






一、JDBC介绍
JDBC的概念
JDBC是一个独立于特定数据库管理系统,用于执行SQL语句来对数据库进行存取和操作的公共接口
JDBC提供了规范的接口用来访问不同的数据库,加快了开发过程以及减少修改代码的操作
在没有JDBC时 java是直接连接数据库从而对数据库进行处理,但当要换数据库和计算机时就麻烦了

有了JDBC后,java访问数据库就转换为:
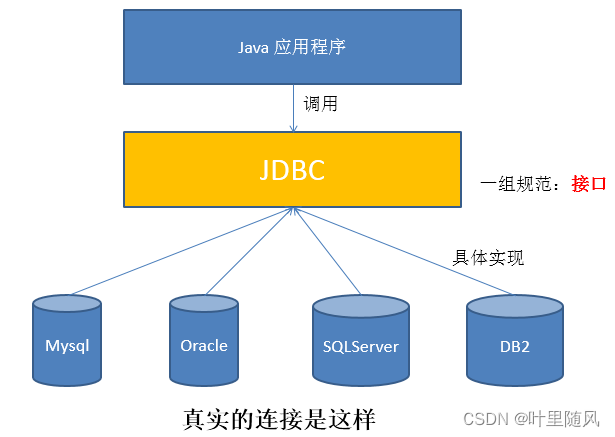
由于JDBC提供了一组规范的接口从而达到可以使用不同的数据库,使得java程序有了更好的可移植性
二、使用java通过JDBC操作数据库步骤
1.导入jar包
使用不同数据库需要导入对应的jar包
这里我使用的是mysql数据库 jar包如下
链接:https://pan.baidu.com/s/1nee7FIXvSemd-vWAehjPZA
提取码:3ef7
2.注册、加载驱动
Class.forName("com.mysql.jdbc.Driver");3.获取连接
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test2", "root", "root");
jdbc:mysql://localhost:3306/test2", "root", "root"
上句url中的jdbc属于协议,在JDBC中URL的协议总是jdbc,而mysql属于是子协议,这是用来标识一个数据库驱动程序,而后的localhost:3306/test2则属于子名称 test2代表的是连接的库名,后面的俩个root代表的是账户密码。库名、账户密码均由个人设置来改。
String sql = "sql语句";
4..获取执行sql对象、接收结果
这里可以使用Statement和它的子接口PreparedStatement。我推荐使用后者
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery(sql);PreparedStatement ps = conn.prepareStatement(sql);
ResultSet rs= ps.executeQuery();既然都能执行sql,那难免存在优势劣势
对于前者Statement 存在拼串,sql注入问题等。如
String sql = "SELECT user,password FROM user_table WHERE USER = '" + userName + "' AND PASSWORD = '" + password
+ "'";
SELECT user, password FROM user_table WHERE user='a' OR 1 = ' AND password = ' OR '1' = '1') 同时,它无法操作Blob类型的变量,在实现批量插入时,效率低
而后者PreparedStatement则完美解决了这些问题
它可以实行预编译,不会对同一句sql语句多次编译,也可以防止sql注入问题
在对Blob类型处理上它也可以进行
在批量操作上可以使用事务进行,在效率上高
for (int i = 1; i <= 1000000; i++) {
ps.setObject(1, "name_" + i);
ps.addBatch();
if(i % 1000 == 0) {
ps.executeBatch();
ps.clearBatch();
}
}
conn.commit();5.处理结果集
6.释放资源
在做增删改时,一般只涉及到连接对象以及执行sql对象,所以需关闭
在做查询时,除了上述俩个对象外,仍涉及到结果集对象 所以需要关闭三个对象。
三、ResultSet与ResultSetMetaData
1.ResultSet
-
查询需要调用PreparedStatement 的 executeQuery() 方法,查询结果是一个ResultSet 对象
-
ResultSet 对象以逻辑表格的形式封装了执行数据库操作的结果集,ResultSet 接口由数据库厂商提供实现
-
ResultSet 返回的实际上就是一张数据表。有一个指针指向数据表的第一条记录的前面。
-
ResultSet 对象维护了一个指向当前数据行的游标,初始的时候,游标在第一行之前,可以通过 ResultSet 对象的 next() 方法移动到下一行。调用 next()方法检测下一行是否有效。若有效,该方法返回 true,且指针下移。相当于Iterator对象的 hasNext() 和 next() 方法的结合体。
-
当指针指向一行时, 可以通过调用 getXxx(int index) 或 getXxx(int columnName) 获取每一列的值
2.ResultSetMetaData
-
可用于获取关于 ResultSet 对象中列的类型和属性信息的对象
-
ResultSetMetaData meta = rs.getMetaData();
-
getColumnName(int column):获取指定列的名称
-
getColumnLabel(int column):获取指定列的别名
-
getColumnCount():返回当前 ResultSet 对象中的列数。
-
getColumnTypeName(int column):检索指定列的数据库特定的类型名称。
-
getColumnDisplaySize(int column):指示指定列的最大标准宽度,以字符为单位。
-
isNullable(int column):指示指定列中的值是否可以为 null。
-
isAutoIncrement(int column):指示是否自动为指定列进行编号,这样这些列仍然是只读的。
-
四、俩种思想、俩种技术
-
俩种思想
-
面向接口编程的思想
-
ORM思想(object relational mapping)
- 一个数据表对应一个java类
- 表中的一条记录对应java类的一个对象
- 表中的一个字段对应java类的一个属性
-
两种技术
-
JDBC结果集的元数据:ResultSetMetaData
-
获取列数:getColumnCount()
-
获取列的别名:getColumnLabel()
-
- 通过反射,创建指定类的对象,获取指定的属性并赋值
//定义map集合
Map<String, Object> values = new HashMap<String, Object>();
//定义ResultSetMetaData对象
ResultSetMetaData rsmd = res.getMetaData();
while(res.next()) {
//利用反射创建对象
entity = clazz.newInstance();
for (int i = 0; i < rsmd.getColumnCount(); i++) {
//得到数据项标签
String columnLabel = rsmd.getColumnLabel(i+1);
//得到数据项 的值
Object columnValue = res.getObject(i+1);
//将键值对放入集合
values.put(columnLabel, columnValue);
}
}
//若value不为空,则用反射为clazz创建对象
if(values.size() > 0) {
entity = clazz.newInstance();
//遍历map,为对应属性列赋值
for (Map.Entry<String , Object> entry : values.entrySet()) {
//得到键
String key = entry.getKey();
//得到值
Object value = entry.getValue();
//给属性赋值
Field field = clazz.getDeclaredField(key);
field.setAccessible(true);
field.set(entity, value);
}
}
}五、批量执行sql语句
加上事务的思想,当攒到一定数量在一起执行并提交
//1.设置为不自动提交数据
conn.setAutoCommit(false);
String sql = "insert into goods(name)values(?)";
PreparedStatement ps = conn.prepareStatement(sql);
for(int i = 1;i <= 1000000;i++){
ps.setString(1, "name_" + i);
//1.“攒”sql
ps.addBatch();
if(i % 500 == 0){
//2.执行
ps.executeBatch();
//3.清空
ps.clearBatch();
}
}
conn.commit();
// conn.rollback(); 回滚六、数据库连接池
介绍:
就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
-
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
-
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
多种开源的数据库连接池
-
JDBC 的数据库连接池使用 javax.sql.DataSource 来表示,DataSource 只是一个接口,该接口通常由服务器(Weblogic, WebSphere, Tomcat)提供实现,也有一些开源组织提供实现:
-
DBCP 是Apache提供的数据库连接池。tomcat 服务器自带dbcp数据库连接池。速度相对c3p0较快,但因自身存在BUG,Hibernate3已不再提供支持。
-
C3P0 是一个开源组织提供的一个数据库连接池,速度相对较慢,稳定性还可以。hibernate官方推荐使用
-
BoneCP 是一个开源组织提供的数据库连接池,速度快
-
Druid 是阿里提供的数据库连接池,据说是集DBCP 、C3P0 优点于一身的数据库连接池,但是速度不确定是否有BoneCP快
-
-
DataSource 通常被称为数据源,它包含连接池和连接池管理两个部分,习惯上也经常把 DataSource 称为连接池
-
DataSource用来取代DriverManager来获取Connection,获取速度快,同时可以大幅度提高数据库访问速度。

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









