







 本文介绍了ROI-Pooling在神经网络中的作用,解释了其解决固定输入尺寸问题的背景。详细阐述了ROI-Pooling的前向传播和反向传播过程,包括如何计算最大值及对应的索引。最后提到了max-pooling的类似过程,并给出了相关代码参考链接。
本文介绍了ROI-Pooling在神经网络中的作用,解释了其解决固定输入尺寸问题的背景。详细阐述了ROI-Pooling的前向传播和反向传播过程,包括如何计算最大值及对应的索引。最后提到了max-pooling的类似过程,并给出了相关代码参考链接。
roi-pooling
背景介绍
卷积可以对任意图像进行,并变成任意大小,因为卷积需要训练的参数是卷积核,卷积核的大小一旦设定好就是固定不变的。但是进行判断时候,从卷积变线性回归的时候,就需要固定输入尺寸。因为线性回归的w和b会根据输入的大小而改变的。
为了解决含有线性回归需要固定输入,而对测试图片能任意输入(resize输入图片可能会使特征改变)。就提出了roi-poling。
roi-pooling的原理
梯度反向传播
需要重写max-pooling函数需要对神经网络的这个求优过程有一定的了解。
首先神经网络的本质是什么,他可以看成是有很多参数的函数,通过和大量数据进行拟合,找出这些数据的规律。
如何对这些参数进行优化呢,这就涉及一个初中就学过的知识-梯度。梯度负方向是函数下降最快的地方,当这种下降减少到一定程度,可以认为达到局部最优解。将原始值减去梯度,不断循环该过程,能得到最优解。这个过程也叫梯度下降法。
如果只是单一的导数,很好理解,但是神经网络是含有很多层的,这就涉及到了链式法则。下图是单一的一个过程。这个过程分为了前向传播和后向传播。前向是将数据输入到网络,得到一个值z,反向是计算loss(预期和计算的一个差值或者是特定的loss)和z的梯度,再将这个梯度传回网络其它地方。
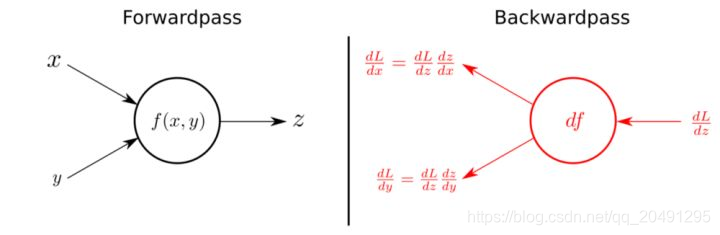
max-pooling的前后向传播
forward:只需要拿走这个区域的最大值,下图左边是原矩阵,右侧是maxpooling后的结果

"""
a为输入矩阵
[[ 0 1 2 3]
[20 5 21 7]
[22 9 10 11]
[12 13 14 15]]
"""
a = np.arange(16).reshape((4,4))
a[1][0]= 20
a[1][2]= 21
a[2][0]= 22
kernel_size 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









