远大于b的长度m,我们在a中查找是否包含b。我们将字符串a称为主串,字符串b称为模式串。
1. 暴力匹配的BF算法
BF算法成为暴力匹配算法,又叫做朴素匹配算法。也是最简单的,我们经常用到的算法。最简单的方法就是每次比对m个字符,最坏情况下比较n-m+1次,BF算法的最坏情况时间复杂度为O(n*m)。
2. RK算法(基于哈希算法的BF算法优化方案)
RK算法是在BF算法的基础上进行改进,在字符串匹配时加入哈希算法的思想。
RK 算法的思路:我们通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后逐个与模式串的哈希值比较大小。如果某个子串的哈希值与模式串相等,则说明对应的子串和模式串匹配了。
不过,对于这种在字符串中加入哈希算法的思想在具体的实现方案上还有一些地方需要考虑。我们暂时不作展开,因为暂时用不到,以后如果真用到了,再进行展开。
整个RK算法的时间复杂度分析我们分为两个部分,计算每个子串的哈希值和子串的哈希值之间的比较。
代码中循环复杂度O(n),hash结果相等时的逐字符匹配复杂度为O(m),整体时间复杂度为O(m+n)。空间复杂度为O(1)
结论:RK算法的时间复杂度时O(n+m)
3. Sunday算法

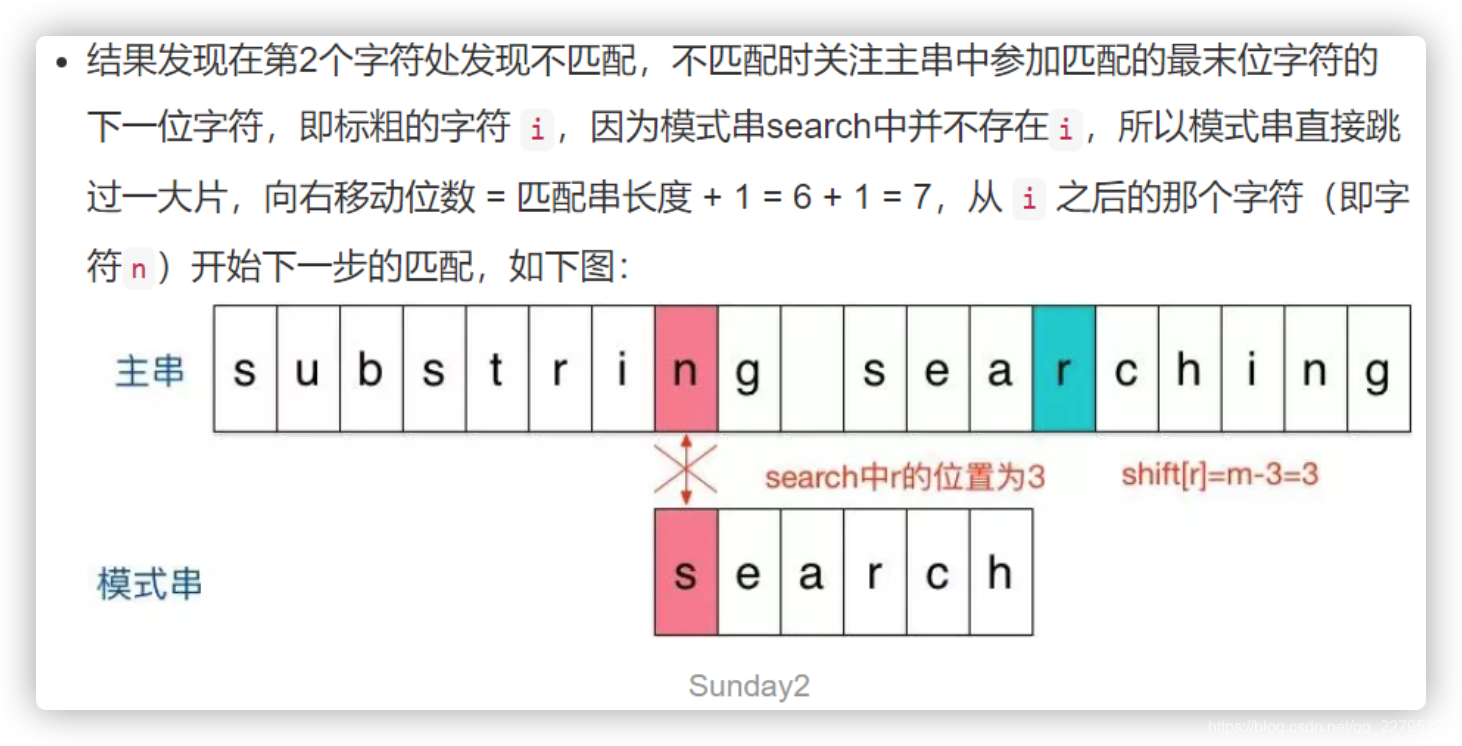
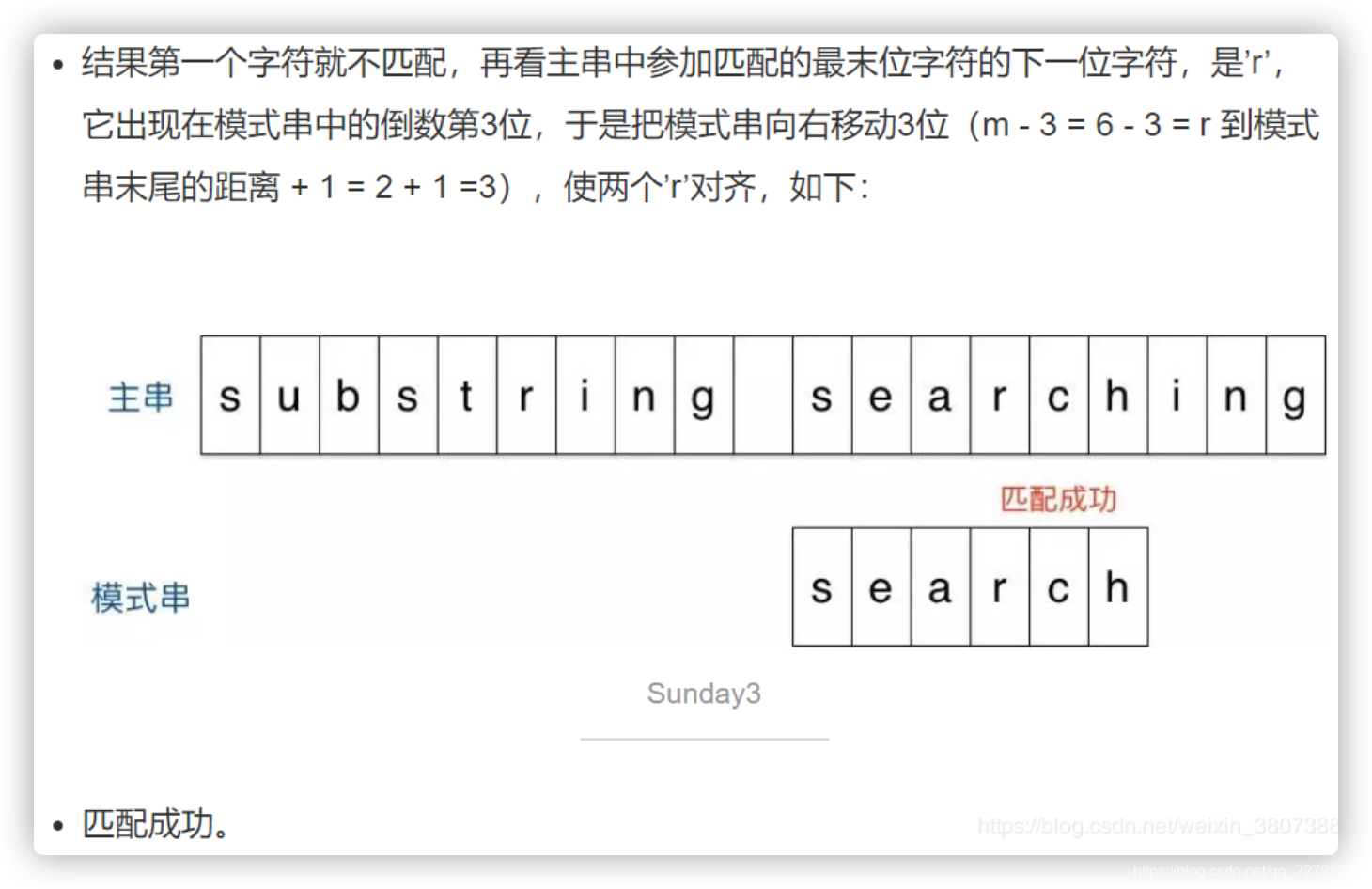
4. BM算法

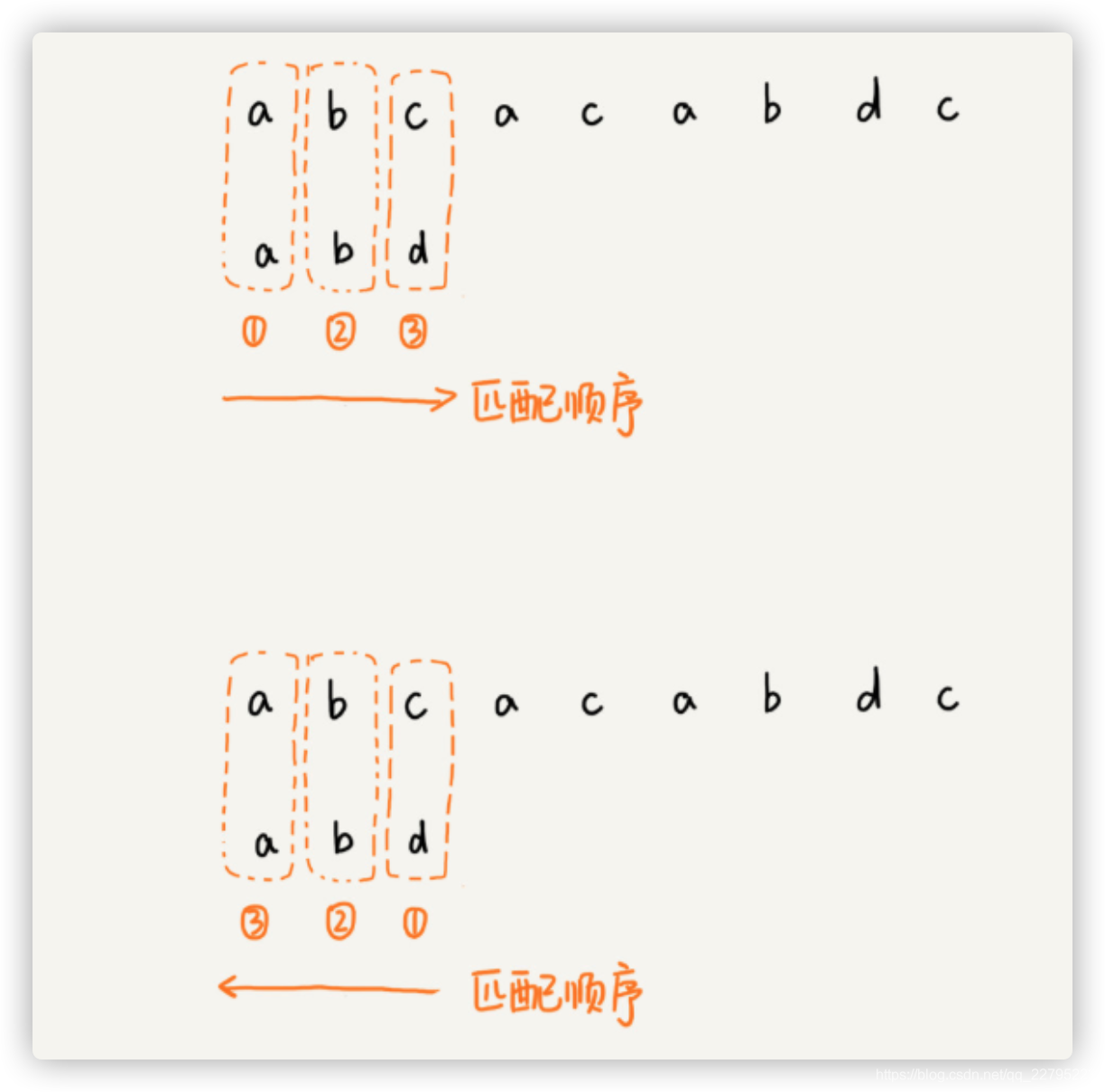
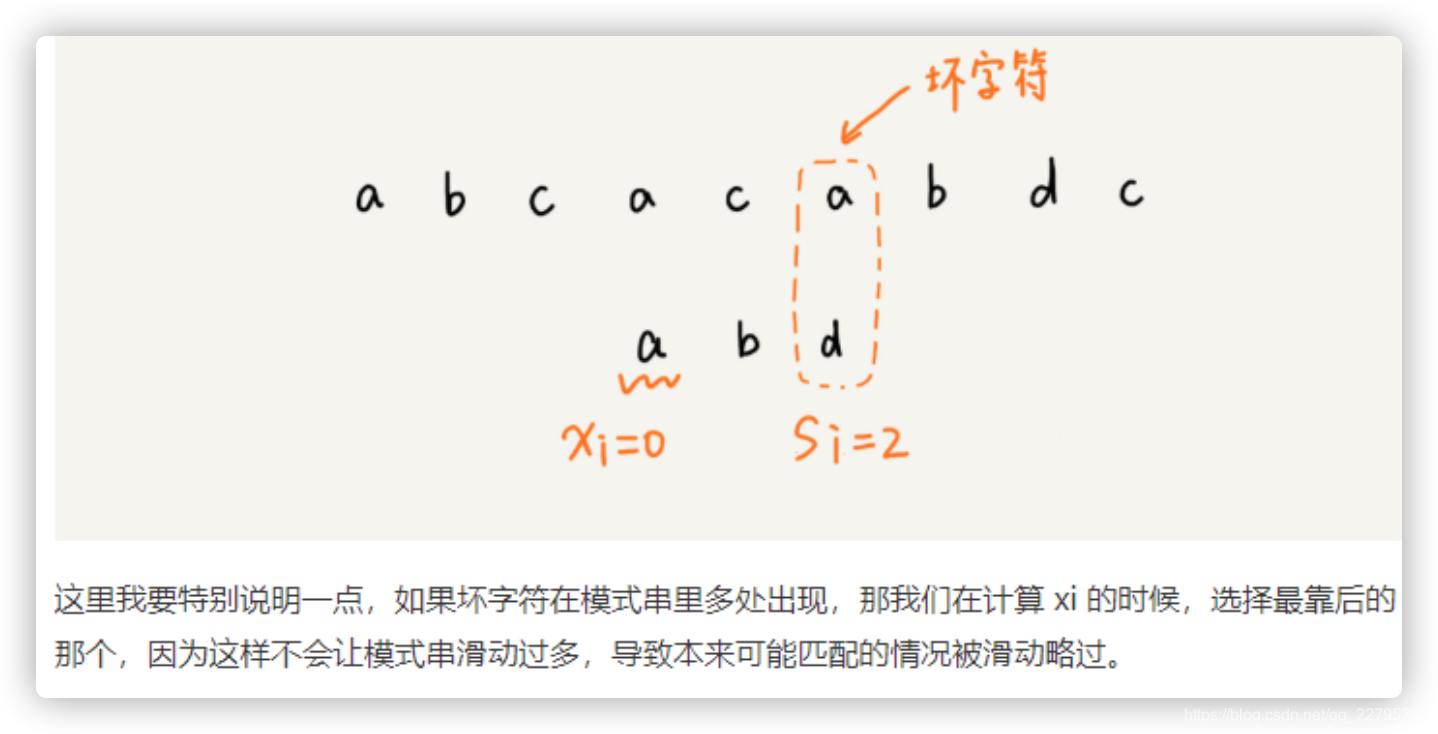
1. 坏字符规则


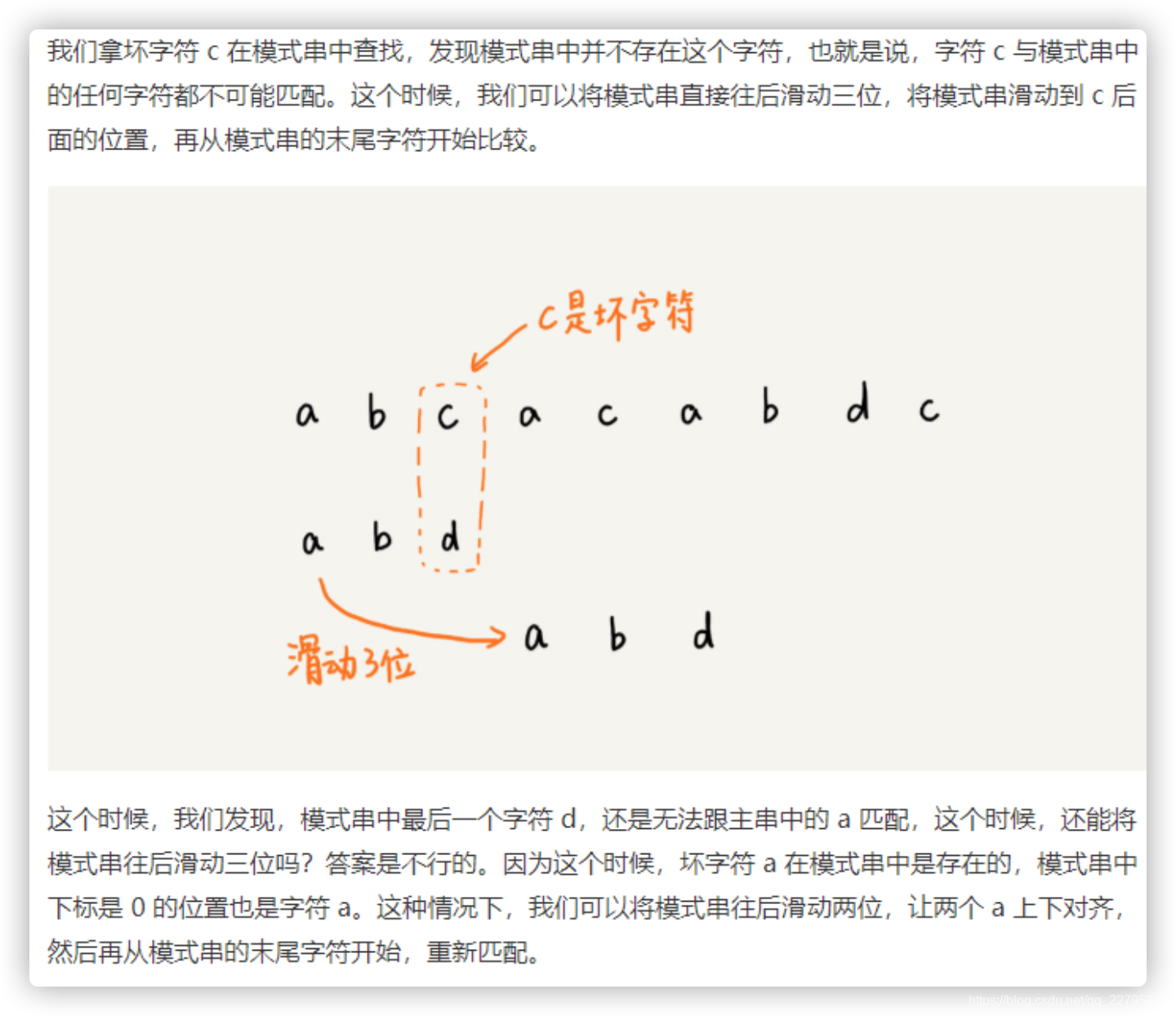


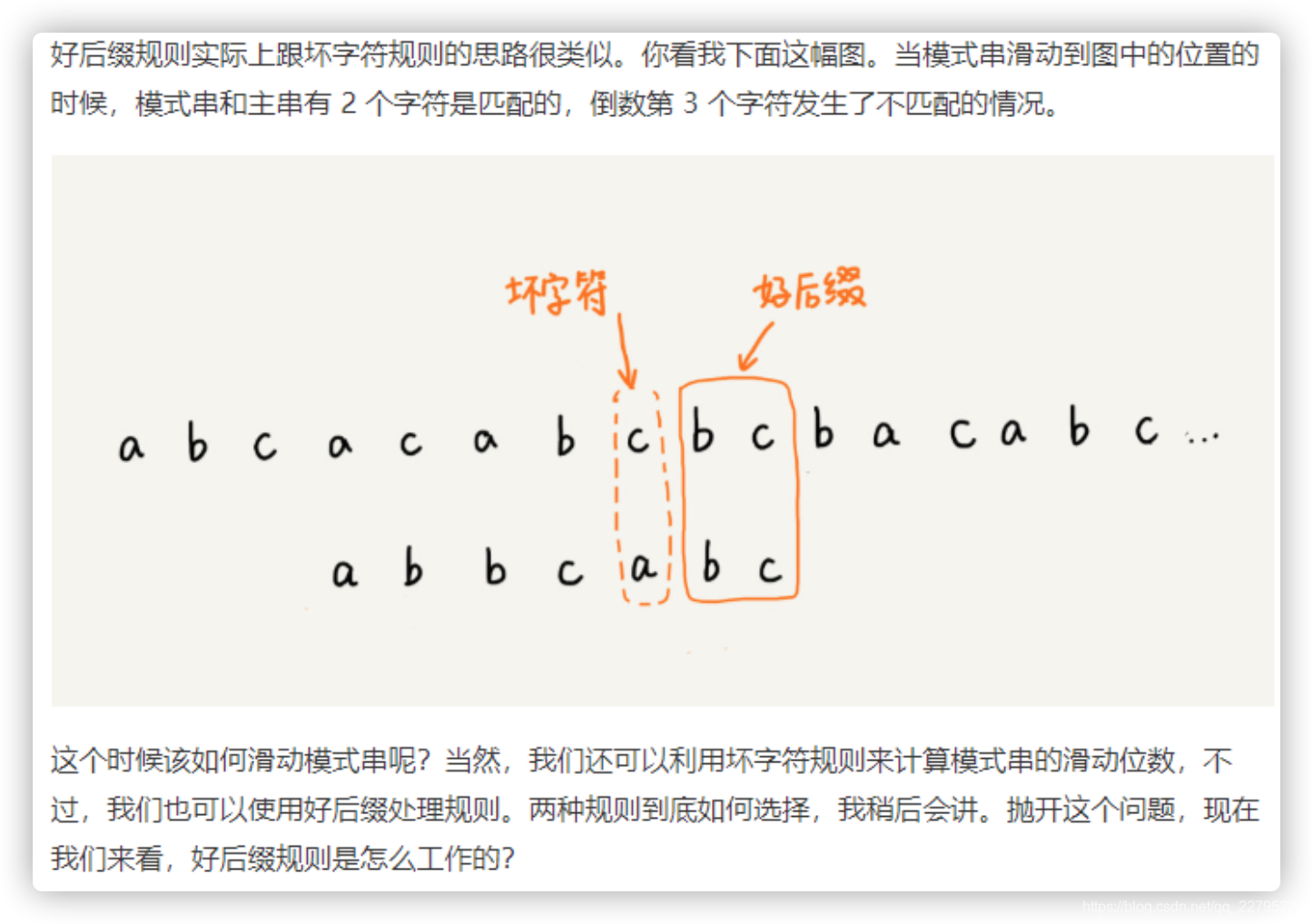
2. 好后缀规则
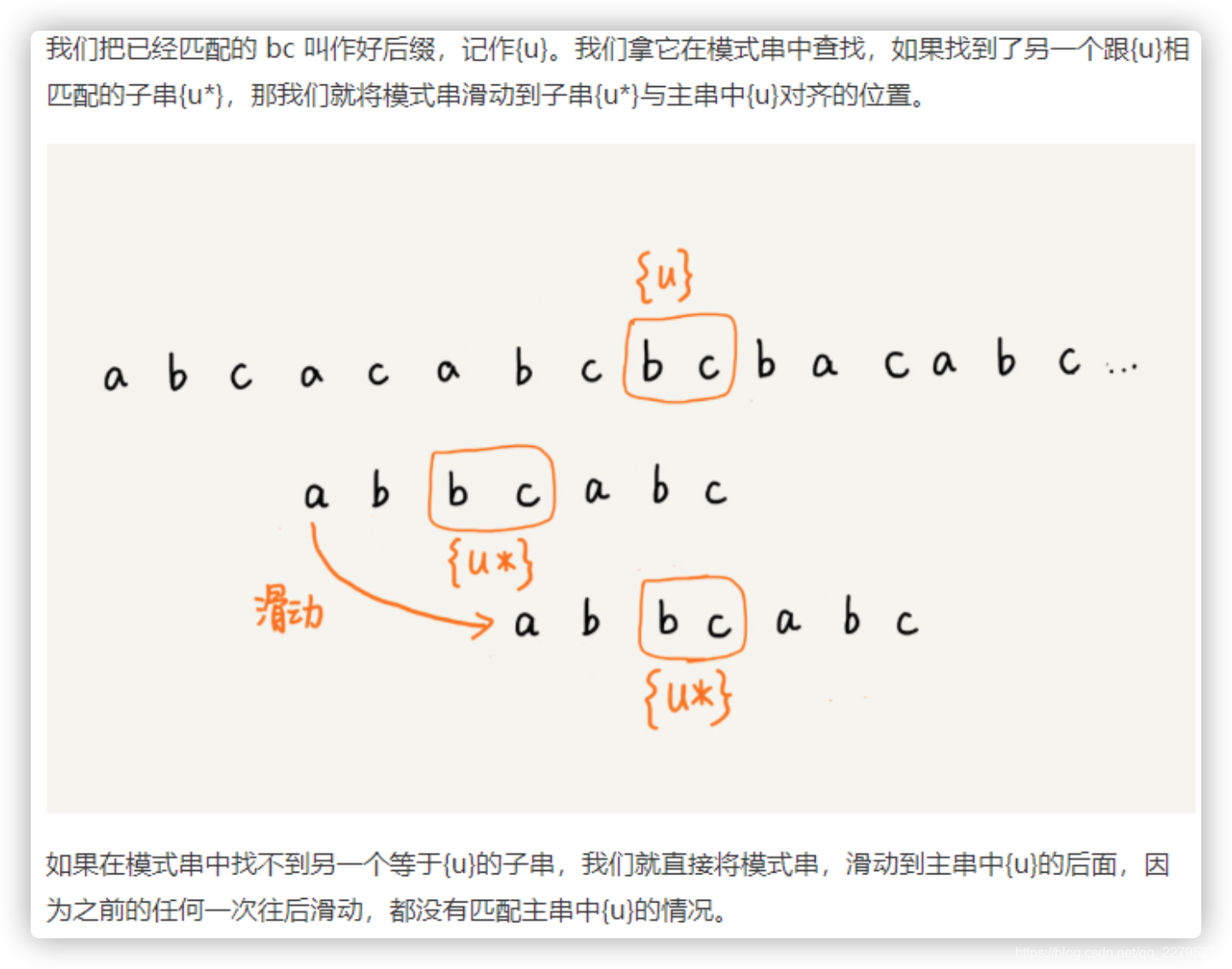
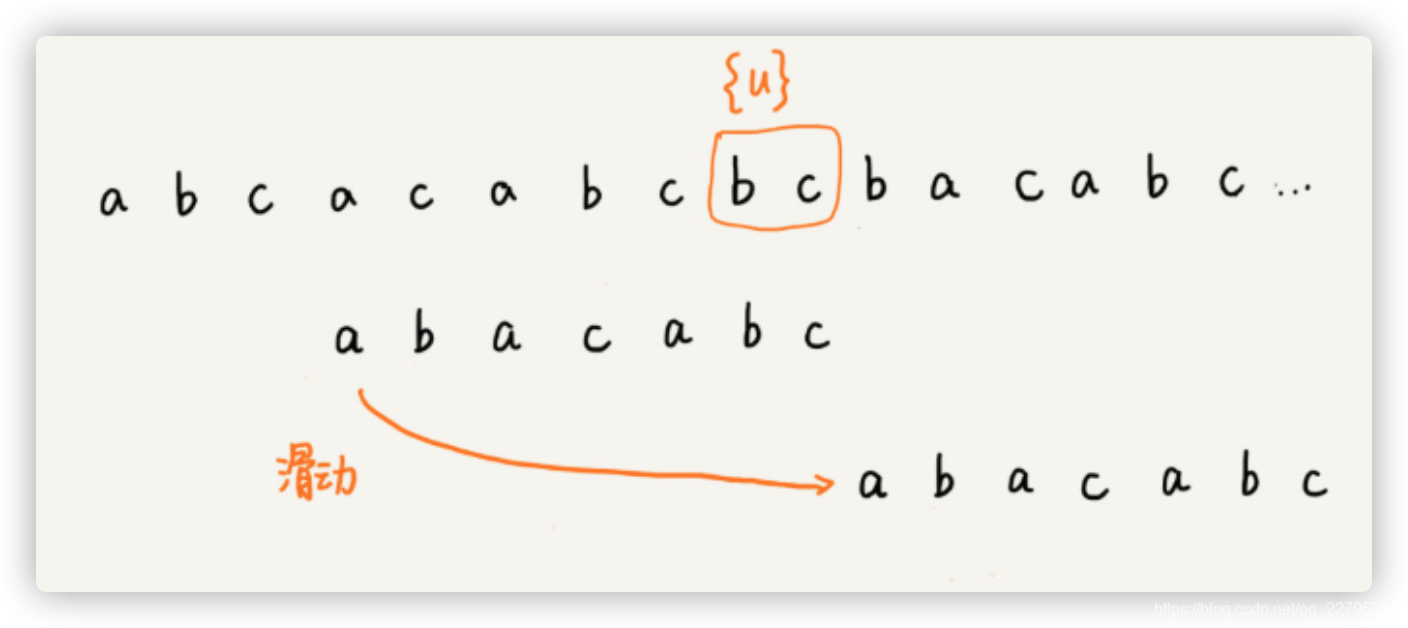


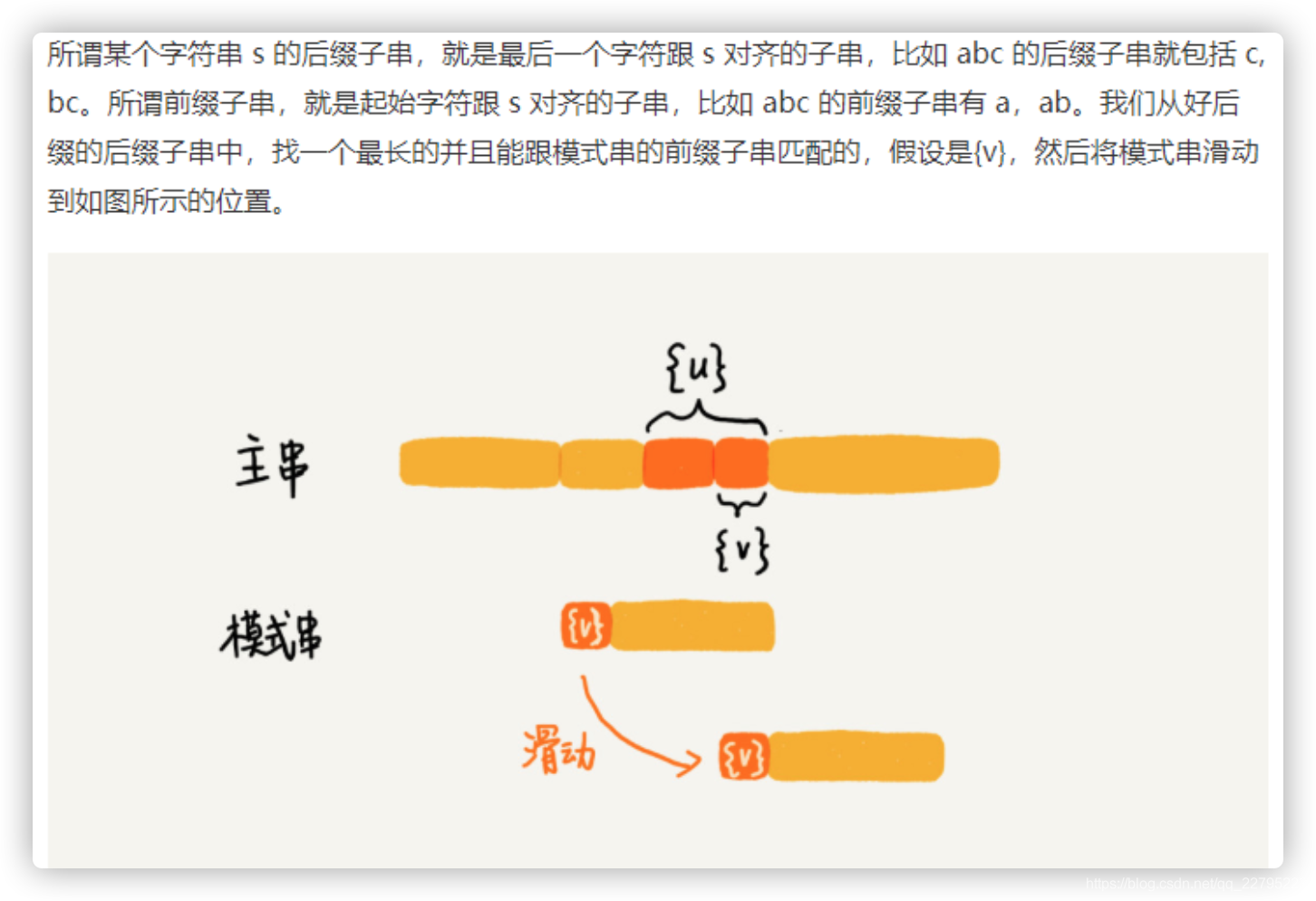

小结:BM算法的核心思想就是利用主串和模式串在匹配过程中的坏后缀 好后缀原则,当主串和模式串发生不匹配时,能够跳过一些不必要的比较过程。后面还会将讲一个KMP算法,它与BM算法在很多地方十分相似。
BM算法的平均时间复杂度O(n),它属于典型空间换时间的算法。
在整个算法中,他需要用到额外的3个数组,其中bc数组的大小和字符集大小有关,suffix数组和prefix数组的大小和模式串长度有关。
5. KMP算法

先从整体看一下KMP算法的过程:
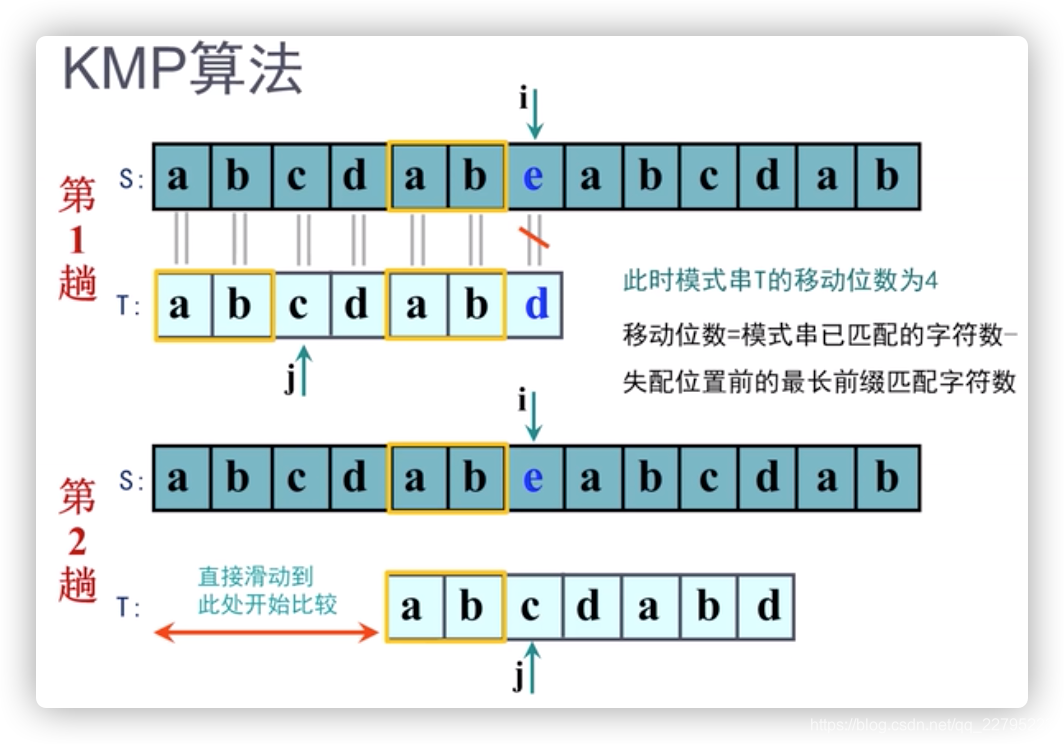
首先从前往后逐个匹配,直到e和d,发现失配情况,此时采取“敌动我不动”策略,即i不动,j动的策略,这里先不考虑j的索引变成了多少,我们考虑模式串整体向后移动了多少位数,这体现了KMP算法的效率。我们观察模式串的前缀与后缀具有重合的部分ab,那么模式串的移动位数=模式串已匹配的字符数6-失配位置前的最长前缀匹配字符数2=4,所以模式串移动位数为4。
那么从整体理解的角度,我们可以得出KMP算法的一个小总结:

那么移动的位数的确很大,但是移动这么多,真的可以吗?
通过简单的小学数学证明可以得出结论,但这里不做展开。

需要讨论的这两个问题,可以理解为:
- 如何确定j的index?
- 滑多远斜率最高?
我们引入新的东西,来进一步细节化KMP算法,解决这两个问题:


注意是0到j-1构成的串。
那么接下来,我们把next数组引入来讲解KMP算法的完整过程,如下图:
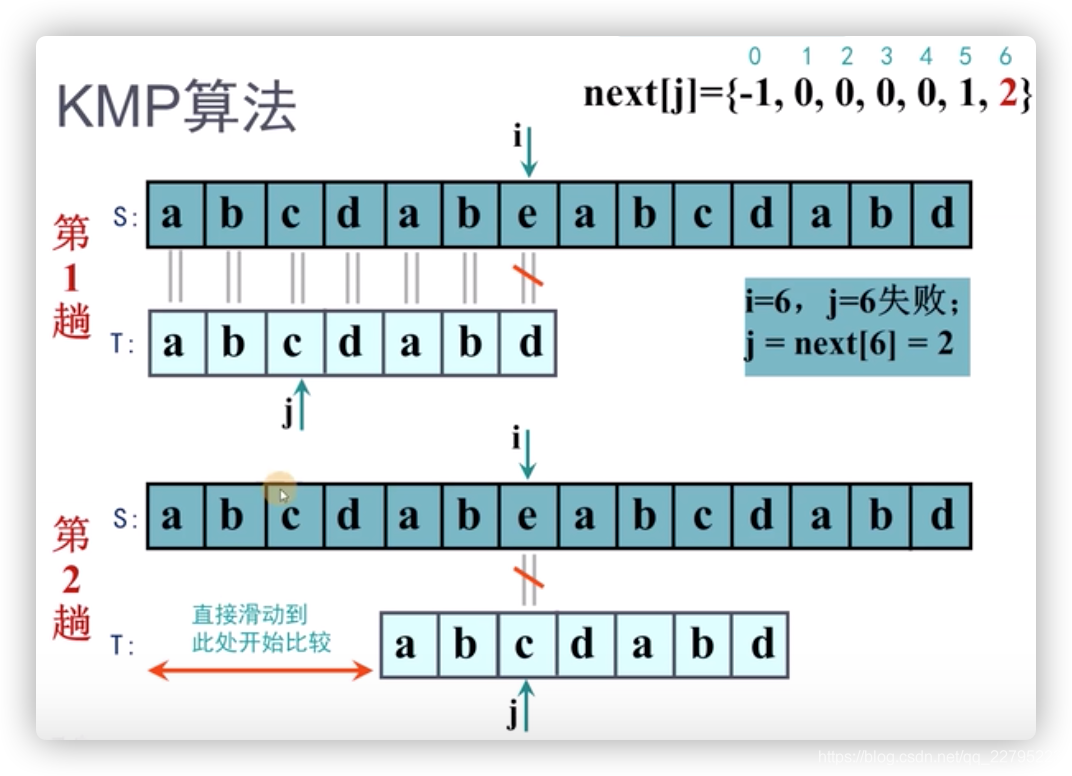
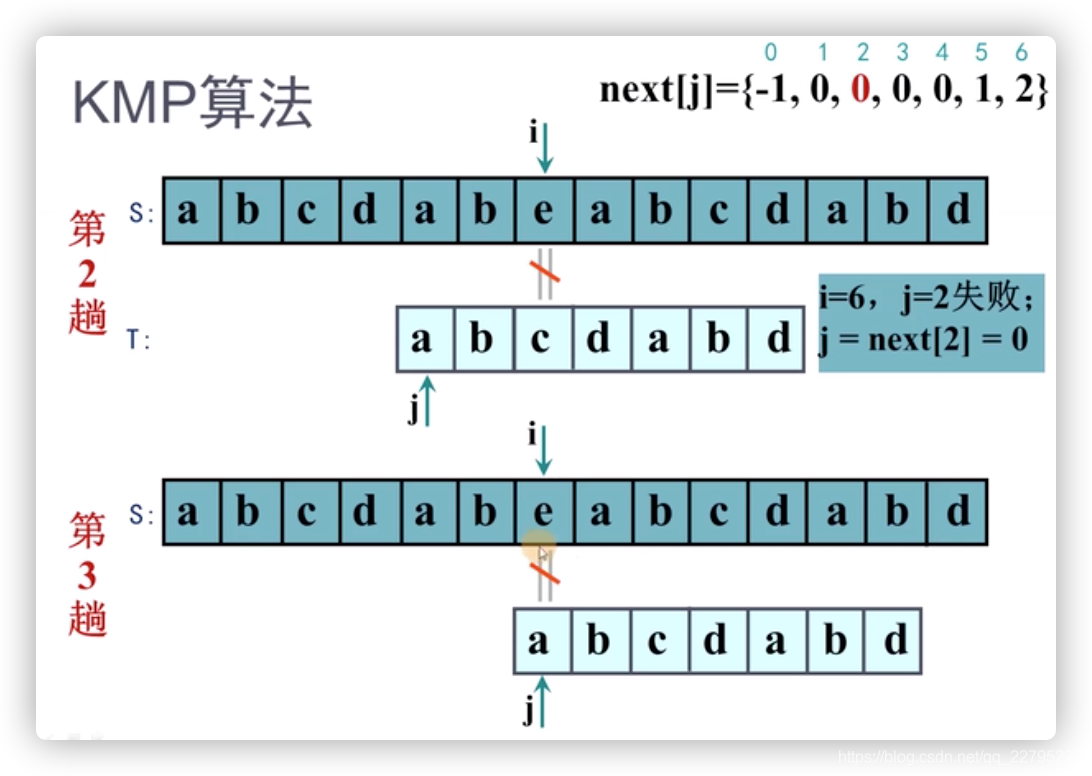
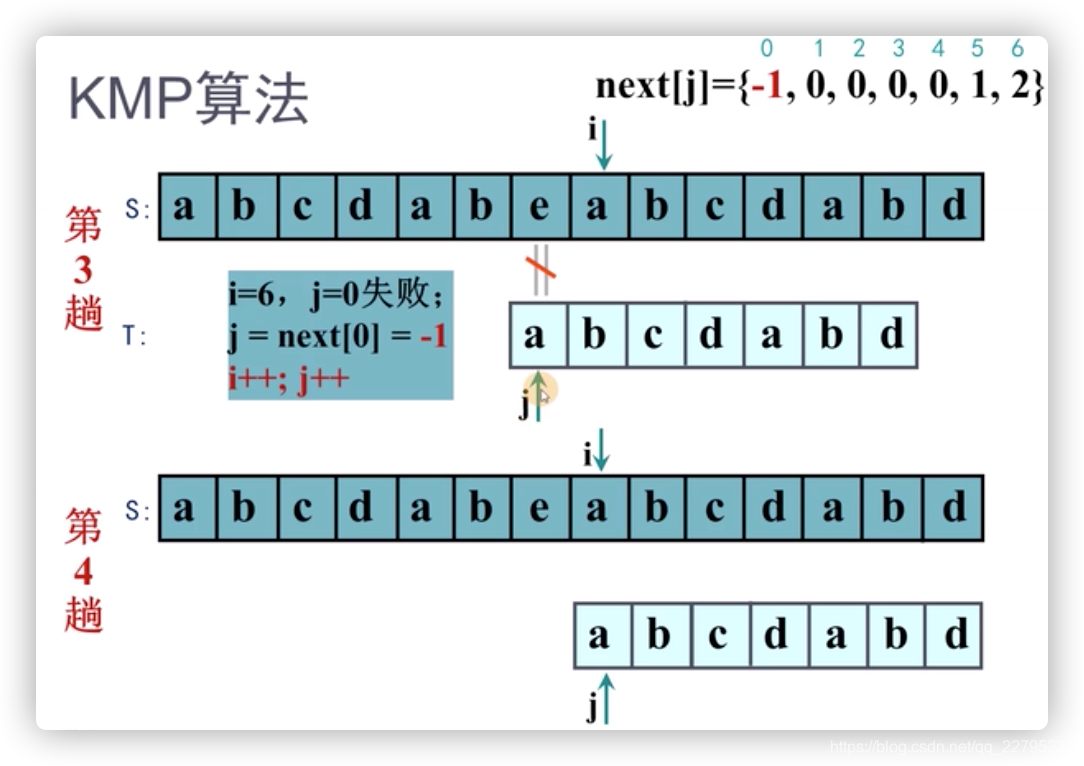
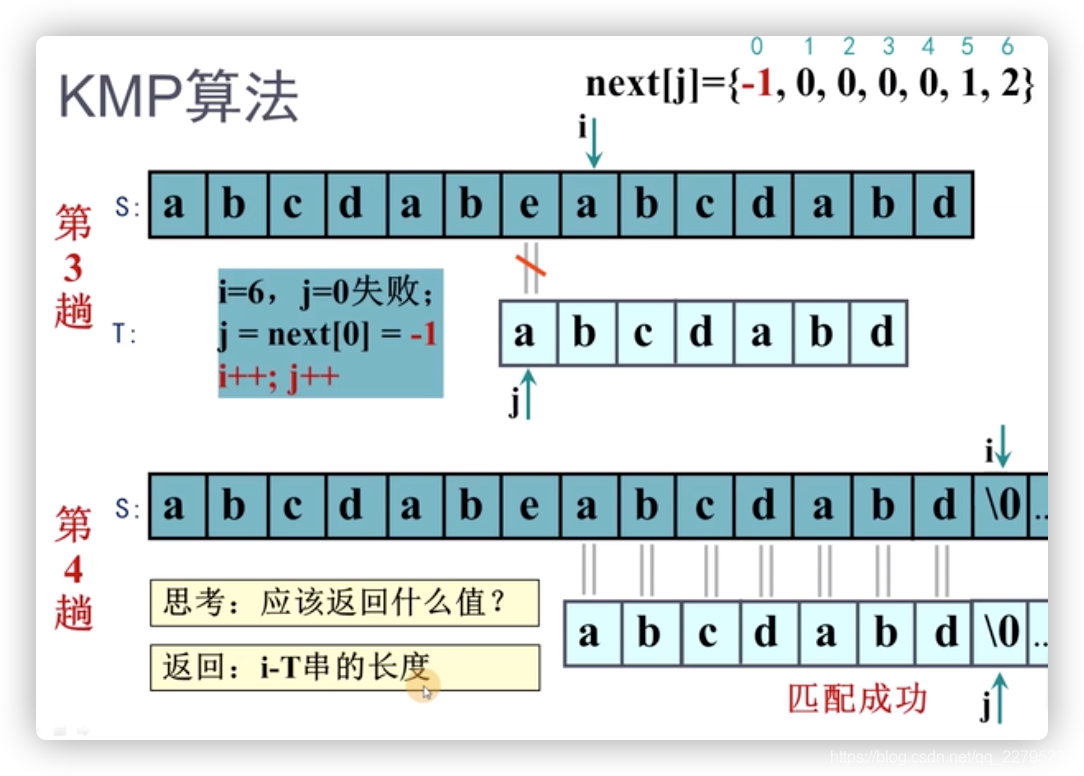
最后,上伪代码描述:

BF算法与KMP算法代码的比较:

再附上求next数组的伪代码:

该代码虽然和KMP算法本身的代码相似,但实际算法思路是很不同的,非常的巧妙,甚至让人很茫然,可以自己画图算一下这个代码思路过程,会发现得出的结果真的就是如图的目标结果。




















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











