







在上一节笔记中,我们解决了评估学习器泛化性能的方法,即用测试集的“测试误差”作为“泛化误差”的近似,那如何计算“测试误差”呢?这就是性能度量,例如:均方差,错误率等,即“测试误差”的一个评价标准。有了评估方法和性能度量,就可以计算出学习器的“测试误差”,优化目标就是使得测试误差最小化。训练完成后,如何对两个学习器的性能度量结果做比较呢?这就是比较检验。最后偏差与方差是解释学习器泛化性能的一种重要工具。
性能度量
性能度量(performance measure)是衡量模型泛化能力的评价标准,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果。
最常见的性能度量
1.回归任务:
- MAE(Mean Absolute Error,平均绝对误差)
M A E = 1 m ∑ i = 1 m ∣ y ^ i − y i ∣ M A E=\frac{1}{m} \sum_{i=1}^{m}\left|\hat{y}_{i}-y_{i}\right| MAE=m1i=1∑m∣y^i−yi∣
- MSE(Mean Square Error,均方误差)
M S E = 1 2 m ∑ i = 1 m ( y ^ i − y i ) 2 M S E=\frac{1}{2 m} \sum_{i=1}^{m}\left(\hat{y}_{i}-y_{i}\right)^{2} MSE=2m1i=1∑m(y^i−yi)2
- RMSE(Root Mean Square Error, 均方根误差)
R M S E = M S E R M S E=\sqrt{M S E} RMSE=MSE
2.分类问题的常用性能度量
2.1)错误率与精度
错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例,易知:错误率+精度=1。
错误率:
E
(
f
;
D
)
=
1
m
∑
i
=
1
m
I
(
f
(
x
i
)
≠
y
i
)
E(f ; D)=\frac{1}{m} \sum_{i=1}^{m} \mathbb{I}\left(f\left(\boldsymbol{x}_{i}\right) \neq y_{i}\right)
E(f;D)=m1i=1∑mI(f(xi)=yi)
精度:
acc ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x i ) = y i ) = 1 − E ( f ; D ) \begin{aligned} \operatorname{acc}(f ; D) &=\frac{1}{m} \sum_{i=1}^{m} \mathbb{I}\left(f\left(\boldsymbol{x}_{i}\right)=y_{i}\right) \\ &=1-E(f ; D) \end{aligned} acc(f;D)=m1i=1∑mI(f(xi)=yi)=1−E(f;D)
查准率/查全率/F1
分类任务中,错误率和精度虽然常用,但不能满足所有的需求,例如:在推荐系统中,我们只关心推送给用户的内容用户是否感兴趣(即查准率precision),或者说所有用户感兴趣的内容我们推送出来了多少(即查全率 recall)。因此,使用查准/查全率更适合描述这类问题。
表述2:推荐系统下,是希望更多优质内容被找回来呢,还是尽可能不去打扰用户,只推荐他感兴趣的内容。
对于二分类问题,分类结果混淆矩阵与查准/查全率定义如下:
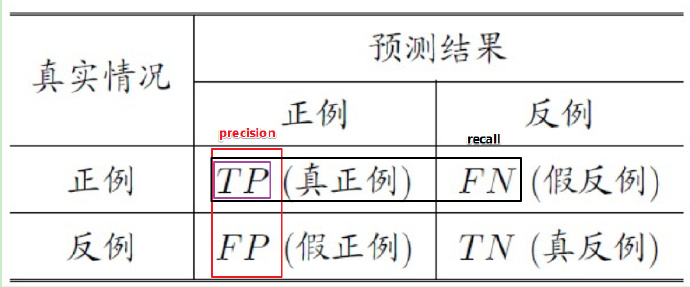
其中,TP:true positive FN:false negative
查准率(准确率 precision):预测为正的样本中有多少真正为正样本。
P = T P T P + F P P=\frac{T P}{T P+F P} P=TP+FPTP
查全率(recall 召回率):全部正例样本中有多少正例被模型找到了
R
=
T
P
T
P
+
F
N
R=\frac{T P}{T P+F N}
R=TP+FNTP
正如天下没有免费的午餐,查准率和查全率是一对矛盾的度量。例如我们想让推送的内容尽可能用户全都感兴趣,那只能推送我们把握高的内容,这样就漏掉了一些用户感兴趣的内容,查全率就低了;如果想让用户感兴趣的内容都被推送,那只有将所有内容都推送上,宁可错杀一千,不可放过一个,这样查准率就很低了。
“P-R曲线”正是描述查准/查全率变化的曲线,P-R曲线定义如下:根据学习器的预测结果(一般为一个实值或概率)对测试样本进行排序,将最可能是“正例”的样本排在前面,最不可能是“正例”的排在后面,按此顺序逐个把样本作为“正例”进行预测,每次计算出当前的P值和R值,如下图所示:
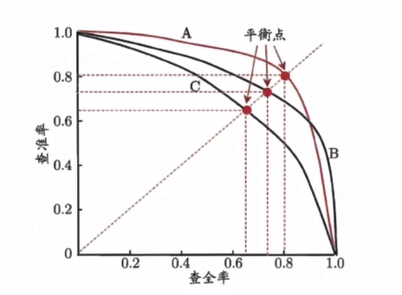
P-R曲线如何评估呢?
若一个学习器A的P-R曲线被另一个学习器B的P-R曲线完全包住,则称:B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。但一般来说,曲线下的面积是很难进行估算的,所以衍生出了“平衡点”(Break-Event Point,简称BEP),即当P=R时的取值,平衡点的取值越高,性能更优。
P和R指标有时会出现矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure,又称F-Score。F-Measure是P和R的加权调和平均,即:
1
F
β
=
1
1
+
β
2
⋅
(
1
P
+
β
2
R
)
F
β
=
(
1
+
β
2
)
×
P
×
R
(
β
2
×
P
)
+
R
\begin{gathered} \frac{1}{F_{\beta}}=\frac{1}{1+\beta^{2}} \cdot\left(\frac{1}{P}+\frac{\beta^{2}}{R}\right) \\ F_{\beta}=\frac{\left(1+\beta^{2}\right) \times P \times R}{\left(\beta^{2} \times P\right)+R} \end{gathered}
Fβ1=1+β21⋅(P1+Rβ2)Fβ=(β2×P)+R(1+β2)×P×R
β
>
1
\beta>1
β>1 时查全率有更大影响;
β
<
1
\beta<1
β<1 时查准率有更大影响
特别地,当β=1时,也就是常见的F1度量,是P和R的调和平均,当F1较高时,模型的性能越好。
1 F 1 = 1 2 ⋅ ( 1 P + 1 R ) F 1 = 2 × P × R P + R = 2 × T P 样例总数 + T P − T N \begin{gathered} \frac{1}{F 1}=\frac{1}{2} \cdot\left(\frac{1}{P}+\frac{1}{R}\right) \\ F 1=\frac{2 \times P \times R}{P+R}=\frac{2 \times T P}{\text { 样例总数 }+T P-T N} \end{gathered} F11=21⋅(P1+R1)F1=P+R2×P×R= 样例总数 +TP−TN2×TP
有时候我们会有多个二分类混淆矩阵,例如:多次训练或者在多个数据集上训练,那么估算全局性能的方法有两种,分为宏观和微观。简单理解,宏观就是先算出每个混淆矩阵的P值和R值,然后取得平均P值macro-P和平均R值macro-R,再算出Fβ或F1,而微观则是计算出混淆矩阵的平均TP、FP、TN、FN,接着进行计算P、R,进而求出Fβ或F1。

ROC与AUC
1.ROC (Receiver Operating Characteristic Curve).翻译为"接受者操作特性曲线"。
如上所述:学习器对测试样本的评估结果一般为一个实值或概率,设定一个阈值,大于阈值为正例,小于阈值为负例,因此这个实值的好坏直接决定了学习器的泛化性能,**若将这些实值排序,则排序的好坏决定了学习器的性能高低。ROC曲线正是从这个角度出发来研究学习器的泛化性能,ROC曲线与P-R曲线十分类似,都是按照排序的顺序逐一按照正例预测,**不同的是ROC曲线以“真正例率”(True Positive Rate,简称TPR)为横轴,纵轴为“假正例率”(False Positive Rate,简称FPR),ROC偏重研究基于测试样本评估值的排序好坏。
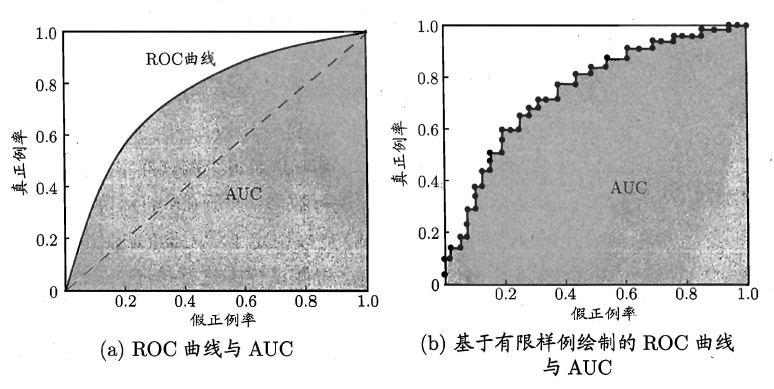
曲线由两个变量FPR和TPR组成,FPR对TPR,即是以代价(costs)对收益(benefits)。
横坐标假阳性率(False Positive Rate,FPR):负样本预测错误
f
p
r
=
F
P
F
P
+
T
N
=
F
P
m
−
f p r=\frac{F P}{F P+T N}=\frac{F P}{m_{-}}
fpr=FP+TNFP=m−FP
纵坐标真阳性率( True Positive Rate,TPR):正样本预测正确(等于Recall)
f
p
r
=
F
P
F
P
+
T
N
=
F
P
m
−
f p r=\frac{F P}{F P+T N}=\frac{F P}{m_{-}}
fpr=FP+TNFP=m−FP
ROC曲线绘制方法:首先根据测试样本的评估值对测试样本排序,接着按照以下规则进行绘制。

2.AUC(Area Uder ROC Curve)
ROC曲线下的面积定义为AUC(Area Uder ROC Curve),不同于P-R的是,这里的AUC是可估算的,即AUC曲线下每一个小矩形的面积之和。易知:AUC越大,分类器分类效果越好。AUC为1时,证明所有正例排在了负例的前面,AUC为0时,所有的负例排在了正例的前面。
A U C = 1 2 ∑ i = 1 m − 1 ( x i + 1 − x i ) ⋅ ( y i + y i + 1 ) \mathrm{AUC}=\frac{1}{2} \sum_{i=1}^{m-1}\left(x_{i+1}-x_{i}\right) \cdot\left(y_{i}+y_{i+1}\right) AUC=21i=1∑m−1(xi+1−xi)⋅(yi+yi+1)
代价敏感错误率与代价曲线
上面的方法中,将学习器的犯错同等对待,但在现实生活中,将正例预测成假例与将假例预测成正例的代价常常是不一样的,例如:将无疾病–>有疾病只是增多了检查,但有疾病–>无疾病却是增加了生命危险。以二分类为例,由此引入了“代价矩阵”(cost matrix)。
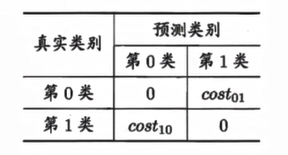
在非均等错误代价下,我们希望的是最小化“总体代价”,这样“代价敏感”的错误率(2.5.1节介绍)为:
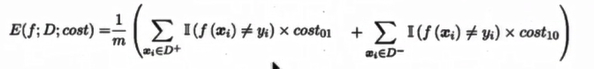
同样对于ROC曲线,在非均等错误代价下,演变成了“代价曲线”,代价曲线横轴是取值在[0,1]之间的正例概率代价,式中p表示正例的概率,纵轴是取值为[0,1]的归一化代价。
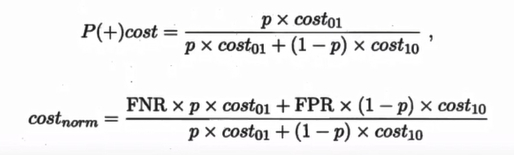
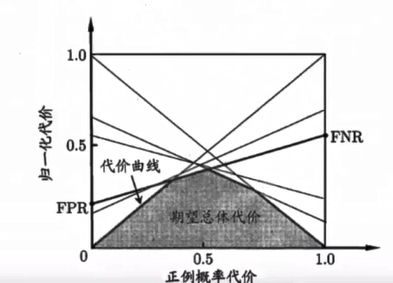
代价曲线的绘制很简单:设ROC曲线上一点的坐标为(TPR,FPR) ,则可相应计算出FNR,然后在代价平面上绘制一条从(0,FPR) 到(1,FNR) 的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC 曲线土的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价,如图所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









