




 本文探讨了Hive与MySQL间Null存储不一致问题,如何通过sqoop处理空值、特殊字符和数据导入一致性,包括使用--staging-table、--fetch-size和--num-mappers。还重点讲解了如何避免数据倾斜,通过自定义split-by和boundary-query来优化并行导入。
本文探讨了Hive与MySQL间Null存储不一致问题,如何通过sqoop处理空值、特殊字符和数据导入一致性,包括使用--staging-table、--fetch-size和--num-mappers。还重点讲解了如何避免数据倾斜,通过自定义split-by和boundary-query来优化并行导入。
一、导入 导出 Null 存储 一致性问题
Hive 中的 Null 在底层是以“\N”来存储,而 MySQL 中的 Null 在底层就是 Null,为了保证数据两端的一致性。
- 导出数据时采用--input-null-string 和--input-null-non-string 两个参数。
- 导入数据时采用--null-string 和--null-non-string。
1、mysql导入hive 数值类型变成null的问题
mysql中没有boolean类型,boolean在MySQL里的类型为tinyint(1),
例:
create table xs
(
id int primary key,
bl boolean
)这样是可以创建成功,但查看一下建表后的语句,就会发现,mysql把它替换成tinyint(1)。
也就是说mysql把boolean=tinyInt了。
MYSQL保存boolean值时用1代表TRUE, 0代表FALSE,boolean在MySQL里的类型为tinyint(1)
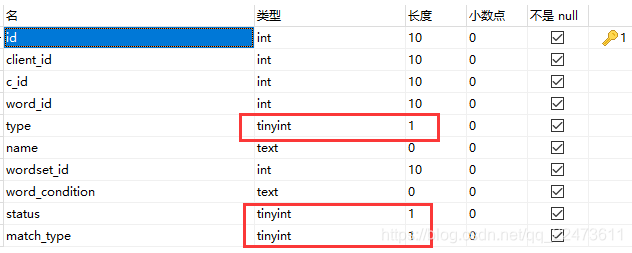
问题描述:
mysql通过sqoop导入到hive表中,发现有个别数据类型为int或tinyint的列导入后数据为null。设置各种行分隔符,列分隔符都没有效果。
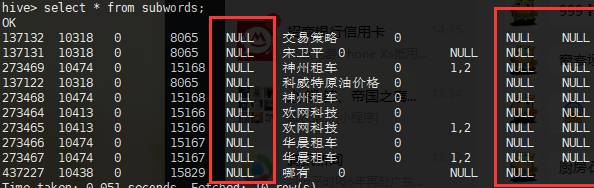
问题分析:
hive中单独将有问题的那几列的数据类型设置为string类型,重新导入后发现,里面的值变成true或者false。
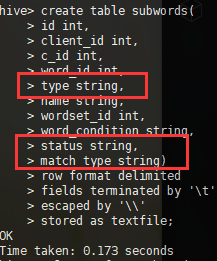
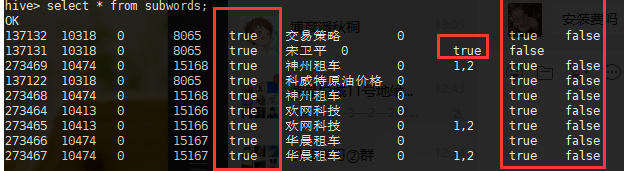
由此猜想,sqoop在导入的时候,将那几列的数据转换成了bool类型,问题产生的原因和hive建表语句无关,只能发生在sqoop端或者mysql端。
经过查看,发现mysql中有问题的那几列数据类型都是tinyint(1),这说明什么,说明那几列的数值长度为1。猜想sqoop将数值长度为1的数据类型,认为是bool类型,导入的时候会自动转换成bool类型。
验证:在sqoop的导入sql语句中,单独对那几个问题列进行数据类型转换(CONVERT(match_type,SIGNED)),然后再导入hive,发现数据可以正常显示,一点问题也没有
convert 函数 用来转换数据类型
例子:SELECT CONVERT (VARCHAR(5),12345)
返回:字符串 '12345'
解决方法:
sqoop导入的时候,将数据类型为1个字符长度的数值类型的列,进行格式转换(CONVERT(match_type,SIGNED))
1、Sqoop 空值问题
Hive中的null在底层是以“\N”来存储,而MySQL中的null在底层就是null,这就导致了两边同步数据时存储不一致问题。Sqoop在同步的时候应该严格保证两端的数据格式、数据类型一致,否则会带来异常。
方法1:依赖自身参数
(1)导出数据时采用--input-null-string和--input-null-non-string两个参数。
(2)导入数据时采用--null-string和--null-non-string。
方法2:建表时修改hive底层存储,修改为''(空字符串)
在hive导出时,给需要导出的表创建一张临时表,该表和Mysql同步的表、字段、类型等严格一致,将需要导出的数据插入到该表中,在建立该临时表的时候将hive中Null底层存储“/N”修改为''(空字符串)。具体可添加下面代码
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' with serdeproperties('serialization.null.format' = '')
例如:
drop table table_name;
CREATE TABLE IF NOT EXISTS table_name(
id int,
name string)
PARTITIONED BY (`partition_date` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' with serdeproperties('serialization.null.format' = '')
location 'hdfs://nameservice1/user/hive/warehouse/ods.db/table_name' - 然后将需要导出的数据插入到该临时表中
- 最后采用sqoop导出命令将数据导出到Mysql
导入数据同理
我们sqoop导数任务采用的是第二种方案,虽然比较麻烦,但是能够减少sqoop带来的一些不必要的麻烦,而且也比较容易定位问题,逻辑清晰,sqoop导出的时候只需要写基本的导出命令即可,这样sqoop很容易做成一个通用的脚本来调度。
2、sqoop 处理换行符 \n 和\r 等特殊符号处理
公司大数据平台ETL操作中,在使用sqoop将mysql中的数据抽取到hive中时,由于mysql库中默写字段中会有换行符,导致数据存入hive后,条数增多(每个换行符会多出带有null值得一条数据),导致统计数据不准确。因为sqoop 导出文件不能是ORC这种列式存储,所以只能替换。导出后对替换的字符在进行替换,将数据表存储 orc
解决办法:
一、sqoop的sql中对含有特殊字符的字段进行replace操作 ,将特殊字符转换为空格。
从mysql导入时--query用replace
replace(replace(replace(description,'\r',' '),'\n',' '),'\t',' ')
二、利用一下两个参数可以实现对换行等特殊字符的替换或者删除
--hive-delims-replacement--hive-drop-import-delims
使用方法,
1、在原有sqoop语句中添加 --hive-delims-replacement " " 可以将如mysql中取到的\n, \r, and \01等特殊字符替换为自定义的字符,此处用了空格
2、在原有sqoop语句中添加 --hive-drop-import-delims 可以将如mysql中取到的\n, \r, and \01等特殊字符丢弃给个具体的例子:
/usr/local/sqoop/bin/sqoop-import --connect jdbc:mysql://ip:port/xxx --username xxxx --password xxxx --table data_clt_app_info_1210 --target-dir /tmp/tmp_data_clt_app_info_text_1210_bak --fields-terminated-by '||' -m 1 --split-by stat_date --delete-target-dir --hive-delims-replacement 'aaaaaaaa'
大功告成
把特殊换行换成 aaaaaaaa
create table tmp.change_orc stored as orc as
select stat_date,app_id,queue,start_time,finish_time,regexp_replace(job_name,'aaaaaaaa',' \n ') as job_name
from tmp.tmp_data_clt_app_info_text_1210_bak 3、Sqoop数据导出一致性问题
1)场景1:如Sqoop在导出到Mysql时,使用4个Map任务,过程中有2个任务失败,那此时MySQL中存储了另外两个Map任务导入的数据,此时老板正好看到了这个报表数据。而开发工程师发现任务失败后,会调试问题并最终将全部数据正确的导入MySQL,那后面老板再次看报表数据,发现本次看到的数据与之前的不一致,这在生产环境是不允许的。
官网:http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
Since Sqoop breaks down export process into multiple transactions, it is possible that a failed export job may result in partial data being committed to the database. This can further lead to subsequent jobs failing due to insert collisions in some cases, or lead to duplicated data in others. You can overcome this problem by specifying a staging table via the --staging-table option which acts as an auxiliary table that is used to stage exported data. The staged data is finally moved to the destination table in a single transaction.
由于Sqoop将导出过程分解为多个事务,因此失败的导出作业可能会导致将部分数据提交到数据库。 这可能进一步导致后续作业由于某些情况下的插入冲突而失败,或导致其他作业中的重复数据。 您可以通过–staging-table选项指定登台表来解决此问题,该选项充当用于暂存导出数据的辅助表。 分阶段数据最终在单个事务中移动到目标表。
–staging-table方式
sqoop export --connect jdbc:mysql://192.168.137.10:3306/user_behavior
--username root
--password 123456
--table app_cource_study_report
--columns watch_video_cnt,complete_video_cnt,dt
--fields-terminated-by “\t”
--export-dir “/user/hive/warehouse/tmp.db/app_cource_study_analysis_${day}”
--staging-table app_cource_study_report_tmp
--clear-staging-table
--input-null-string ‘\N’
2)场景2:设置map数量为1个(不推荐,面试官想要的答案不只这个)
多个Map任务时,采用–staging-table方式,仍然可以解决数据一致性问题。
生成大于1.5G的数据,导入数据量非常大,可能会导致一个错误
错误:
exception “GC Overhead limit exceeded
原因:
Why Sqoop Import throws this exception?
The answer is – During the process, RDBMS database (NOT SQOOP) fetches all the rows at one shot and tries to load everything into memory. This causes memory spill out and throws error. To overcome this you need to tell RDBMS database to return the data in batches. The following parameters “?dontTrackOpenResources=true&defaultFetchSize=10000&useCursorFetch=true” following the jdbc connection string tells database to fetch 10000 rows per batch.
解决方案:
1、指定mappers的数量(数量最好不要超过节点的个数)
sqoop job --exec gp1813_user – --num-mappers 8;
2、调整jvm的内存,缺点:
-Dmapreduce.map.memory.mb=6000
-Dmapreduce.map.java.opts=-Xmx1600m
-Dmapreduce.task.io.sort.mb=4800 \
3、设置mysql的读取数据的方式,不要一次性将所有数据都fetch到内存
?dontTrackOpenResources=true&defaultFetchSize=10000&useCursorFetch=true
3、Sqoop 数据一致性问题
(1):如在Sqoop在导出到Mysql时,使用4个Map任务,过程中有2个任务失败,那此时MySQL中存储了另外两个Map任务导入的数据,此时运营正好看到了这个报表数据。而开发工程师发现任务失败后,会调试问题并最终将全部数据正确的导入MySQL,那后面老板再次看报表数据,发现本次看到的数据与之前的不一致,这在生产环境是不允许的。这是由于Sqoop将导出过程分解为多个事务,因此失败的导出作业可能会导致将部分数据提交到数据库。 这可能进一步导致后续作业由于某些情况下的插入冲突而失败,或导致其他作业中的重复数据。 您可以通过--staging-table选项指定登台表来解决此问题,该选项充当用于暂存导出数据的辅助表,分阶段数据最终在单个事务中移动到目标表。
--staging-table方式
(建立临时表,通过sqoop导入到临时表,成功之后再把临时表的数据通过事务导入到mysql的业务数据表,Sqoop在导入导出数据时,通过建立临时表可以解决好多问题,所以要学会巧用临时表),使用--staging-table选项,将hdfs中的数据先导入到临时表中,当hdfs中的数据导出成功后,临时表中的数据在一个事务中导出到目标表中(也就是说这个过程要不完全成功,要不完全失败)。为了能够使用staging这个选项,staging表在运行任务前或者是空的,要不就使用clear-staging-table配置,如果staging表中有数据,并且使用了--clear-staging-table选项,sqoop执行导出任务前会删除staging表中所有的数据。
注意:–direct导入时staging方式是不可用的,使用了—update-key选项时staging方式也不能用。
sqoop export --connect jdbc:mysql://ip:3306/dabases
--username root \
--password pwd \
--table table_name \
--columns id,name,dt \
--fields-terminated-by "\t" \
--export-dir "/user/hive/warehouse/db.ods/table_name_${day}" \
--staging-table table_name_tmp \
--clear-staging-table \
--input-null-string '\N' \3、$CONDITIONS关键字的作用
我们在执行log中发现被替换成了1=0
sqoop import
--connect jdbc:mysql://server74:3306/Server74
--username root
--password 123456
--target-dir /sqoopout2
--m 1
--delete-target-dir
--query 'select id,name,deg from emp where id>1202 and $CONDITIONS' [root@server72 sqoop]# sqoop import --connect jdbc:mysql://server74:3306/Server74 --username root --password 123456 --target-dir /sqoopout2
--m 1 --delete-target-dir --query 'select id,name,deg from emp where id>1202 and $CONDITIONS'
Warning: /usr/local/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
17/11/10 13:42:14 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/11/10 13:42:14 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/11/10 13:42:16 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/11/10 13:42:16 INFO tool.CodeGenTool: Beginning code generation
17/11/10 13:42:18 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:42:18 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:42:18 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:42:18 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
Note: /tmp/sqoop-root/compile/ac7745794cf5f0bf5859e7e8369a8c5f/QueryResult.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
17/11/10 13:42:31 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/ac7745794cf5f0bf5859e7e8369a8c5f/QueryResult.jar
17/11/10 13:42:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/11/10 13:42:41 INFO tool.ImportTool: Destination directory /sqoopout2 deleted.
17/11/10 13:42:41 INFO mapreduce.ImportJobBase: Beginning query import.
17/11/10 13:42:41 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/11/10 13:42:41 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/11/10 13:42:43 INFO client.RMProxy: Connecting to ResourceManager at server71/192.168.32.71:8032
17/11/10 13:42:58 INFO db.DBInputFormat: Using read commited transaction isolation
17/11/10 13:42:58 INFO mapreduce.JobSubmitter: number of splits:1
17/11/10 13:43:00 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510279795921_0011
17/11/10 13:43:03 INFO impl.YarnClientImpl: Submitted application application_1510279795921_0011
17/11/10 13:43:04 INFO mapreduce.Job: The url to track the job: http://server71:8088/proxy/application_1510279795921_0011/
17/11/10 13:43:04 INFO mapreduce.Job: Running job: job_1510279795921_0011
17/11/10 13:44:01 INFO mapreduce.Job: Job job_1510279795921_0011 running in uber mode : false
17/11/10 13:44:01 INFO mapreduce.Job: map 0% reduce 0%
17/11/10 13:44:58 INFO mapreduce.Job: map 100% reduce 0%
17/11/10 13:45:00 INFO mapreduce.Job: Job job_1510279795921_0011 completed successfully
17/11/10 13:45:01 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=124473
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=61
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=45099
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=45099
Total vcore-milliseconds taken by all map tasks=45099
Total megabyte-milliseconds taken by all map tasks=46181376
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=370
CPU time spent (ms)=6380
Physical memory (bytes) snapshot=106733568
Virtual memory (bytes) snapshot=842854400
Total committed heap usage (bytes)=16982016
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=61
17/11/10 13:45:01 INFO mapreduce.ImportJobBase: Transferred 61 bytes in 139.3429 seconds (0.4378 bytes/sec)
17/11/10 13:45:01 INFO mapreduce.ImportJobBase: Retrieved 3 records.
输出结果查看,发现1202以上的数据被正常抽出
[root@server72 sqoop]# hdfs dfs -cat /sqoopout2/part-m-00000
17/11/10 13:48:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1203,khalil,php dev
1204,prasanth,php dev
1205,kranthi,admin通过以上过程,我们得知一点:$CONTITONS是linux系统的变量,在执行过程中被赋值为(1=0),虽然实际执行的这个sql很奇怪。
正式开始研究CONTITONS到底是什么,所以我们先查看官方文档。
If you want to import the results of a query in parallel, then each map task will need to execute a copy of the query, with results partitioned by bounding conditions inferred by Sqoop. Your query must include the token
$CONDITIONSwhich each Sqoop process will replace with a unique condition expression. You must also select a splitting column with--split-by.如果你想通过并行的方式导入结果,每个map task需要执行sql查询语句的副本,结果会根据sqoop推测的边界条件分区。query必须包含
$CONDITIONS。这样每个scoop程序都会被替换为一个独立的条件。同时你必须指定--split-by.分区For example:
$ sqoop import \ --query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \ --split-by a.id \ --target-dir /user/foo/joinresults
直接理解可能有点困难,我先修改一些条件,大家观察joblog的区别。
sqoop import
--connect jdbc:mysql://server74:3306/Server74
--username root
--password 123456
--target-dir /sqoopout2
--delete-target-dir
--query 'select id,name,deg from emp where id>1202 and $CONDITIONS'
--split-by id
--m 2 我按照要求添加了--split-by id 分区,并设置map task数量为2
[root@server72 sqoop]# sqoop import --connect jdbc:mysql://server74:3306/Server74 --username root
--password 123456 --target-dir /sqoopout2 --m 2 --delete-target-dir --query 'select id,name,deg from emp where id>1202 and $CONDITIONS' --split-by id
Warning: /usr/local/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
17/11/10 13:50:26 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/11/10 13:50:26 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/11/10 13:50:28 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/11/10 13:50:28 INFO tool.CodeGenTool: Beginning code generation
17/11/10 13:50:30 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:50:31 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:50:31 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:50:31 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
Note: /tmp/sqoop-root/compile/1024341fa58082466565e5bd648cb10e/QueryResult.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
17/11/10 13:50:43 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/1024341fa58082466565e5bd648cb10e/QueryResult.jar
17/11/10 13:50:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/11/10 13:50:55 INFO tool.ImportTool: Destination directory /sqoopout2 deleted.
17/11/10 13:50:55 INFO mapreduce.ImportJobBase: Beginning query import.
17/11/10 13:50:55 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/11/10 13:50:55 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/11/10 13:50:56 INFO client.RMProxy: Connecting to ResourceManager at server71/192.168.32.71:8032
17/11/10 13:51:12 INFO db.DBInputFormat: Using read commited transaction isolation
17/11/10 13:51:12 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(id), MAX(id) FROM (select id,name,deg from emp where id>1202 and (1 = 1) ) AS t1
17/11/10 13:51:12 INFO mapreduce.JobSubmitter: number of splits:3
17/11/10 13:51:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510279795921_0012
17/11/10 13:51:18 INFO impl.YarnClientImpl: Submitted application application_1510279795921_0012
17/11/10 13:51:19 INFO mapreduce.Job: The url to track the job: http://server71:8088/proxy/application_1510279795921_0012/
17/11/10 13:51:19 INFO mapreduce.Job: Running job: job_1510279795921_0012
17/11/10 13:52:19 INFO mapreduce.Job: Job job_1510279795921_0012 running in uber mode : false
17/11/10 13:52:19 INFO mapreduce.Job: map 0% reduce 0%
17/11/10 13:53:23 INFO mapreduce.Job: map 33% reduce 0%
17/11/10 13:54:19 INFO mapreduce.Job: map 67% reduce 0%
17/11/10 13:54:20 INFO mapreduce.Job: map 100% reduce 0%
17/11/10 13:54:24 INFO mapreduce.Job: Job job_1510279795921_0012 completed successfully
17/11/10 13:54:25 INFO mapreduce.Job: Counters: 31
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=374526
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=301
HDFS: Number of bytes written=61
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Killed map tasks=2
Launched map tasks=5
Other local map tasks=5
Total time spent by all maps in occupied slots (ms)=349539
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=349539
Total vcore-milliseconds taken by all map tasks=349539
Total megabyte-milliseconds taken by all map tasks=357927936
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=301
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=3013
CPU time spent (ms)=21550
Physical memory (bytes) snapshot=321351680
Virtual memory (bytes) snapshot=2528706560
Total committed heap usage (bytes)=52994048
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=614、fetch-size
导入数据时,指示每次从数据库读取的记录数。使用下面的语法:--fetch-size=<n>,其中<n>表示Sqoop每次必须取回的记录数,默认值为1000。可以基于读取的数据量、可用的内存和带宽大小适当增加fetch-size的值。某些情况下这可以提升25%的性能。
--fetch-size n:一次去mysql中批量读取的数据条数。
建议:
1.考虑一条数据的量。(如果2个字段和200个字段的–fetch-size不能一样)
2.考虑数据库的性能
3.考虑网络速度
4.最好的状态是一次–fetch-size能满足一个mapper
5、Map task并行度,num-mappers
该参数的语法为--num-mappers <number ofmap tasks>,用于指定并行数据导入的map任务数,默认值为4。应该将该值设置成低于数据库所支持的最大连接数。
并行度导入数据的 时候 需要指定根据哪个字段进行切分 该字段通常是主键或者是自增长不重复的数值类型字段,否则会报下面的错误。
错误日志:
Import failed: No primary key could be found for table. Please specify one with --split-by or perform a sequential import with ‘-m 1’.
就是说当map task并行度大于1时,下面两个参数要同时使用:
–split-by id指定根据id字段进行切分
–m n指定map并行度n个
对于m要综合考虑数据量、IO、源数据库的性能、集群的资理等等。一种简单的考虑是最大不超过yarn上分配给这个用户的vcore个数,最小“数据量/m”要够一个128MB的文件。如果条件允许可以先设置一个值跑着试试,然后观察源数据库负载,集群IO以及运行时长等,再进行相应调整。
2.某表如果2G数据,设置多少个mapper合适?
建议128M(和块大小一致)一个mapper即可.
小量数据时(200M左右): 最好使用一个map,快且减少小文件。
数据量500w以下使用4个map即可。
数据量500w以上使用8个map即可,太多会对数据库加压,造成其他场景使用性能降低。如果是为了专门导数据,和下游计算的并行度,可以适当调大。
例如:
通常可以指定split-by 对应的自增ID 列,然后使用–num-mappers或者-m指定map的个数,即并发的抽取进程数量。但是有时候会碰到很多的表没有添加自增ID或者,整数型的主键,或者 主键分布不均,反而会拖慢整个job的进程。
- 根据sqoop源码的设计,我们可以使用–query语句中添加自增ID,作为split-by的参数,与此同时通过设置的自增ID的范围可以设置boundary。
代码:
```bash
--query 方式:涉及参数 --query、--split-by、--boundary-query
--query: select col1、 col2、 coln3、 columnN from (select ROWNUM() OVER() AS INC_ID, T.* from table T where xxx ) where $CONDITIONS
--split-by: INC_ID
--boundary-query: select 1 as MIN , sum(1) as MAX from table where xxx
完整语法代码:
password-file通过 echo -n “password content” > passsword-file 方式得到,这样不会包含异常字符。
sqoop import --connect $yourJdbConnectURL \
--username $yourUserName
--password-file file;///localpasswordFile or hdfs relative Path
--query "" \
--split-by "" \
-m 8 \
-boundary-query “select 1 as min , sum(1) as max from table where xx” \
--other parames参考链接:sqoop 并行抽取数据,同时解决数据倾斜_bymain的博客-优快云博客
3、数据倾斜问题
sqoop的数据分割策略不够优秀导致的数据倾斜:
sqoop 抽数的并行化主要涉及到两个参数:num-mappers:启动N个map来并行导入数据,默认4个;split-by:按照某一列来切分表的工作单元。要避免数据倾斜,对split-by指定字段的要求是int类型同时数据分布均匀,满足这样的要求的表只有极少数的有自增主键的表才能满足。核心思想就是自己生成一个有序且均匀的自增ID,然后作为map的切分轴,这样每个map就可以分到均匀的数据,可以通过设置map的个数来提高吞吐量。
split-by id,-m,数据量1-100,第一个mapper:(0,50],第二个mapper:(50, 100]。
8.怎么监控数据是否完全导入?
使用shell脚本去查询mysql中某表的数据。然后和hive中表的行数对比。
#!/bin/bash
cnt = ‘mysq1 -uroot -p123456 一e "select count(*) from hyk.dept"’
echo“u2 table of test total rows :${cnt}"



















 1218
1218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











