






 本文介绍了使用Python的urllib模块爬取纵横中文网的24小时畅销榜,通过分析网页源代码,利用正则表达式提取数据,并通过循环实现多页抓取。在遇到反爬机制时,作者预告将分享如何伪装浏览器进行应对。
本文介绍了使用Python的urllib模块爬取纵横中文网的24小时畅销榜,通过分析网页源代码,利用正则表达式提取数据,并通过循环实现多页抓取。在遇到反爬机制时,作者预告将分享如何伪装浏览器进行应对。
DuangDuangDuang
上个笔记说了正则表达式
这次实战一下还有urllib模块
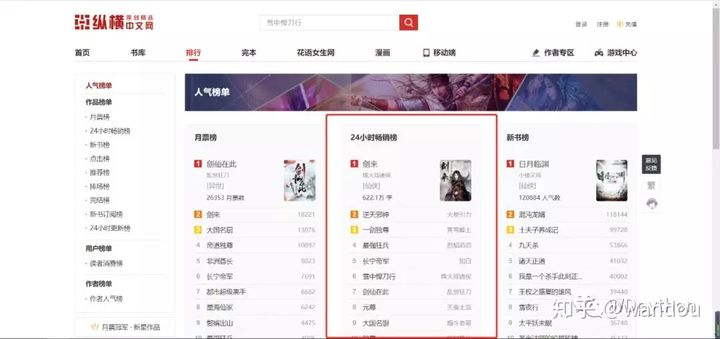
这次来爬“纵横中文网”24小时畅销榜名单
经过一顿装逼后 不 操作
成功
怎么搞的呢
首先,介绍一个模块“urllib”
"""
这个模块主要记住三个模块(有5个的):
1、request:用于访问读取url(主讲)
先说这几个函数:urlopen() info() getcode() read()还有很多
2、error:显示异常
3、parse:解析url
"""
首先分析一下我们要爬的页面
小说排行榜,最新热门小说排行榜,各类原创小说排行榜,纵横中文小说网www.zongheng.com
http://www.zongheng.com/rank/details.html?rt=3&d=1&p=1
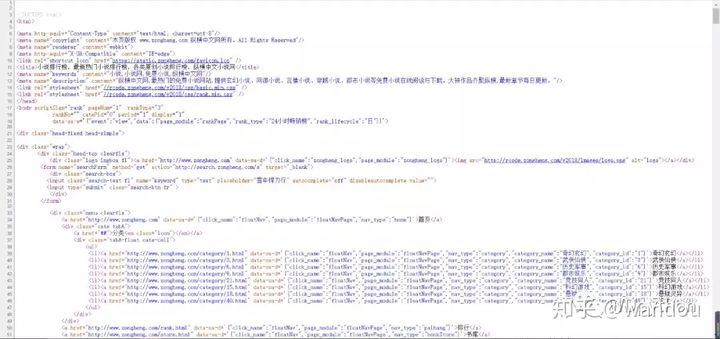
然后查看网页源代码(右键就会看见)
我们搜索一下《剑来》第一名的小说
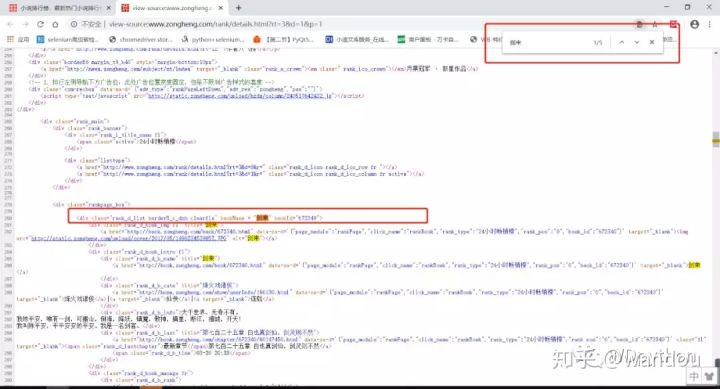
再找一下排名第二的小说
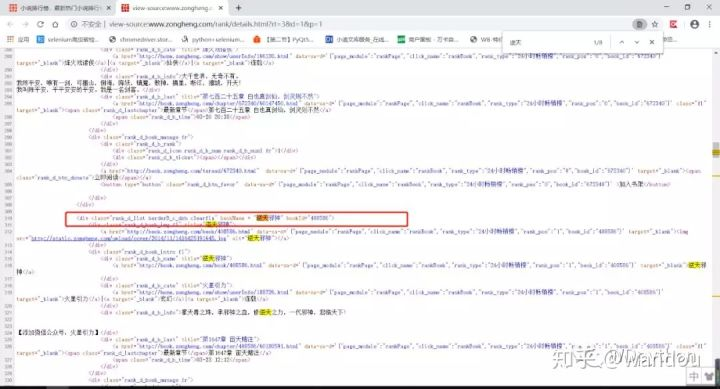
我们分析一下获取到标签
<div class="rank_d_list borderB_c_dsh clearfix" bookName = "剑来" bookId="672340">
这个时候我们就需要使用正则表达式
怎么 写呢 bookName = "(.*?)" 对吧,前面的匹配不匹配都可以
要是匹配怎么写:
pat = '<div class=".*" bookName = "(.*?)" bookId=".*">'
一共有3页
点击下一页
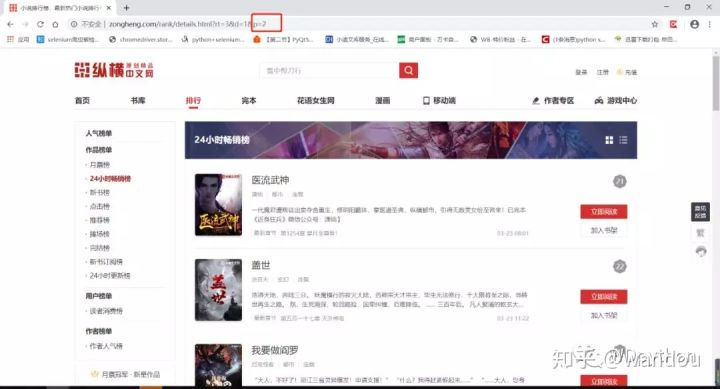
我们发现p =2
那我们就定义个循环控制翻页
OK 这就分析完了
那就直接撸代码,干就完了
我们先爬第一页的数据
import urllib.request
import re
# 导包
url = "http://www.zongheng.com/rank/details.html?rt=3&d=1&p=1"
# 定义要访问的链接然后就要去访问,这个时候就要用到urllib模块 了
我们用urllib.request.urlopen()方法
urlopen 方法常用三个参数
urllib.request.urlopen(url, data=None, [timeout, ]*)第一个就是请求连接
第二个我们在post请求的时候需要填写表单的时候用的
第三个设置超时时间
data = urllib.request.urlopen(url).read().decode("utf-8")
# read()读取网页
# decode()设置编码格式
pat = '<div class=".*" bookName = "(.*?)" bookId=".*">'
# 定义正则表达式规则
# 这个注意,我们的标签中有双引号,那我们外部就用单引号筛选数据 1??
rst = re.compile(pat).findall(data)
# 全局搜索,上一篇已经说了输出一下
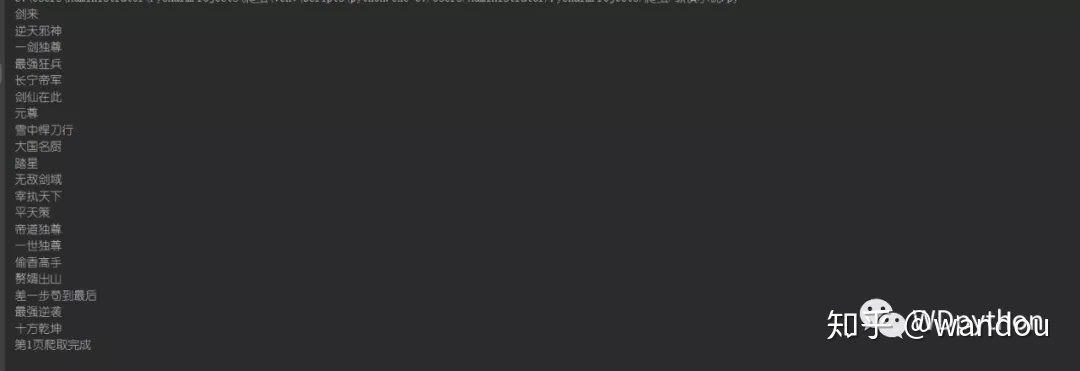
['剑来', '逆天邪神', '一剑独尊', '最强狂兵', '长宁帝军', '剑仙在此', '元尊', '雪中悍刀行', '大国名厨', '踏星', '无敌剑域', '宰执天下', '平天策', '帝道独尊', '一世独尊', '偷香高手', '赘婿出山', '差一步苟到最后', '最强逆袭', '医流武神']看来是成功了,第一页这样就获取成功了
获取第二页第三页就简单了,加个循环就OK
最后整体 的代码就是这样
import urllib.request
import re
for i in range(1, 4):
url = "http://www.zongheng.com/rank/details.html?rt=3&d=1&p=" + str(i)
data = urllib.request.urlopen(url).read().decode("utf-8")
pat = '<div class=".*" bookName = "(.*?)" bookId=".*">'
rst = re.compile(pat).findall(data)
for j in range(0, len(rst)):
print(rst[j])
print("第" + str(i) + "页爬取完成\n\n")看起来不是特别的南
当我想在装一波的时候,却遇见了反爬

丝毫不慌张
我们以后分享伪装浏览器

靓仔上车不

















 4248
4248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









