







这篇文章将换个角度带你了解 Qt 在使用 MSVC 编译器的环境下,从 编译器 究竟做了什么的角度来解释乱码生成的原因!
测试环境: Qt5.15.2 + MSVC 2017
写一个最简单的 Demo 验证我的思路,用 UTF-8 的文件保存我的代码,注意我测试用的是 UTF-8 文件
#include <QDebug>
#include <QString>
int main()
{
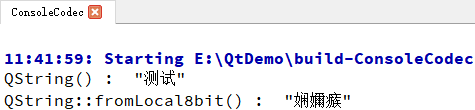
qDebug() << QString("测试");
qDebug() << QString::fromLocal8bit("测试");
return 0;
}
一些基本概念
源字符集 (source-charset) :源码文件是使用何种编码保存的
执行字符集 (execution-charset) :可执行程序内保存的是何种编码(程序执行时内存中字符串编码)
此外还需要了解一下 UTF-8,Unicdoe,GB2312 这些常见的字符编码是啥,规则是啥,怎么互相转换,后面再分析的过程中会有提到
MSVC 编译器在没有指定 源字符集 和 执行字符集 的时候,默认使用的字符集都是 GBK
当编译器在 认为 源字符集 和 执行字符集 不一致的时候,在生成可执行程序的时候,会有字符转码的行为
也就是用 源字符集 来解释字符编码,然后用 执行字符集 来编码成可执行文件,这个时候可执行文件的就需要用 执行字符集 格式才能正确解释出来
再做一个准备
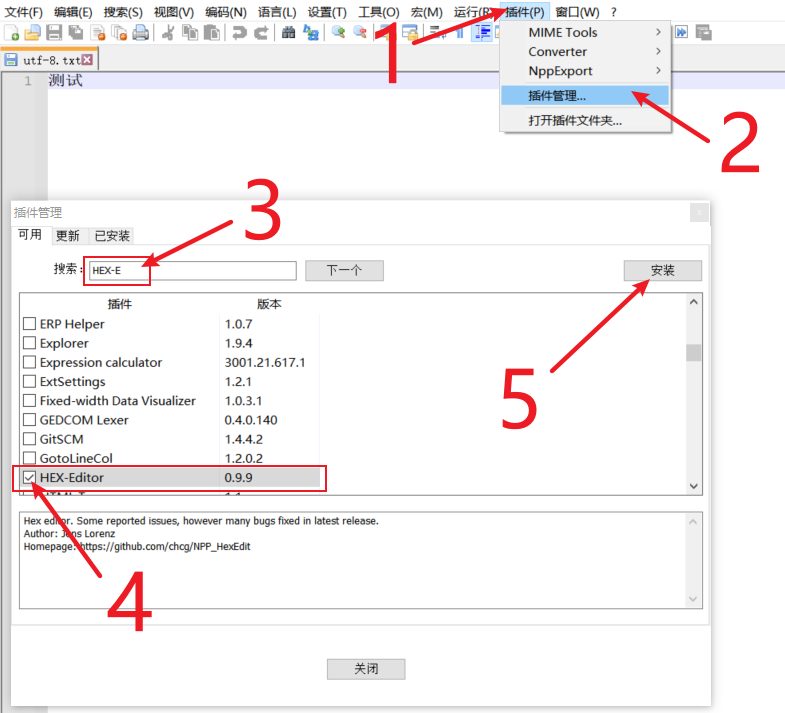
给 Notepad++ 安装 HEX-Editor,主要是为了验证文件在二进制下是否入预期一样
安装方法如图
顺便扩展一点知识,UTF-8 的文件中,“测试” 这2个字应该保存成什么?
这里有个我觉得还不错的将 字符 转换成 UTF-8 网站
http://www.mytju.com/classcode/tools/encode_utf8.asp
得到结果如下图
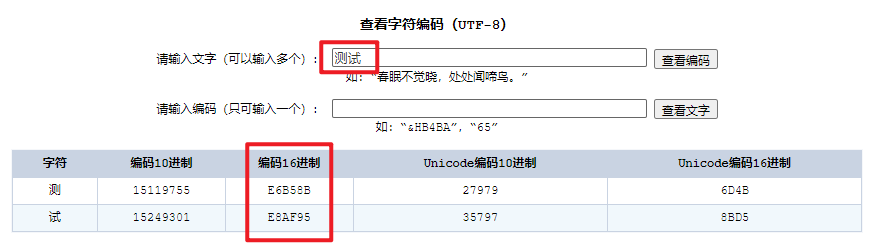
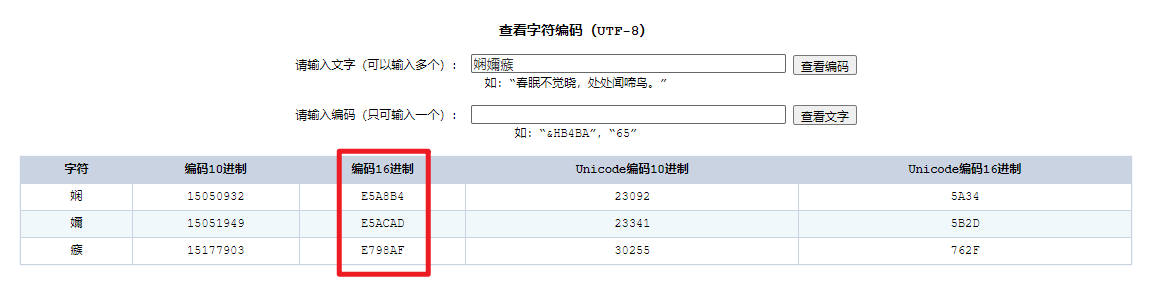
所以可以得出 “测试” 的 UTF-8 的编码是 “e6 b5 8b e8 af 95”
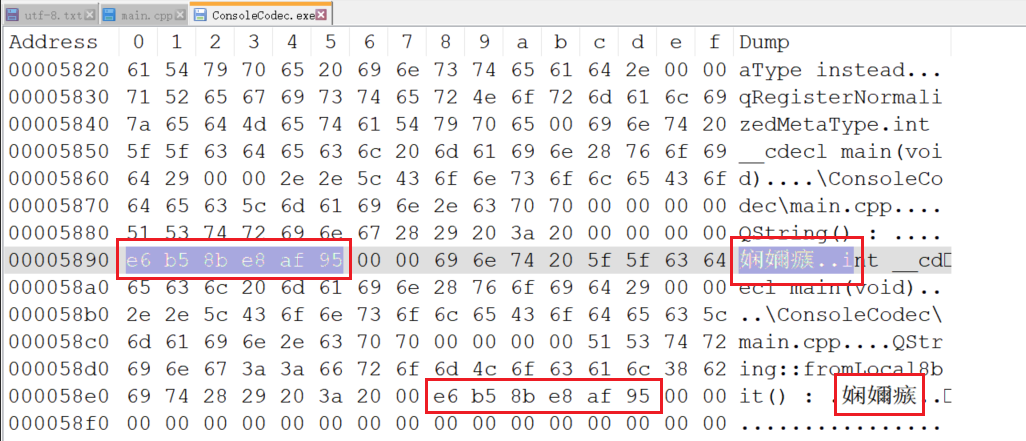
用 Notepad++ 创建一个保存 “测试” 2个字符的 UTF-8 文件,利用 HEX-Editor 工具验证一下,和预期一样

看到上图中 Dump 部分中出现的 3 个乱码吗?看来 HEX-Editor 解码也出现了问题啊!
乱码出现最简单的一个原因就是,在解释这些字节流的时候,其实它并不知道应该按照什么规则去解释!
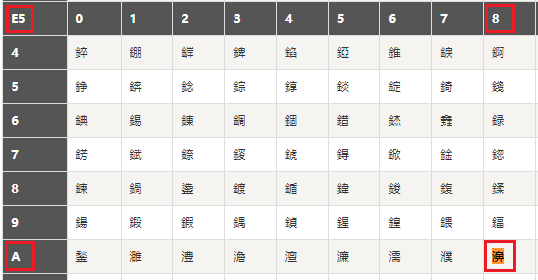
以 “e6 b5 8b e8 af 95” 为例,如果我们按照 GBK 的编码去解释,因为 GBK 是使用 2 个字节来表示一个汉字,那么
“e6 b5”解释成“娴”“8b e8”解释成“嬭””af 95“解释成“瘯”



图片来自 https://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php
现在剩下的就是对编译过程中字符编码变化的分析
对接下来的小标题做一个解释,
GBK/GBK第一个GBK指的是编译器使用的源字符集,第二个GBK指的是编译器使用的执行字符集
GBK/GBK
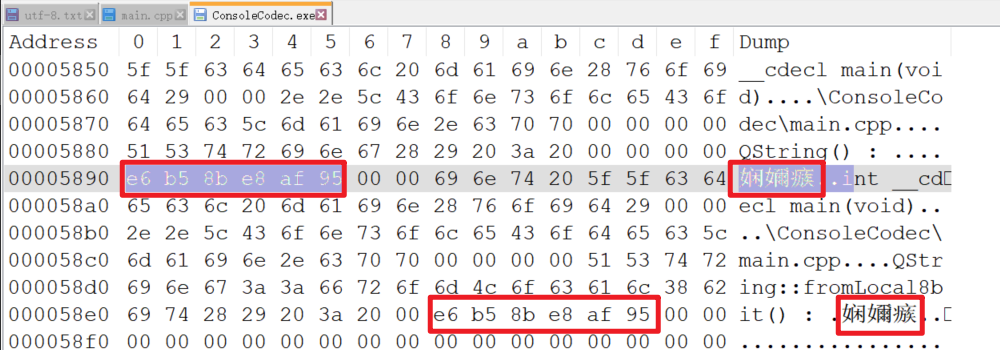
MSVC 默认以 GBK 格式读取文件,虽然 UTF-8 的二进制码是 “e6 b5 8b e8 af 95”,如果按照 GBK 来解析会是 “娴嬭瘯”,但是实际上在编译器眼里,在它不使用之前就是 “e6 b5 8b e8 af 95” 这样的字节流,它不关系内容,只要知道是个文本就行
因为 source-charset 和 execution-charset 都是 GBK,那么编译器没有必要对这个二进制进行编码转换,经过预编译等等环节之后,这个二进制码会被直接用在可执行文件中,使用 Notepad++ 查看一下 exe 文件验证一下想法,大概如下图
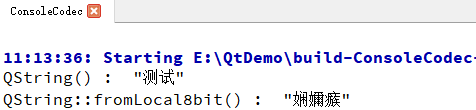
所以主要还是运行时 QString 如何处理这个二进制码 “e6 b5 8b e8 af 95” 比较关键
QString是按照UTF-8读取二进制字节流来解析,所以解析出来的刚好是“测试”QString::fromLocal8bit()是按照本地编码读,也就是GBK,就变成“娴嬭瘯”
Qt 的 QString() 初始化实际上更复杂一些,它会将二进制码当成 UTF-8 格式来解析,然后转码成 UTF-16 保存,也就是常说的 Unicode 码,和 GBK 一样是使用 2 个字节来表示一个字符,并且他们之间是兼容的,所以这里可以简单理解成,在运行阶段,如果它读取的中文的二进制码是对的,那么它的输出就是正确的
所以这里的 QString() 也就歪打正着最后呈现的时候没有乱码
UTF-8/GBK
Qt 的 pro 文件中添加编译参数,告诉编译器,我现在文件格式就是 utf-8
QMAKE_CXXFLAGS += /source-charset:utf-8
因为 source-charset 是 UTF-8 和 execution-charset 的 GBK 不一致,会在生成可执行程序的时候,会将 “e6 b5 8b e8 af 95” 转码成 GBK 形式下的 测试 的二进制码,而转码可以简单认为是先读出来是啥,然后再转
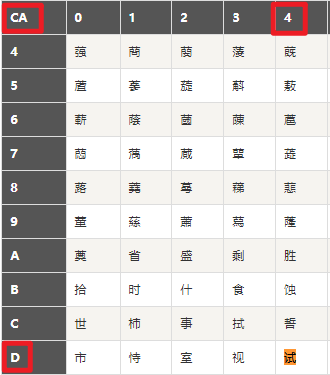
因为现在知道正确的文件编码是 UTF-8,所以知道 “e6 b5 8b e8 af 95” 就是字符 “测试”,接下来换成 GBK 对应的二进制码即可
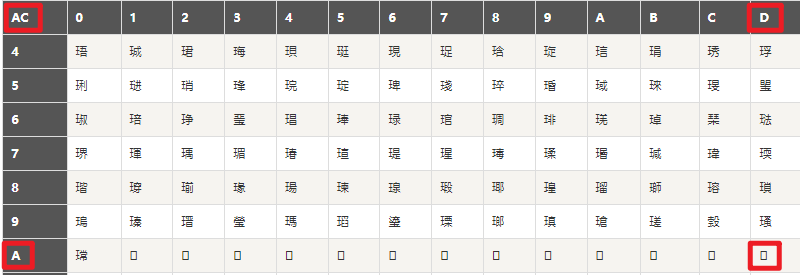
在这个网址下查找一下 http://tools.jb51.net/table/gbk_table
可以看出 GBK 下 “测试” 对应的编码是 “b2 e2 ca d4”
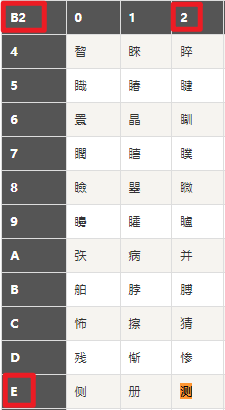
为了验证可执行文件中是否按照我们的思路做了转码,使用 Notepad++ 查看一下 exe 文件,大概如下图
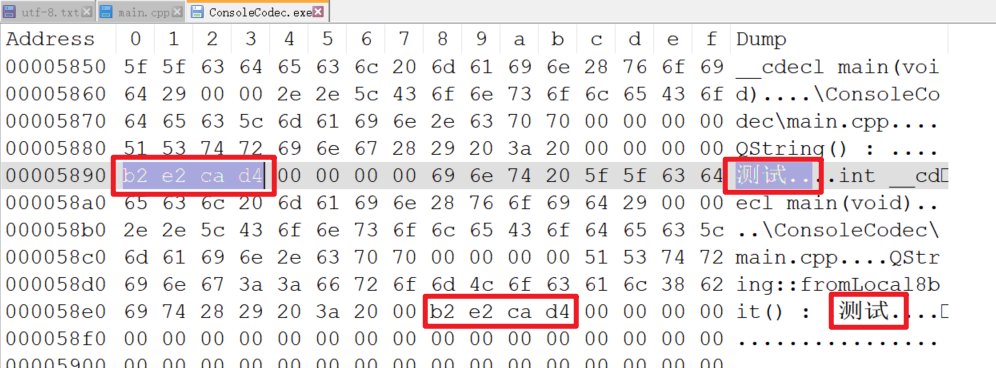
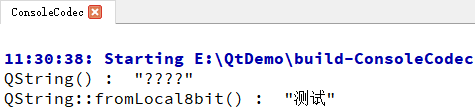
运行时候时
QString把“b2 e2 ca d4”当成UTF-8来解析,实际只会解析错误,应该会出现 4 个的问号QString::fromLocal8bit()是按照GBK解析,就是“测试”,所以正常
UTF-8/UTF-8
Qt 的 pro 文件中添加编译参数
QMAKE_CXXFLAGS += /source-charset:utf-8
QMAKE_CXXFLAGS += /execution-charset:utf-8
和 GBK/GBK 可能处理的方式差不多,生成的 exe 中不需要额外的转码,看一下 exe 的二进制也一样
QString按照UTF-8来解析“e6 b5 8b e8 af 95”,正好是“测试”QString::fromLocal8bit()是按照GBK解析就变成了“娴嬭瘯”
GBK/UTF-8
Qt 的 pro 文件中添加编译参数
QMAKE_CXXFLAGS += /execution-charset:utf-8
一样的思路,那么 MSVC 因为 source-charset 是 GBK 和 execution-charset 的 UTF-8 不一致,生成可执行文件需要对文件做一次 GBK 到 UTF-8 的转码,等于是把本来按照 UTF-8 来解释的 “测试” 的二进制 “e6 b5 8b e8 af 95” 当成 GBK 再转成 UTF-8,等于错上加错
我们自己先转一下,之后和 exe 进行对比,验证一下思路
“e6 b5 8b e8 af 95”按照GBK解释变成“娴嬭瘯”“娴嬭瘯”再逐个解释成UTF-8,为了省事,直接使用前面提到的网站进行转换
得到结果是 “e5 a8 b4 e5 ac ad e7 98 af”
对比 exe 看一下,符合预期
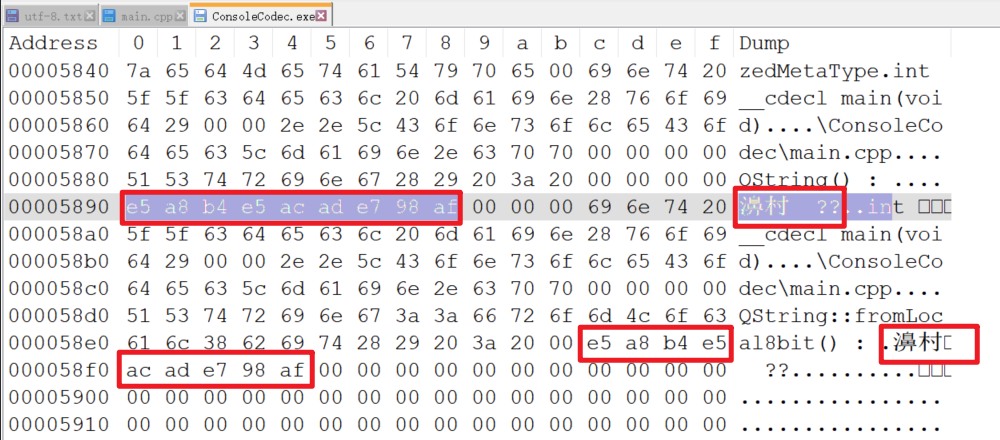
现在 exe 中保存的就是 “娴嬭瘯” 对应的 UTF-8 的编码
QString按照UTF-8来解析就是乱码是“娴嬭瘯”QString::fromLocal8bit()按照GBK解析就乱上加乱了
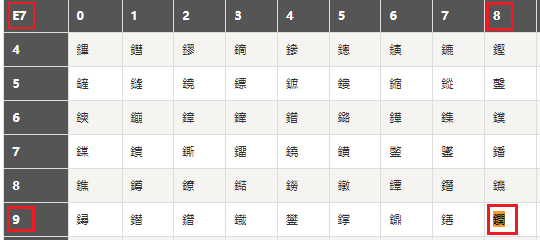
我们尝试 2 个字节 2 个字节的在这个 GBK 对照表的网站里尝试解析解析
http://tools.jb51.net/table/gbk_table
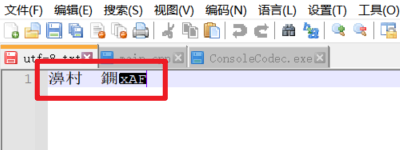
“e5a8”解析成“濞”“b4e5”解析成“村”“acad”空白“e798”解析成“鐦““af”不够 2 个字节,只能解析失败

看一下运行结果
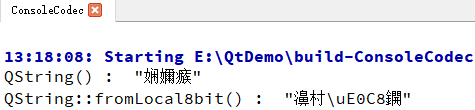
感觉差不多,仔细看本来时 “ac ad” 的2个字节,在这里打印的是 “\uE0C8”
“\u” 其实就是 Unicode 使用的标识符,也侧面说明 QString 内部其实也做了转码
在这个网站上 https://unicode-table.com/cn/ 找一下这个字符对应的内容,也是类似空白
其实 Unicode 码中 E000-F8FF 是私人使用区
私人使用区 维基百科解释如下,大致意思你们自己实现
在Unicode中,私人使用区(简称:私用区;英语:Private Use Areas,简称:PUA)指其解释未在Unicode标准中指定,而是由合作用户之间的私人协议决定其用途的一系列码位。 目前定义了三个私人使用区:一个在基本多语言平面(U+E000-U+F8FF)中,另外两个几乎包含了整个第15和第16平面(分别为U+F0000-U+FFFFD,U+100000-U+10FFFD)。
私人使用区字符的分配,可以不由字面意义上的“私人”决定。一些组织已经发布了一些分配计划。但根据其定义,私人使用区相同的代码点可分配为不同的字符,因此使用某种字体的用户看到其显示为一种形态,但使用其它字体的用户看到的字符可能完全不同。
使用 Notepad++ 看看,中间的变成空白,最后的一个字节 “af” 也在转换中显示出来了,其他和我们验证的一样
总结
以下总结是经过上面在 QT5.15.2+MSVC2017 以及源文件格式是 UTF-8 这种前提下,对 MSVC 编译器在编译出可执行文件过程的思路总结
首先有一个前提,windows 下如果不设置 源字符集 和 执行字符集,默认都是 GBK
并且对于 UTF-8 文件而言,MSVC 编译器其实不能直接识别出文件类型来解析文件,所以使用默认本地字符集 GBK 作为源字符集来预处理文件,编译器会根据是否和 执行字符集 一致来决定生成可执行文件的过程中是否需要转码
UTF-8带BOM的文件MSVC是可以识别出类型的,把文件当成UTF-8来处理
所以不想出现乱码,这里分 2 种情况分别解释一下措施
-
源字符集和执行字符集一致,就需要保证使用正确的QString接口来保证正确读取二进制数据比如你文件编码是
VS默认下的GB2312,就应该使用QString::fromLocal8bit()
如果你文件编码是UTF-8,直接使用QString()即可 -
不一致,需要转码,那么就需要保证转码的过程没有错误
设置好
源字符集保证代码不被编译器理解错误
执行字符集设置的是UTF-8就使用QString()
执行字符集设置的是GBK就使用QString::fromLocal8bit()
其实我的建议是在 windows 下:
source-charset根据实际文件格式设置好execution-charset根据代码中的调用QString具体哪种方法也设置好,而且方法也需要统一了
而设置 源字符集 和 执行字符集 的方法特别多,我简单列几个
编译器层面
Qt pro 文件中配置编译参数
QMAKE_CXXFLAGS += /source-charset:utf-8
QMAKE_CXXFLAGS += /execution-charset:utf-8
VS 下可以额外配置编译参数
- 打开项目
"属性页"对话框。 - 选择
"配置属性">"c/c++">"命令行"属性页。 - 在
"其他选项"中,添加/source-charset或者/execution-charset选项,并指定首选编码。 - 选择
"确定"以保存更改。
二者都支持不特别指定,直接写 /utf-8 这样
// Qt
QMAKE_CXXFLAGS += /utf-8
// MSVC
/utf-8
代表同时设置 /source-charset 和 /execution-charset 为 utf-8
代码层面
文件中指定一下转码规则,它是告诉 QString::fromLocal8bit 以 UTF-8 读取字节流
QTextCodec *codec = QTextCodec::codecForName("utf-8");
QTextCodec::setCodecForLocale(codec);
或者在文件中添加宏,这个是告诉 MSVC 编译器 execution-charset 是 UTF-8
#pragma execution_character_set("utf-8")
测试一下
出道题,结合题目想想是否真的理解透了
Linux系统下使用gcc作为编译器,已知在不特地设置source-charset和execution-charset的时候,默认都是UTF-8
项目的文件格式是GB2312, 代码中使用的是QString(), 在Linux下使用gcc编译会出现乱码吗,如果出现乱码应该如何解决?
这个项目如果git clone到windows下使用MSVC编译会出现乱码吗? 如果出现如何解决?
感兴趣的可以评论写写答案


















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











