







引言
Transformer 模型在自然语言处理(NLP)和计算机视觉(CV)领域取得了巨大成功,但其核心组件 Self-Attention 的计算复杂度为 O(N^2)(N 是序列长度),导致长序列处理时面临显存和计算瓶颈。
2022年,斯坦福团队提出 FlashAttention,通过优化内存访问和计算方式,显著提升了注意力机制的效率,同时保持精确计算(无需近似)。如今,FlashAttention 已成为大模型(如GPT-4、LLaMA-2)处理长上下文(16K+ tokens)的关键技术。
本文将深入解析 FlashAttention 的原理、优化策略,并给出 PyTorch 代码示例。
目录
1 传统Self-Attention的瓶颈
标准 Self-Attention 的计算步骤如下:
(1)计算QK ^T,(矩阵乘法,复杂度 为 O(N^2).
(2)QK ^T应用Softmax(逐行归一化)。
(3)与 V 相乘得到输出O=Softmax(QK^T)V.
主要问题:
显存占用高:需存储中间矩阵 QK^T(形状 N×N),显存峰值需求为 O(N^2)。
内存访问慢:GPU 显存(HBM)带宽有限,频繁读写大矩阵导致速度瓶颈。
2. FlashAttention的核心优化
FlashAttention 通过以下技术优化计算:
(1) 分块计算(Tiling)
将 QK^T矩阵拆分为小块(Tiles),每次只加载一小部分到 GPU 高速缓存(SRAM) 计算。
避免一次性存储整个 N×N 矩阵,显存占用降至 O(N)。
(2) 算子融合(Kernel Fusion)
将 Softmax、Masking、Dropout 等操作融合到单个 CUDA 核函数中,减少显存读写次数。
传统实现:每个操作需单独读写显存 → 多次 IO 开销。
FlashAttention:所有操作在 SRAM 中完成,最后只写回最终结果。
(3) 反向传播重计算(Recomputation)
前向传播时不保存中间矩阵(如QK^T),而是在反向传播时重新计算。
牺牲少量计算时间,大幅降低显存占用(类似梯度检查点技术)。
3. FlashAttention 计算流程(简化版)
分块加载:将 Q、K、VV切分为多个小块(如 Q1,Q2 和 K1,K2)。
局部计算:
计算 Q1K1^T,得到局部注意力分数。
应用 在线 Softmax(避免存储整个矩阵)。
全局合并:
通过迭代修正合并各块结果,保证数值稳定性。
4. FlashAttention-2 的改进
2023年推出的 FlashAttention-2 进一步优化:
(1)减少非矩阵乘法运算(如 Softmax)的开销。
(2)改进 GPU 任务调度,提升并行度(尤其针对 A100/H100)。
(3)速度比第一代提升约 2倍。
5. 代码示例
import torch
from torch.nn.functional import scaled_dot_product_attention
# 输入:q, k, v (形状 [batch_size, seq_len, num_heads, head_dim])
q = torch.randn(2, 4096, 8, 64) # 假设序列长度=4096
k = torch.randn(2, 4096, 8, 64)
v = torch.randn(2, 4096, 8, 64)
# 使用 FlashAttention(自动启用,若硬件支持)
attn_output = scaled_dot_product_attention(
q, k, v,
attn_mask=None, # 可选的注意力掩码
dropout_p=0.1, # 可选 dropout
is_causal=True, # 是否自回归(因果掩码)
)
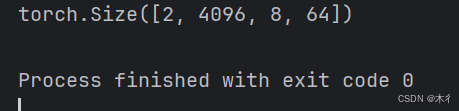
print(attn_output.shape) # [2, 4096, 8, 64]
输出:
关键参数说明:
is_causal=True:启用因果掩码(适用于自回归生成,如 GPT)。
dropout_p=0.1:在注意力权重上应用 Dropout。
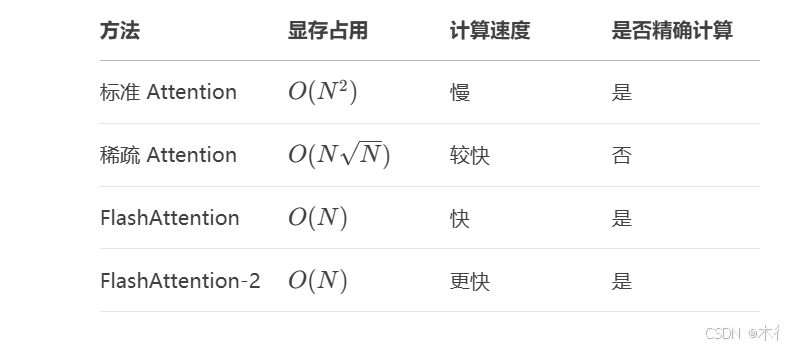
6. 性能对比
7. 应用场景
长文本建模:支持 16K~128K token 的上下文窗口(如 Claude、GPT-4)。
大模型训练:降低显存需求,允许更大 Batch Size。
推理加速:提升生成式模型的吞吐量。
总结
lashAttention 通过 硬件感知的算法设计(IO-Aware),优化了 GPU 显存访问模式,在 不改变数学结果 的前提下,大幅提升注意力计算的效率。它的出现使得 Transformer 模型能够更高效地处理长序列,成为现代大语言模型(LLM)的核心技术之一。


















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











