







创建项目
# Pycharm的Termianl
django-admin startproject Django .启动项目
python3 manage.py runserver 0.0.0.0:8888
默认项目文件
mysite
├── manage.py 【项目的管理,启动项目、创建app、数据管理】【不要动】【***常常用***】
└── mysite
├── __init__.py
├── settings.py 【项目配置】 【***常常修改***】
├── urls.py 【URL和函数的对应关系】【***常常修改***】
├── asgi.py 【接收网络请求】【不要动】
└── wsgi.py 【接收网络请求】【不要动】应用
创建子应用
意义:将各个子功能模块保持独立,达到解耦。也可以达到复用。
# Pycharm的Termianl
python3 manage.py startapp projects├── projects
│ ├── __init__.py 包文件
│ ├── admin.py 【固定,不用动】用于配置admin后台管理站点。
│ ├── apps.py 【固定,不用动】用于配置子应用信息。
│ ├── migrations 【固定,不用动】用于存放迁移脚本,数据库变更记录
│ │ └── __init__.py
│ ├── models.py 【**重要**】用于定义模型类。
│ ├── tests.py 【固定,不用动】单元测试
│ └── views.py 【**重要**】编写子应用业务逻辑的模块。
├── manage.py
└── mysite2
├── __init__.py
├── asgi.py
├── settings.py
├── urls.py 【URL->函数】
└── wsgi.py注册应用
第一种:将子应用名追加到根项目里的settings里
第二种:将子应用app里的函数名,追加到根项目里的settings里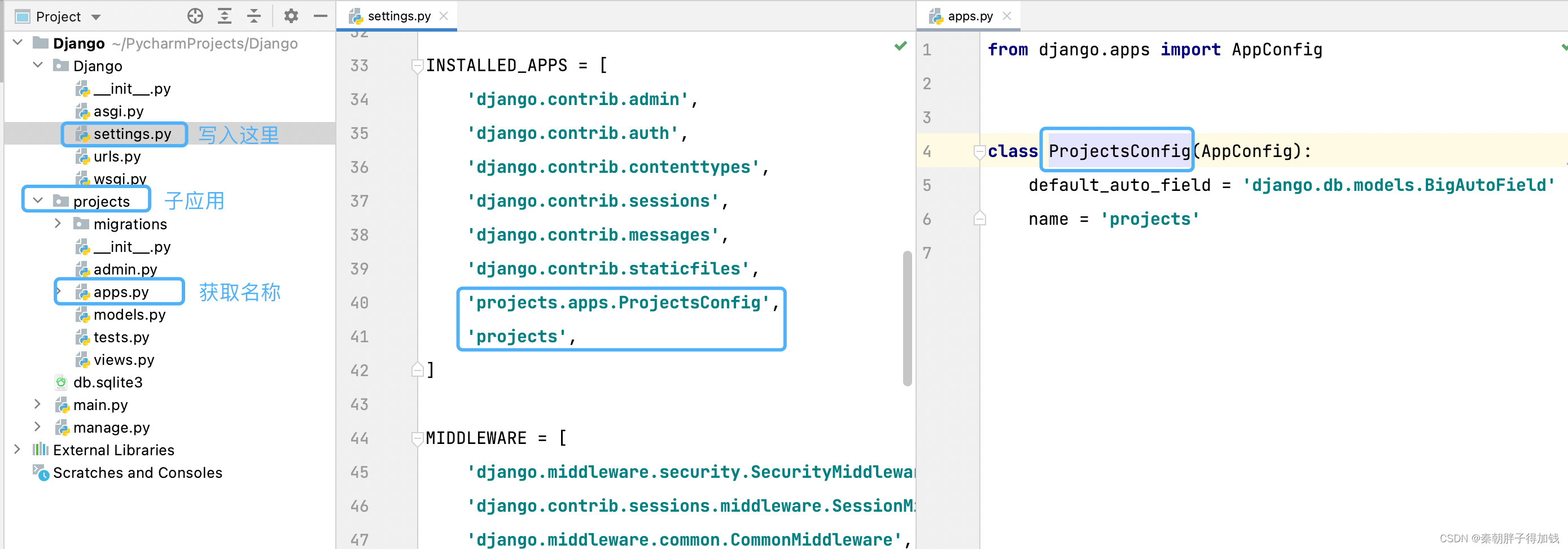
视图函数
在子应用views.py文件中定义的函数叫视图函数。
路由
定义路由
request是一个对象,封装了用户通过浏览器发送过来的所有数据。
# 什么是路由?
指URL与后端视图之间的一一映射关系
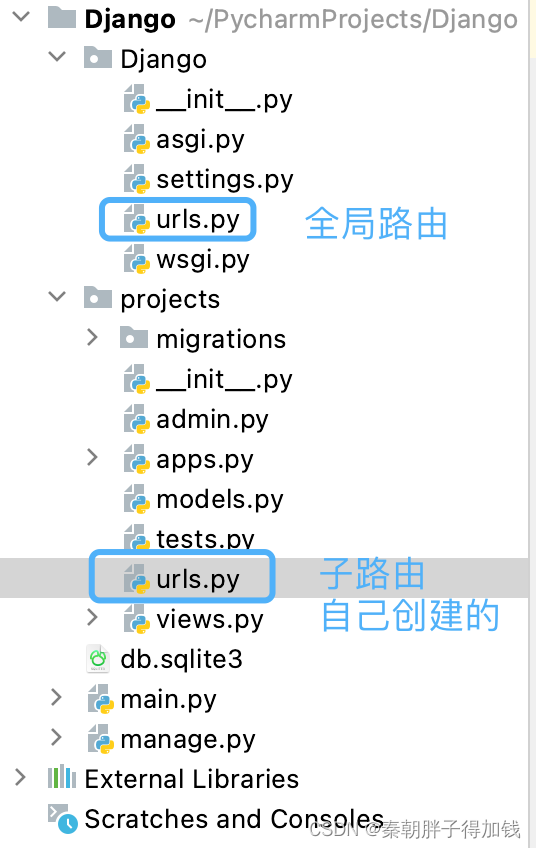
# 全局路由
根路径下的urls
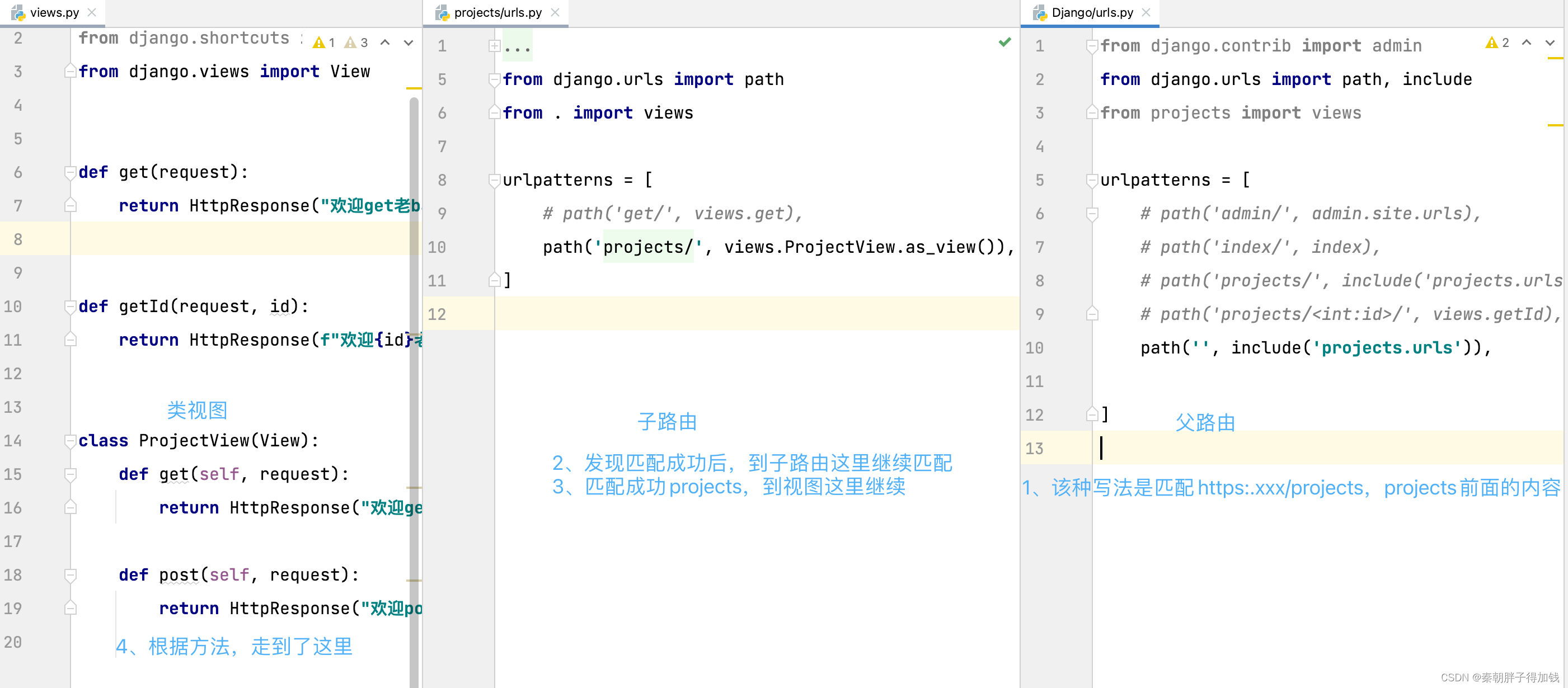
# 子路由
在子应用下手动创建的urls
# 如何添加路由?
1. 需要在全局路由文件中urls.py,urlpatterns列表中添加路由条目。
2. urlpatterns列表条目总数就是路由总数。
# 路由如何匹配
1. 路由匹配规则是从上到下全等匹配。(路由寻址)
2. 匹配成功则停止匹配。
3. 若条目全都不匹配,则抛出404异常。
# path函数
1. 用于定义路由条目。
2. 第一个参数是url路径参数字符串,只需在后面加/。
3. 第二个参数为视图函数或类视图,如果添加的是视图函数,无需使用()调用。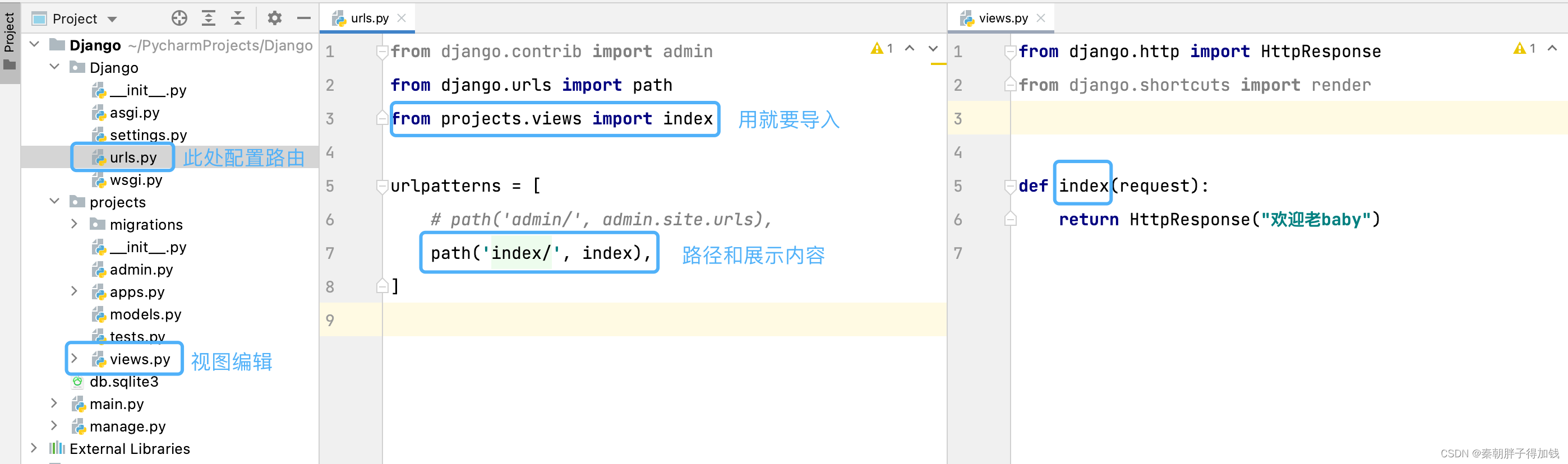
子路由
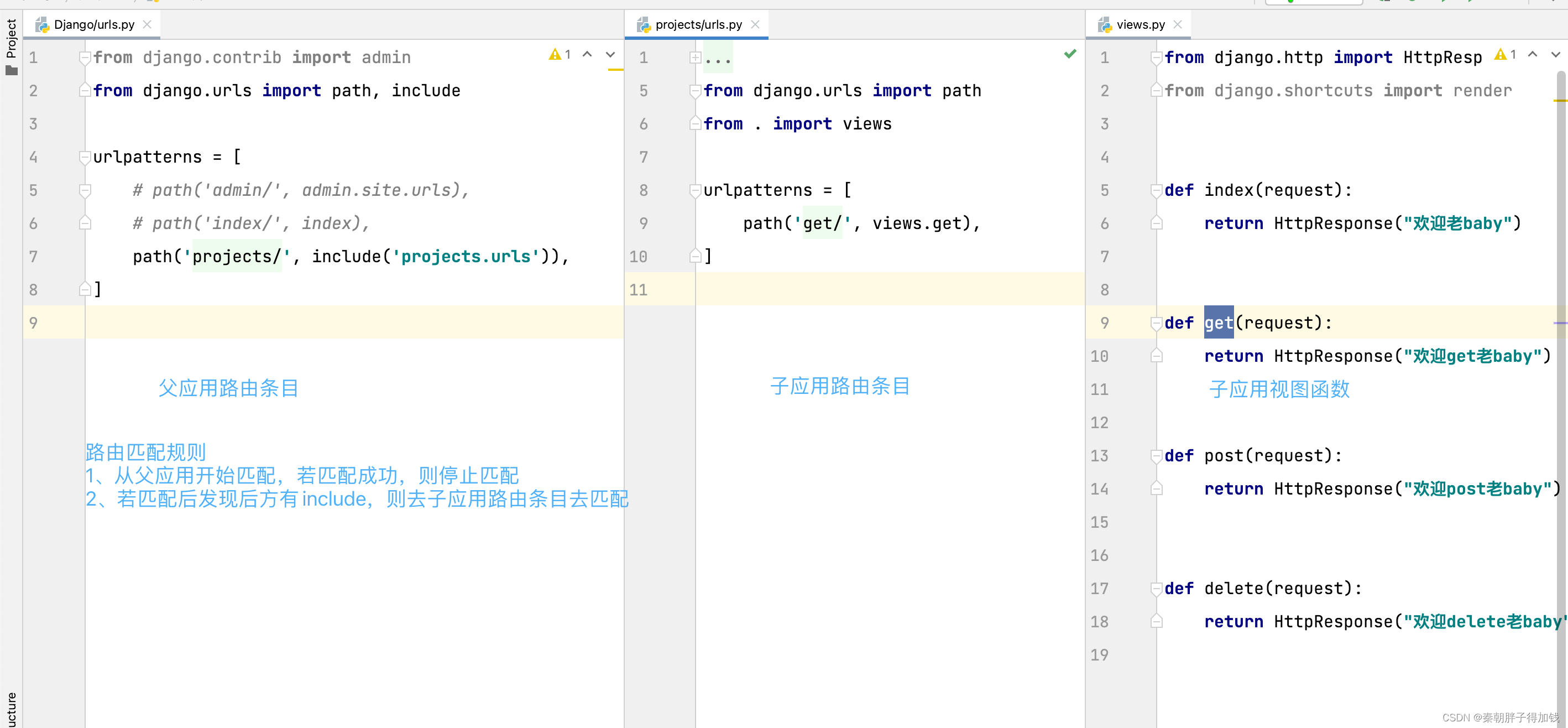
路由中带有数值变量
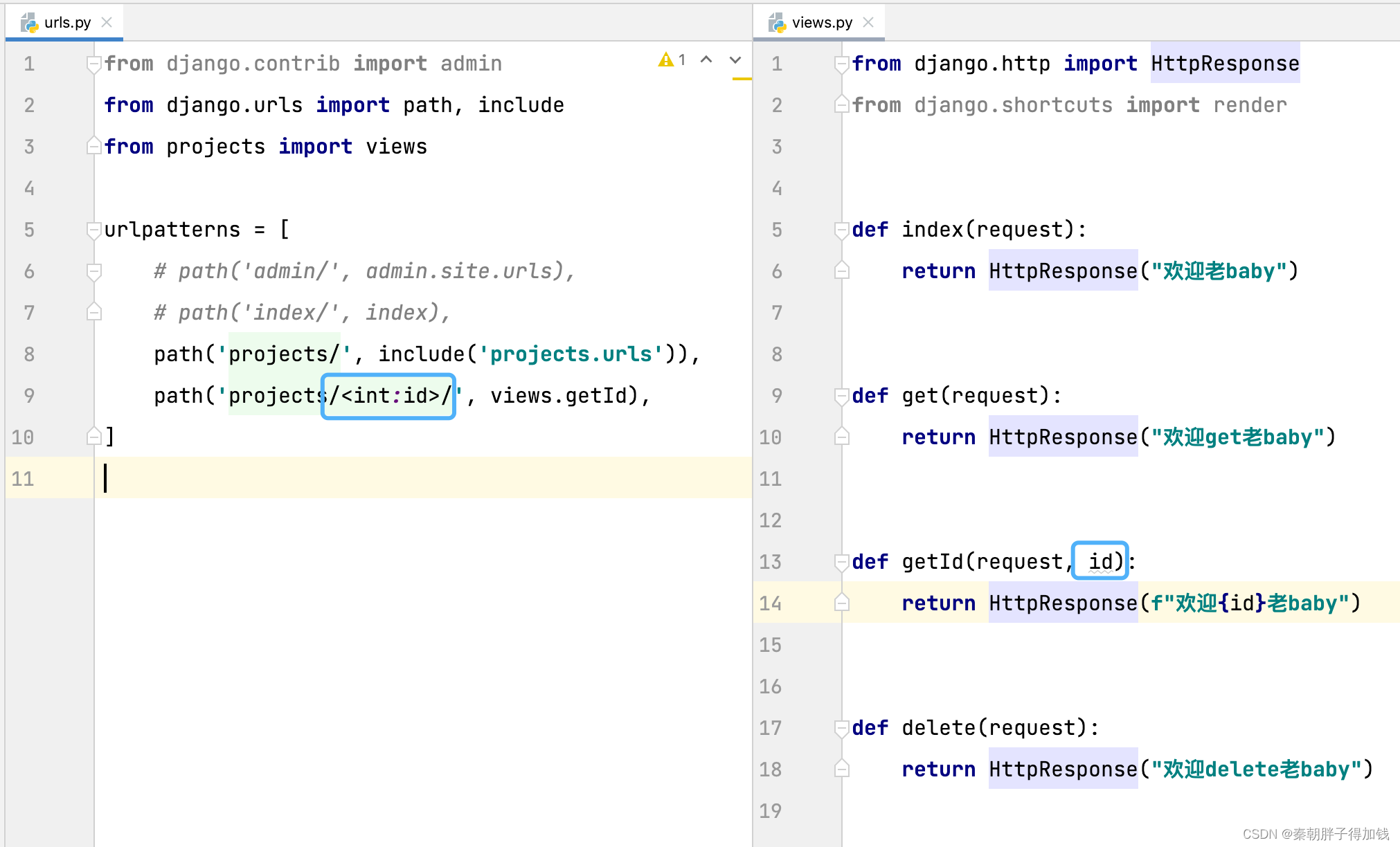
关闭csrf安全认证

类视图
路由中带有数值变量
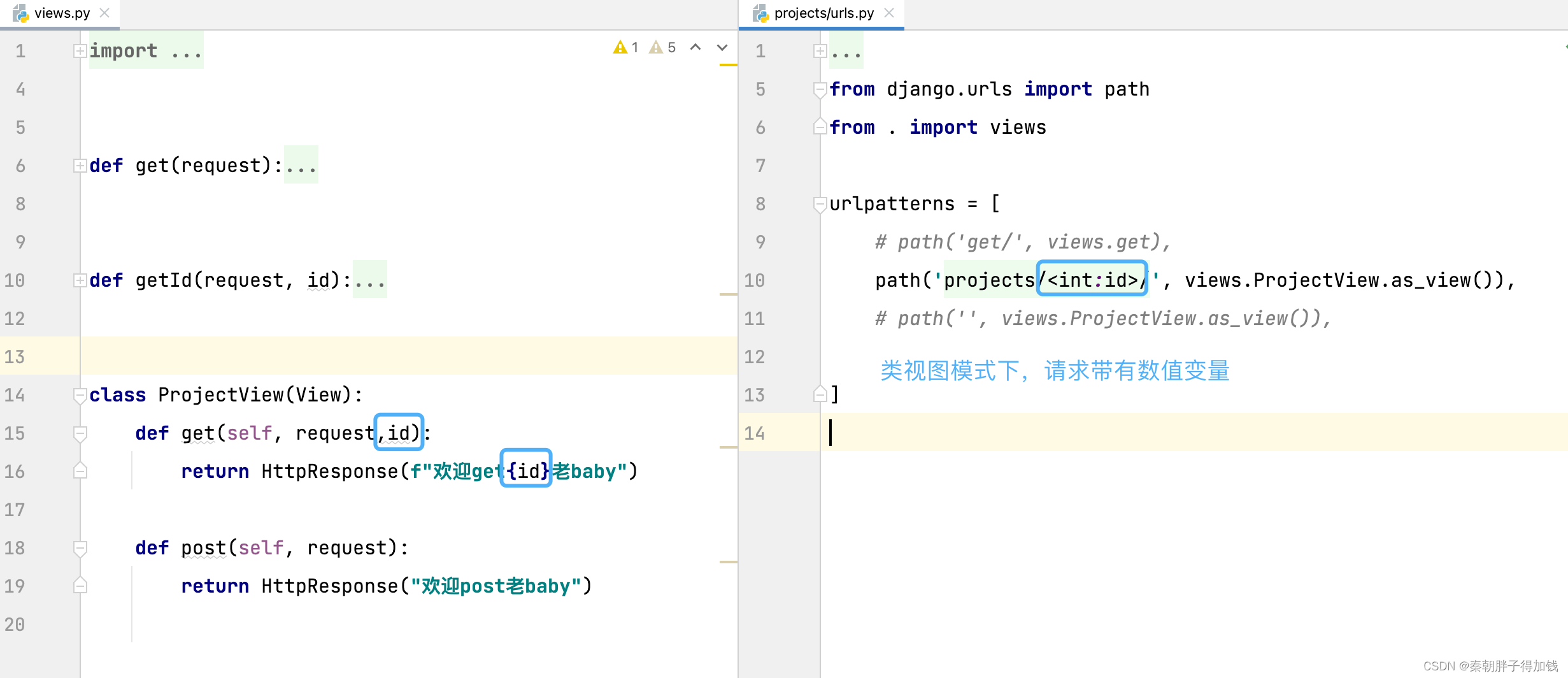
返回json数据
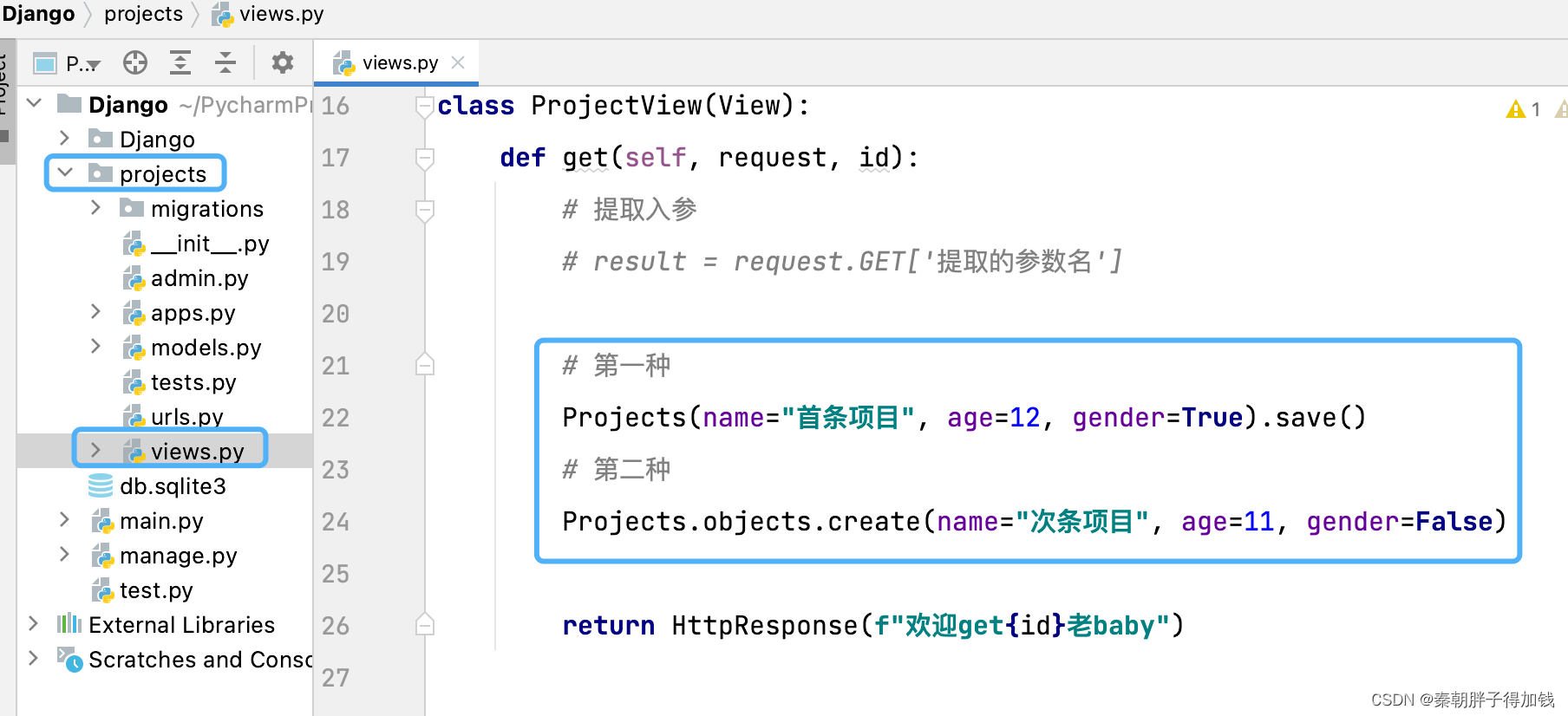
class ProjectView(View):
def get(self, request, id):
return HttpResponse(f"欢迎get{id}老baby")
def post(self, request):
result = {"msg": "登录超时,请重新登录", "code": 60001}
# 1、第一种
str = json.dumps(result, ensure_ascii=False)
# content_type输出格式是json格式
return HttpResponse(str, content_type="application/json")
# 2、第二种,不用转json格式了,直接返回json格式
return JsonResponse(result,json_dumps_params={"ensure_ascii":False})
# 3、第三种,可以返回多种格式,关闭安全模式
return JsonResponse(result, json_dumps_params={"ensure_ascii": False},safe=False)提取入参
def post(self, request):
# 1、提取入参,表单形式,x-www-form-urlencoded
result = request.POST['提取的参数名']
# 2、提取入参,Json形式
result = json.loads(request.body)
# 3、提取入参,文件,文件流,他是个文件流,form-data
request.FILES
# 4、提取入参,文件,文件流,binary
request.body
# 5、提取入参,请求头headers
result = request.headers['提取的参数名']
result = request.META['HTTP_大写提取的参数名']
数据库
ORM框架
数据库:需要提前手动创建数据库
数据表:与ORM框架中的模型类一一对应
字段:模型类中的类属性(Field子类)
记录:类似于模型类的多个实例
设置库类型

创建迁移文件/脚本
projects为创建的所在项目,子应用名
python3 manage.py makemigrations 子应用名 迁移数据库
# 迁移也就是创建/更新数据库表
python3 manage.py migrate projects 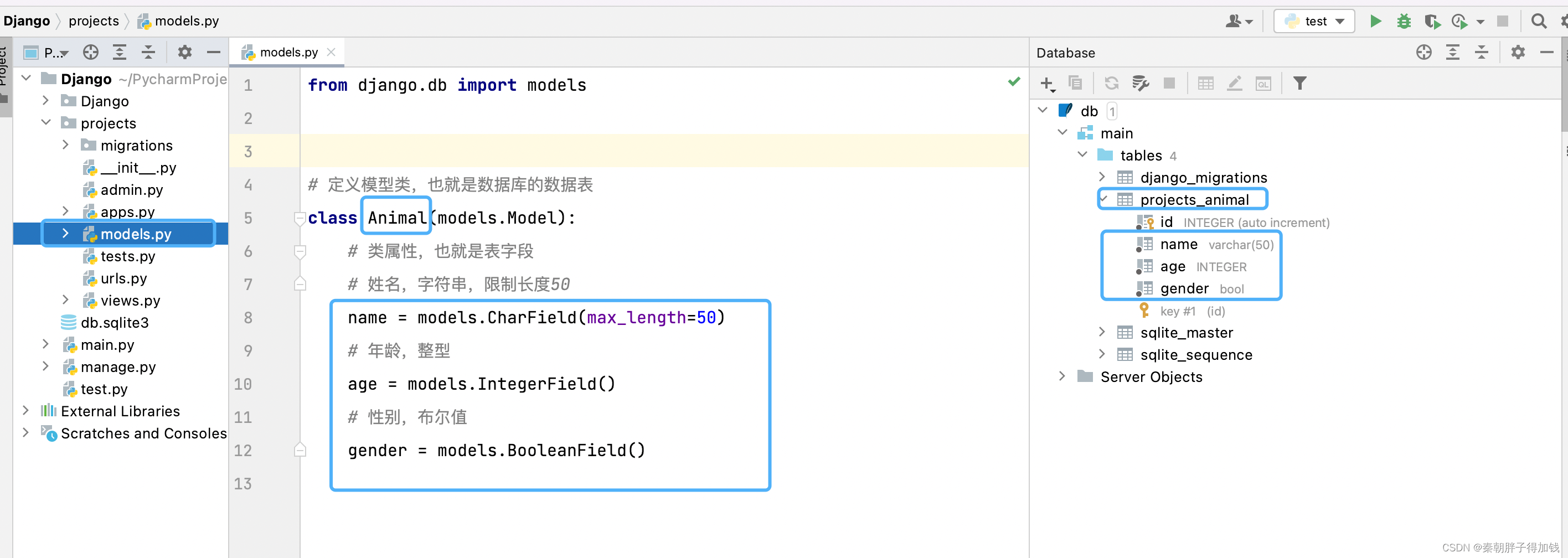
class Projects(models.Model):
# 类属性,也就是表字段
# 姓名,字符串,最长256字节,限制长度50,unique设置值唯一
name = models.CharField(max_length=50, unique=True, verbose_name="姓名", help_text="姓名")
# 年龄,整型
age = models.IntegerField(verbose_name="年龄", help_text="年龄")
# 性别,布尔值,默认为True
gender = models.BooleanField(default=True, verbose_name="性别", help_text="性别")
# 备注,长文本,null前端入参可为null,blank可不填
console = models.TextField(null=True, blank=True, default="没啥可备注的", verbose_name="备注", help_text="备注")
# 创建时间,创建记录时,自动将当前时间作为该字段值。
createTime = models.DateTimeField(auto_now_add=True, verbose_name="创建时间", help_text="创建时间")
# 更新时间,更新记录时,自动将当前时间作为该字段值。
updateTime = models.DateTimeField(auto_now=True, verbose_name="更新时间", help_text="更新时间")
# 在模型类内创建一个Meta内部类,用于修改数据库的元数据信息
class Meta:
# 指定创建的数据表名称
db_table = "tb_project"有表变动则执行:创建迁移脚本- 执行迁移脚本
项目初始化数据库
python3 manage.py makemigrations
python manage.py migrate
公用模块

ADUS
父表和从表定义

# a.如果需要创建一对多的外键,那么会在“多”的那一个模型类中定义外键字段
# b.如果创建的是一对多的关系,使用ForeignKey
# c.如果创建的是一对一的关系,可以在任何一个模型类使用OneToOneField
# d.如果创建的是多对多的关系,可以在任何一个模型类使用ManyToManyField
# e.ForeignKey第一个参数为必传参数,指定需要关联的父表模型类
# 方式一:直接使用父表模型类的引用
# 方式二:可以使用'子应用名称.父表模型类名'(推荐)
# f.ForeignKey需要使用on_delete指定级联删除策略
# CASCADE: 当父表数据删除时,相对应的从表数据会被自动删除
# SET_NULL:当父表数据删除时,相对应的从表数据会被自动设置为null值
# PROTECT:当父表数据删除时,如果有相对应的从表数据会抛出异常
# SET_DEFAULT: 当父表数据删除时,相对应的从表数据会被自动设置为默认值,还需要额外指定default=True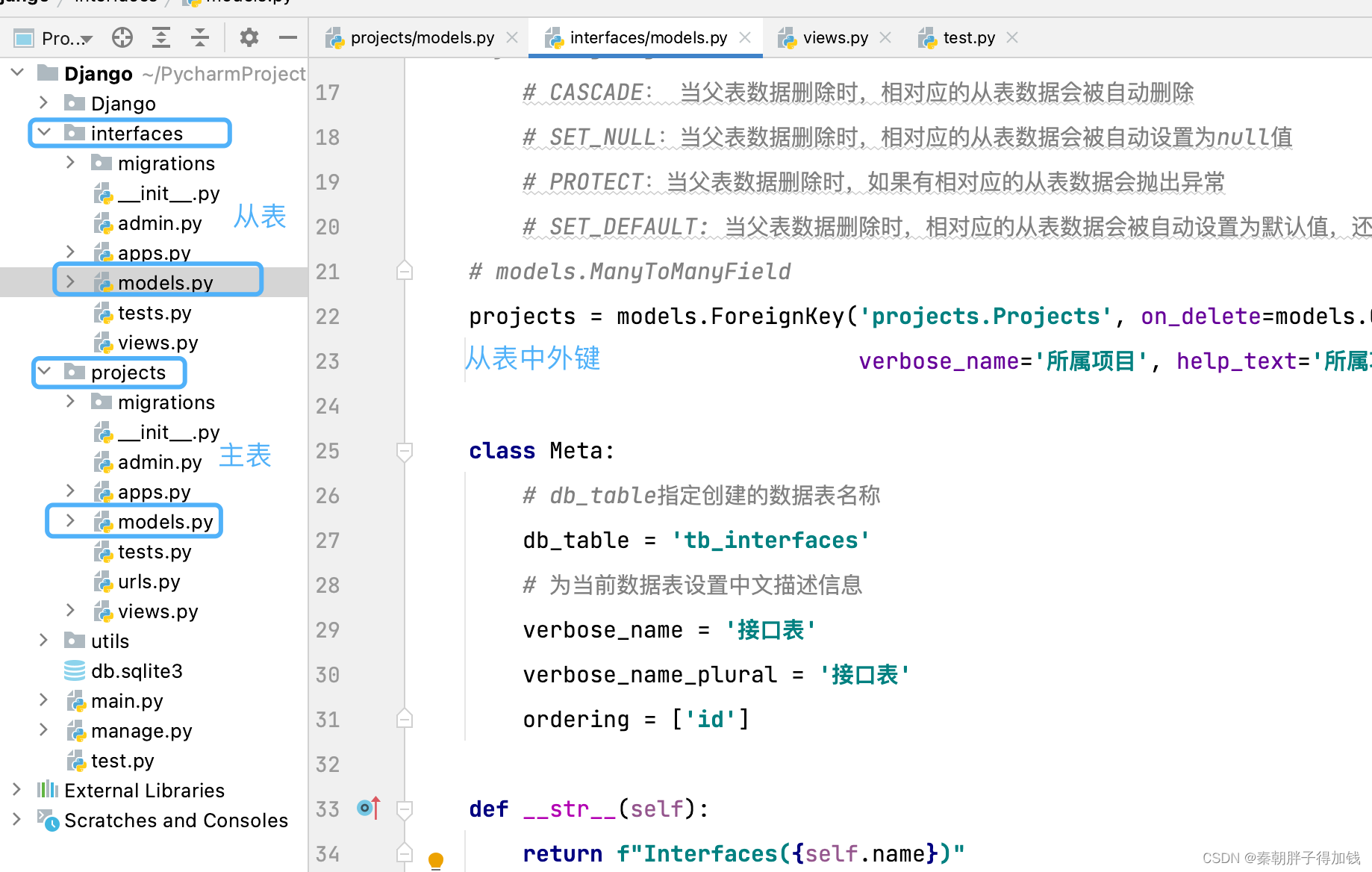
QuerySet查询集对象
其特性
1)支持链式调用:可以在查询集上多次调用filter、exclude方法,每次调用这些方法时,都会返回一个新的QuerySet实例
2)惰性查询:仅仅在使用数据时才会执行sql语句,为了提升数据库读写性能
会执行sql语句的场景:len()、.count()、通过索引取值、print、for
qs = Projects.objects.values('id').annotate(Count('interfaces'))
QuerySet查询集对象和列表类似,列表嵌套字典
可以用for遍历,查询出的是模型对象,可以用.属性提取
econdData = Projects.objects.filter(name="巴拉巴拉")
# QuerySet查询集第一个
secondData.first()
secondData[0]
# QuerySet查询集最后一个
secondData.last()
# QuerySet查询集的数量/长度
secondData.count()
len(secondData)
# QuerySet查询集是否为空,返回True或Fasle
secondData.exists()manage对象
模型类.objects返回manager对象
Projects.objectsfilter过滤
# 大于
Projects.objects.filter(id__gt=1)
# 大于等于
Projects.objects.filter(id__gte=1)
# 小于
Projects.objects.filter(id__lt=1)
# 小于等于
Projects.objects.filter(id__lte=1)
# 指定字段模糊查询。
Projects.objects.filter(name__contains="yue")
# 指定字段模糊查询,忽略大小写。
Projects.objects.filter(name__icontains="yue")
# 查询字段值在指定区域内,id是123的都符合
Projects.objects.filter(id__in=[1, 2, 3])
# 以什么开头。
Projects.objects.filter(name__startswith="yu")
# 以什么开头,忽略大小写。
Projects.objects.filter(name__istartswith="Yu")
# 以什么结尾。
Projects.objects.filter(name__endswith="yu")
# 以什么结尾,忽略大小写。
Projects.objects.filter(name__iendswith="Yu")
# exclude为反向查询,filter方法支持的所有查询类型,都支持
Projects.objects.exclude(name__iendswith="Yu")
增
正常增加
父表中创建从表数据
# 创建从表数据
# 外键对应的父表如何传递?
""" 方式一:
1)先获取父表模型对象
2)将获取的父表模型对象以外键字段名作为参数来传递 """
project_obj = Projects.objects.get(name='在线图书项目')
interface_obj = Interfaces.objects.create(name='在线图书项目-登录接口', tester='珍惜',projects=project_obj)
""" 方式二:
1)先获取父表模型对象,进而获取父表数据的id值
2)将父表数据的主键id值以外键名_id作为参数来传递"""
interface_obj = Interfaces.objects.create(name='在线图书项目-注册接口', tester='珍惜',projects_id=project_obj.id)
删
"""方式一:一条数据"""
project_obj = Projects.objects.get(id=1)
project_obj.delete()
"""方式二:多条数据"""
Projects.objects.filter(name__contains='2').delete()改
"""
方式一:一条数据
1)必须调用save方法才会执行sql语句,并且默认进行完整更新
2)可以在save方法中设置update_fields参数(序列类型),指定需要更新的字段名称(字符串)
"""
project_obj = Projects.objects.get(id=1)
project_obj.name = '在线图书项目(一期)'
project_obj.leader = '不语'
project_obj.save(update_fields=["name","leader"])
"""
方式一:多条数据
在QuerySet对象.update(字段名称='字段值',字段名称='字段值'),返回修改成功的值,无需调用save方法
"""
Projects.objects.filter(name__contains='2').update(leader='珍惜')查
正常查询
class ProjectView(View):
def get(self, request, id):
""" 第一种,只能查单条数据,结果不存在或超出1个会报错,返回的是模型对象。"""
firstData = Projects.objects.get(name="巴拉巴拉")
""" 第二种,结果不存在不报错,返回的是QuerySet查询集对象。"""
secondData = Projects.objects.filter(name="巴拉巴拉")
""" QuerySet查询集第一个 """
secondData.first()
secondData[0]
""" QuerySet查询集最后一个 """
secondData.last()
""" QuerySet查询集的数量 """
secondData.count()
""" 查所有数据,返回的是QuerySet查询集对象。"""
allData = Projects.objects.all()主表参数为条件获取从表数据
""" 目的:查主表中leader为多喝热水的,在从表中接口都是什么。"""
# 以从表入手!从表查询集(外键名__代表主表的引用,leader为主表字段的过滤)。
Interfaces.objects.filter(projects__leader="多喝热水")
""" 目的:查主表projects中leader包含漂亮的,在从表中有多少个接口。"""
# 以从表入手!从表查询集(projects__是父表的引用,leader__contains="大漂亮"是父表的字段模糊筛选)
Interfaces.objects.filter(projects__leader__contains="漂亮")
# 不常用
# 以主表入手!主表查询集第一个(leader__contains="漂亮")[0],从表模型类名_set.all(),返回的是查询集
Projects.objects.filter(leader__contains="漂亮")[0].interfaces_set.all()
从表参数为条件获取主表数据
""" 目的:查从表中接口名包含登录的接口,在主表中哪个项目里."""
# 不常用
#从表查询集(name__contains="登录"),第一个模型对象.first()的.从表的外键字段projects
Interfaces.objects.filter(name__contains="登录").first().projects
Projects.objects.filter(interfaces__name__contains='登录')
分组查询
a.可以使用QuerySet对象.values('父表主键id').annotate(聚合函数('从表模型类名小写'))
b.会自动连接两张表,然后使用外键字段作为分组条件聚合查询
可以使用QuerySet对象.aggregate(聚合函数('字段名'))方法,返回字典数据
b.返回的字典数据中key为字段名__聚合函数名小写
c.可以使用关键字参数形式,那么返回的字典数据中key为关键字参数名
qs = Projects.objects.filter(name__contains='2').aggregate(Count('id'))抽出来的表公用字段
外键
class Interfaces(BaseModel):
name = models.CharField(verbose_name='接口名称', help_text='接口名称', max_length=20, unique=True)
tester = models.CharField(verbose_name='测试人员', help_text='测试人员', max_length=10)
"""
外键字段在表中会自动追加一个_id
a.如果需要创建一对多的外键,那么会在“多”的那一个模型类中定义外键字段
b.如果创建的是一对多的关系,使用ForeignKey
c.如果创建的是一对一的关系,可以在任何一个模型类使用OneToOneField
d.如果创建的是多对多的关系,可以在任何一个模型类使用ManyToManyField
e.ForeignKey第一个参数为必传参数,指定需要关联的父表模型类
方式一:直接使用父表模型类的引用
方式二:可以使用'子应用名称.父表模型类名'(推荐)
f.ForeignKey需要使用on_delete指定级联删除策略
CASCADE: 当父表数据删除时,相对应的从表数据会被自动删除
SET_NULL:当父表数据删除时,相对应的从表数据会被自动设置为null值
PROTECT:当父表数据删除时,如果有相对应的从表数据会抛出异常
SET_DEFAULT: 当父表数据删除时,相对应的从表数据会被自动设置为默认值,还需要额外指定default=True
"""
projects = models.ForeignKey('projects.Projects', on_delete=models.CASCADE,
verbose_name='所属项目', help_text='所属项目')
class Meta:
# db_table指定创建的数据表名称
db_table = 'tb_interfaces'
# 为当前数据表设置中文描述信息
verbose_name = '接口表'
verbose_name_plural = '接口表'
ordering = ['id']
def __str__(self):
return f"Interfaces({self.name})"
表
from django.db import models
from utils.base_model import BaseModel
class Animal(models.Model):
"""
1)一般在子应用models.py中定义模型类(相当于数据库中的一张表)
2)必须继承Model或者Model的子类
3)在模型类中定义类属性(必须得为Field子类)相当于数据表中字段
4)CharField ---> varchar
IntegerField ---> integer
BooleanField ---> bool
5)在migrations里,存放迁移脚本:
python manage.py makemigrations 子应用名(如果不指定子应用名,会把所有子应用生成迁移脚本)
6)查询迁移脚本生成的SQL语句:python manage.py sqlmigrate 子应用名 迁移脚本名(无需加.py)
7)生成的数据表名称默认为:子应用名_模型类名小写
8)默认会自动创建一个名为id的自增主键
"""
# varchar
name = models.CharField(max_length=50)
age = models.IntegerField()
gender = models.BooleanField()
class Projects(BaseModel):
# 在一个模型类中仅仅只能为一个字段指定primary_key=True
# 一旦在模型类中的某个字段上指定了primary_key=True,那么ORM框架就不会自动创建名称为id的主键
# a.CharField类型必须指定max_length参数(改字段的最大字节数)
# b.如果需要给一个字段添加唯一约束,unique=True(默认为False)
name = models.CharField(max_length=20, verbose_name='项目名称', help_text='项目名称', unique=True)
leader = models.CharField(max_length=10, verbose_name='项目负责人', help_text='项目负责人')
# c.使用default指定默认值(如果指定默认值后,在创建记录时,改字段传递,会使用默认值)
is_execute = models.BooleanField(verbose_name='是否启动项目', help_text='是否启动项目', default=True)
# d.null=True指定前端创建数据时,可以指定该字段为null,默认为null=False,DRF进行反序列化器输入时才有效
# e.blank=True指定前端创建数据时,可以指定该字段为空字符串,默认为blank=False,DRF进行反序列化器输入时才有效
desc = models.TextField(verbose_name='项目描述信息', help_text='项目描述信息', null=True, blank=True, default='')
# h.可以在任意一个模型类中创建Meta内部类,用于修改数据库的元数据信息
class Meta:
# i.db_table指定创建的数据表名称
db_table = 'tb_projects'
# 为当前数据表设置中文描述信息
verbose_name = '项目表'
verbose_name_plural = '项目表'
# 排序
ordering = ['id']
def __str__(self):
return f"Projects({self.name})"
逻辑关系
与,条件均为真或均符合,则成立
""" 方式一:在同一个filter方法内部,添加多个关键字参数,那么每个条件为“与”的关系"""
Projects.objects.filter(name__contains='2', leader='keyou')
""" 方式二:可以多次调用filter方法,那么filter方法的条件为“与”的关系,QuerySet链式调用特性"""
Projects.objects.filter(name__contains='2').filter(leader='keyou')
""" 方式三:可以使用Q方法,& 为与关系"""
Projects.objects.filter(Q(name__contains='2') & Q(leader='keyou'))
或,条件符合一个,则成立
"""使用Q查询,实现逻辑关系,多个Q对象之间使用“|”,为“或”关系"""
Projects.objects.filter(Q(name__contains='2') | Q(leader='多喝热水'))排序
"""使用QuerySet对象(manager对象).order_by('字段名1', '字段名2', '-字段名3')
默认为ASC升序,可以在字段名称前添加“-”,那么为DESC降序"""
Projects.objects.filter(Q(name__contains='2') | Q(leader='多喝热水')).order_by('-name', 'leader')Restful设计风格

DRF框架/Rest Framework框架
序列化:将查询集和模型对象转化为Python常用的数据类型。
反序列化:将Python常用的数据类型转化为查询集和模型对象

基础配置
尽量置放到子应用名上方
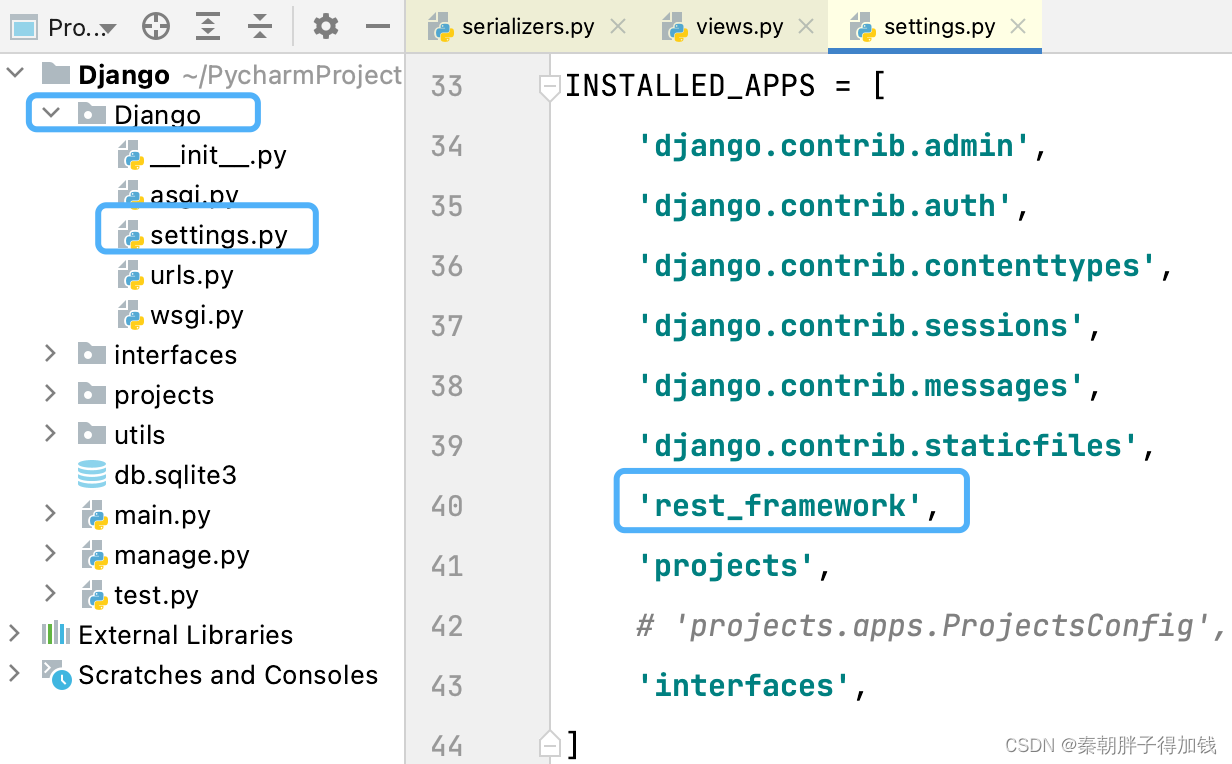
定义序列化器

基本理念
class ProjectSerilizer(serializers.Serializer):
"""
二、定义序列化器类
1.必须得继承Serializer类或者Serializer子类
2.定义的序列化器类中,字段名要与模型类中的字段名保持一致
IntegerField -> int
CharField -> str
BooleanField -> bool
DateTimeField -> datetime
3.定义的序列化器类的字段(类属性)为Field子类,与模型类中字段类型基本一致。
4.默认定义的字段,要求前端必须入参且会返回前端。
5.可以在序列化器字段中指定不同的选项
label和help_text,与模型类中的verbose_name和help_text参数一样
IntegerField,可以使用max_value指定最大值,min_value指定最小值
CharField,可以使用max_length指定最大长度,min_length指定最小长度
"""序列化器字段

id = serializers.IntegerField(label='项目id', help_text='项目id', max_value=1000, min_value=1)
name = serializers.CharField(max_length=20, min_length=5, write_only=True)
name = serializers.CharField(max_length=20, min_length=5, read_only=True)
name = serializers.CharField(max_length=20, min_length=5)
leader = serializers.CharField(allow_null=True)
leader = serializers.CharField(allow_blank=True)
leader = serializers.CharField(default='阿名')
is_execute = serializers.BooleanField()
update_time = serializers.DateTimeField()前端入参校验data
反序列化操作步骤
"""
1.定义序列化器类,使用data关键字参数传递字典参数。
2.必须使用序列化器对象调用.is_valid()方法,对前端输入的参数进行校验。
校验通过返回True,否则返回False。
3.如果调用.is_valid()方法,添加raise_exeception=True,校验不通过会抛出异常,否则不会抛出异常。
4.只有在调用.is_valid()方法之后:
才可以使用序列化器对象调用.errors属性,来获取错误提示信息(字典类型)。
才可以使用序列化器对象调用.validated_data属性,来获取校验通过之后的数据,与使用json.load转化之后的数据有区别
5.调用save方法会自动调用序列化器类的create方法
调用data属性,可以进行序列化输出
(如果有调用save方法并且create方法有返回模型对象的话,那么会把模型对象作为序列化输出的源数据;
如果没有调用save方法,那么会把validated_data作为序列化输出的源数据)
"""def post(self, request):
# 1.获取json参数并转化为python中的数据类型(字典)
try:
python_data = json.loads(request.body)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
# 2. 定义序列化器类
serializer11 = ProjectSerilizer(data=python_data)
# 3. 反序列化输入校验
if not serializer11.is_valid(raise_exception=True):
return JsonResponse(serializer11.errors, status=400)
# 4. 调create,进行数据库操作
project_obj = Projects.objects.create(**serializer11.validated_data)
# 5. 序列化输出校验
serializer = ProjectSerilizer(instance=project_obj)
# 6. 序列化输出结果进行返回
return JsonResponse(serializer.data, status=201)入口方法/先自动调用的方法
def to_internal_value(self, data):
# 1、to_internal_value方法,是所有字段开始进行校验时入口方法(最先调用的方法)
# 2、会依次对序列化器类的各个序列化器字段进行校验:
# 对字段类型进行校验 -> 依次验证validators列表中的校验规则 -> 从右到左依次验证其他规则 -> 调用单字段校验方法
# to_internal_value调用结束 -> 调用多字段联合校验方法validate方法
tmp = super().to_internal_value(data)
# 对各个单字段校验结束之后的数据进行修改
return tmp
自动调用create 
在Django REST framework(DRF)中,
validated_data.pop()方法通常用于
从序列化器(Serializer)的验证后数据(validated_data)中
移除或“弹出”一个字段。这个操作在处理数据前或后非常有用,
比如当你需要在保存数据到数据库之前从数据中移除某些不需要的字段,
或者当你想要单独处理某些字段时。
validated_data 是一个字典,包含了所有经过序列化器验证的字段及其值。
pop() 方法是Python字典的一个内置方法,用于移除字典中的一个元素(通过键来指定),
并返回该元素的值。
如果指定的键不存在于字典中,pop() 方法可以接收一个可选的默认值作为参数,如果键不存在则返回这个默认值;
如果不提供默认值且键不存在,则会引发KeyError。1、在创建序列化器对象时,仅仅只传递data参数,那么必须得先调用is_valid()方法,通过之后
2、如果没有调用save方法,使用创建序列化器对象.data属性,来获取序列化输出的数据
(会把validated_data数据作为输入源,参照序列化器字段的定义来进行输入)
3、如果调用了save方法,使用创建序列化器对象.data属性,来获取序列化输出的数据
(会把create方法返回的模型对象数据作为输入源,参照序列化器字段的定义来进行输出)
return JsonResponse(serializer11.data, status=201)后端出参校验instance
序列化器操作步骤
"""
1.可以使用序列化器进行序列化输出操作。
2.创建序列化器对象。
3.可以将模型对象、查询集对象、普通对象、嵌套普通对象的列表,以instance关键字来传递参数。
4.如果传递的是查询集对象、嵌套普通对象的列表(!多条数据!),必须得设置many=True。
5.如果传递的是模型对象、普通对象,不需要设置many=True。
6.可以使用序列化器对象的.data属性,获取序列化器之后的数据(字典、嵌套字典的列表)。
"""def get(self, request):
# 1.获取所有项目数据(查询集),获取列表数据。
queryset = Projects.objects.all()
serializer = ProjectSerilizer(instance=queryset, many=True).data
return JsonResponse(serializer, safe=False)
def get(self, request, pk):
# 2.获取指定项目数据,单条数据(模型对象)。
try:
project_obj = Projects.objects.get(id=pk)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
serializer = ProjectSerilizer(instance=project_obj).data
return JsonResponse(serializer)输出时的入口方法/先自动调用的方法
def to_representation(self, instance):
# 1、to_representation方法,是所有字段开始进行序列化输出时的入口方法(最先调用的方法)
tmp =super().to_representation(instance)
return tmp
入参出参同时进行data+instance
1.必须得使用序列化器对象调用is_valid方法开始对数据进行校验
2.使用序列化器对象调用errors、validated_data都不会报错
3.在调用save方法时,可以传递任意的关键字参数,并且会自动合并到validated_data字典中
4.使用序列化器对象调用save方法会自动调用序列化器类的update方法,用于对数据进行更新操作
序列化器类中的update方法,instance参数为待更新的模型对象,validated_data参数为校验通过之后的数据(一般字典类型)
update方法一般需要将更新成功之后模型对象返回
6.使用序列化器对象调用data属性,可以进行序列化输出
(如果有调用save方法并且update方法有返回模型对象的话,那么会把模型对象作为序列化输出的源数据;
如果没有调用save方法,那么会把validated_data作为序列化输出的源数据)
def put(self, request, pk):
# 判断待更新的数据是否存在
try:
project_obj = Projects.objects.get(id=pk)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
# 将入参的数据进行格式转换
try:
python_data = json.loads(request.body)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
# serializer11 = ProjectSerilizer(data=python_data)
serializer = ProjectSerilizer(instance=project_obj, data=python_data)
if not serializer.is_valid():
return JsonResponse(serializer.errors, status=400)
# 4、更新数据
# project_obj.name = serializer11.validated_data.get('name')
# project_obj.leader = serializer11.validated_data.get('leader')
# project_obj.is_execute = serializer11.validated_data.get('is_execute')
# project_obj.desc = serializer11.validated_data.get('desc')
# project_obj.save()
serializer.save()
# 5、将读取的项目数据转化为字典
# serializer = ProjectSerilizer(instance=project_obj)
return JsonResponse(serializer.data, status=201)自定义报错

校验单个字段
# 1、可以在序列化器类中对单个字段进行校验
# 2、单字段的校验方法名称,必须把validate_作为前缀,加上待校验的字段名,如:validate_待校验的字段名
# 3、如果校验不通过,必须得返回serializers.ValidationError('具体报错信息')异常
# 4、如果校验通过,往往需要将校验之后的值,返回
# 5、如果该字段在定义时添加的校验规则不通过,那么是不会调用单字段的校验方法
def validate_name(self, attr: str):
if not attr.endswith('项目'):
raise serializers.ValidationError('项目名称必须得以“项目”结尾')
return attr校验多个字段联合校验validate
# 1、可以在序列化器类中对多个字段进行联合校验
# 2、使用固定的validate方法,会接收上面校验通过之后的字典数据
# 3、当所有字段定义时添加的校验规则都通过,且每个字段的单字段校验方法通过的情况下,才会调用validate
def validate(self, attrs: dict):
if len(attrs.get('leader')) <= 4 or not attrs.get('is_execute'):
raise serializers.ValidationError('项目负责人名称长度不能少于4位或者is_execute参数为False')
return attrs模型类中没有的字段做输入输出
1、如果定义了一个模型类中没有的字段,并且该字段需要输出(序列化输出)
2、需要在create方法、update方法中的模型对象上,添加动态的属性即可
token = serializers.CharField(read_only=True)
3、如果定义了一个模型类中没有的字段,并且该字段需要输入(反序列化输入)
4、需要在create方法、update方法调用之前,将该字段pop调用
sms_code = serializers.CharField(write_only=True)Project项目的serializer
from rest_framework import serializers
from rest_framework.validators import UniqueValidator
from interfaces.models import Interfaces
from .models import Projects
# 1、自定义的序列化器类实际上也是Field的子类
# 2、所以自定义的序列化器类可以作为另一个序列化器中的字段来使用
class InterfaceSerilizer(serializers.Serializer):
id = serializers.IntegerField()
name = serializers.CharField()
tester = serializers.CharField()
# 1、可以在类外自定义校验函数
# 2、第一个参数为待校验的值
# 3、如果校验不通过,必须得抛出serializers.ValidationError('报错信息')异常,同时可以指定具体的报错信息
# 4、需要将校验函数名放置到validators列表中
def is_contains_keyword(value):
if '项目' not in value:
raise serializers.ValidationError('项目名称中必须得包含“项目”关键字')
class ProjectSerilizer(serializers.Serializer):
"""
二、定义序列化器类
1.必须得继承Serializer类或者Serializer子类
2.定义的序列化器类中,字段名要与模型类中的字段名保持一致
3.定义的序列化器类的字段(类属性)为Field子类
4.默认定义哪些字段,那么哪些字段就会返回前端,同时也必须的输入(前端需要传递)
5.常用的序列化器字段类型
IntegerField -> int
CharField -> str
BooleanField -> bool
DateTimeField -> datetime
6.可以在序列化器字段中指定不同的选项
label和help_text,与模型类中的verbose_name和help_text参数一样
IntegerField,可以使用max_value指定最大值,min_value指定最小值
CharField,可以使用max_length指定最大长度,min_length指定最小长度
7.定义的序列化器字段中,required默认为True,说明默认定义的字段必须得输入和输出
8.如果在序列化器字段中,设置required=False,那么前端用户可以不传递该字段(校验时会忽略改该字段,所以不会报错)
9.如果未定义模型类中的某个字段,那么该字段不会输入,也不会输出
10.前端必须的输入(反序列化输入)name(必须得校验),但是不会需要输出(序列化器输出)?
如果某个参数指定了write_only=True,那么该字段仅仅只输入(反序列化输入,做数据校验),不会输出(序列化器输出),
默认write_only为False
11.前端可以不用传递,但是后端需要输出?
如果某个参数指定了read_only=True,那么该字段仅仅只输出(序列化器输出),不会输入(反序列化输入,做数据校验),
默认read_only为False
12.在序列化器类中定义的字段,默认allow_null=False,该字段不允许传递null空值,
如果指定allow_null=True,那么该字段允许传递null
13.在序列化器类中定义CharField字段,默认allow_blank=False,该字段不允许传递空字符串,
如果指定allow_blank=True,那么该字段允许传递空字符串
14.在序列化器类中定义的字段,可以使用default参数来指定默认值,如果指定了default参数,那么前端用户可以不用传递,
会将default指定的值作为入参
"""
# id = serializers.IntegerField(label='项目id', help_text='项目id', max_value=1000, min_value=1)
# name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5, write_only=True)
# name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5, read_only=True)
# 1、可以在序列化器字段上使用validators指定自定义的校验规则
# 2、validators必须得为序列类型(列表),在列表中可以添加多个校验规则
# 3、DRF框架自带UniqueValidator校验器,必须得使用queryset指定查询集对象,用于对该字段进行校验
# 4、UniqueValidator校验器,可以使用message指定自定义报错信息
# 5、校验规则的执行顺序?
# 对字段类型进行校验 -> 依次验证validators列表中的校验规则 -> 从右到左依次验证其他规则 -> 调用单字段校验方法
# -> 调用多字段联合校验方法validate方法
name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5,
error_messages={
'min_length': '项目名称不能少于5位',
'max_length': '项目名称不能超过20位'
}, validators=[UniqueValidator(queryset=Projects.objects.all(), message='项目名称不能重复'),
is_contains_keyword])
# leader = serializers.CharField(label='项目负责人', help_text='项目负责人', allow_null=True)
# leader = serializers.CharField(label='项目负责人', help_text='项目负责人', allow_blank=True)
leader = serializers.CharField(label='项目负责人', help_text='项目负责人', default='阿名')
is_execute = serializers.BooleanField(write_only=True)
# 1、如果定义了一个模型类中没有的字段,并且该字段需要输出(序列化输出)
# 2、需要在create方法、update方法中的模型对象上,添加动态的属性即可
# token = serializers.CharField(read_only=True)
# 3、如果定义了一个模型类中没有的字段,并且该字段需要输入(反序列化输入)
# 4、需要在create方法、update方法调用之前,将该字段pop调用
# sms_code = serializers.CharField(write_only=True)
# a.DateTimeField可以使用format参数指定格式化字符串
# b.可以任意序列化器字段上使用error_messages来自定义错误提示信息
# c.使用校验选项名(校验方法名)作为key,把具体的错误提示信息作为value
# update_time = serializers.DateTimeField(label='更新时间', help_text='更新时间', format='%Y年%m月%d日 %H:%M:%S',
# error_messages={'required': '该字段为必传参数'})
# 一、关联字段
# 1、可以定义PrimaryKeyRelatedField来获取关联表的外键值
# 2、如果通过父获取从表数据,默认需要使用从表模型类名小写_set作为序列化器类中的关联字段名称
# 3、如果在定义模型类的外键字段时,指定了realated_name参数,那么会把realated_name参数名作为序列化器类中的关联字段名称
# 4、PrimaryKeyRelatedField字段,要么指定read_only=True,要么指定queryset参数,否则会报错
# 5、如果指定了read_only=True,那么该字段仅序列化输出
# 6、如果指定了queryset参数(关联表的查询集对象),用于对参数进行校验
# 7、如果关联字段有多个值,那么必须添加many=True,一般父表获取从表数据时,关联字段需要指定
# interfaces_set = serializers.PrimaryKeyRelatedField(label='项目所属接口id', help_text='项目所属接口id',
# many=True, queryset=Interfaces.objects.all(), write_only=True)
# 1、使用StringRelatedField字段,将关联字段模型类中的__str__方法的返回值作为该字段的值
# 2、StringRelatedField字段默认添加了read_only=True,该字段仅序列化输出
# interfaces_set = serializers.StringRelatedField(many=True)
# 1、使用SlugRelatedField字段,将关联模型类中的某个字段,作为该字段的值
# 2、如果指定了read_only=True,那么该字段仅序列化输出
# 3、如果该字段需要进行反序列化输入,那么必须得指定queryset参数,同时关联字段必须有唯一约束
# interfaces_set = serializers.SlugRelatedField(slug_field='name', many=True, queryset=Interfaces.objects.all())
# interfaces_set = InterfaceSerilizer(label='所属接口信息', help_text='所属接口信息', read_only=True,
# many=True)
# 1、可以在序列化器类中对单个字段进行校验
# 2、单字段的校验方法名称,必须把validate_作为前缀,加上待校验的字段名,如:validate_待校验的字段名
# 3、如果校验不通过,必须得返回serializers.ValidationError('具体报错信息')异常
# 4、如果校验通过,往往需要将校验之后的值,返回
# 5、如果该字段在定义时添加的校验规则不通过,那么是不会调用单字段的校验方法
def validate_name(self, attr: str):
if not attr.endswith('项目'):
raise serializers.ValidationError('项目名称必须得以“项目”结尾')
return attr
# 1、可以在序列化器类中对多个字段进行联合校验
# 2、使用固定的validate方法,会接收上面校验通过之后的字典数据
# 3、当所有字段定义时添加的校验规则都通过,且每个字段的单字段校验方法通过的情况下,才会调用validate
def validate(self, attrs: dict):
if len(attrs.get('leader')) <= 4 or not attrs.get('is_execute'):
raise serializers.ValidationError('项目负责人名称长度不能少于4位或者is_execute参数为False')
return attrs
# def to_internal_value(self, data):
# # 1、to_internal_value方法,是所有字段开始进行校验时入口方法(最先调用的方法)
# # 2、会依次对序列化器类的各个序列化器字段进行校验:
# # 对字段类型进行校验 -> 依次验证validators列表中的校验规则 -> 从右到左依次验证其他规则 -> 调用单字段校验方法
# # to_internal_value调用结束 -> 调用多字段联合校验方法validate方法
# tmp = super().to_internal_value(data)
# # 对各个单字段校验结束之后的数据进行修改
# return tmp
# def to_representation(self, instance):
# # 1、to_representation方法,是所有字段开始进行序列化输出时的入口方法(最先调用的方法)
# tmp =super().to_representation(instance)
# return tmp
def create(self, validated_data: dict):
myname = validated_data.pop('myname')
myage = validated_data.pop('myage')
validated_data.pop('sms_code')
project_obj = Projects.objects.create(**validated_data)
project_obj.token = 'xxxxxxxxxxxxx'
return project_obj
def update(self, instance, validated_data: dict):
# for key, value in validated_data.items():
# setattr(instance, key, value)
instance.name = validated_data.get('name') or instance.name
instance.leader = validated_data.get('leader') or instance.leader
instance.is_execute = validated_data.get('is_execute') or instance.is_execute
instance.desc = validated_data.get('desc') or instance.desc
instance.save()
return instance
class ProjectModelSerializer(serializers.ModelSerializer):
"""
定义模型序列化器类
1、继承serializers.ModelSerializer类或者其子类
2、需要在Meta内部类中指定model、fields、exclude类属性参数
3、model指定模型类(需要生成序列化器的模型类)
4、fields指定模型类中哪些字段需要自动生成序列化器字段
5、会给id主键、指定了auto_now_add或者auto_now参数的DateTimeField字段,添加read_only=True,仅仅只进行序列化输出
6、有设置unique=True的模型字段,会自动在validators列表中添加唯一约束校验<UniqueValidator
7、有设置default=True的模型字段,会自动添加required=False
8、有设置null=True的模型字段,会自动添加allow_null=True
9、有设置blank=True的模型字段,会自动添加allow_blank=True
"""
# 修改自动生成的序列化器字段
# 方式一:
# a.可以重新定义模型类中同名的字段
# b.自定义字段的优先级会更高(会覆盖自动生成的序列化器字段)
# name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5,
# error_messages={
# 'min_length': '项目名称不能少于5位',
# 'max_length': '项目名称不能超过20位'
# }, validators=[UniqueValidator(queryset=Projects.objects.all(), message='项目名称不能重复'),
# is_contains_keyword])
# interfaces_set = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
# token = serializers.CharField(read_only=True)
class Meta:
model = Projects
# fields指定模型类中哪些字段需要自动生成序列化器字段
# a.如果指定为"__all__",那么模型类中所有的字段都需要自动转化为序列化器字段
# b.可以传递需要转化为序列化器字段的模型字段名元组
# c.fields元祖中必须指定进行序列化或者反序列化操作的所有字段名称,指定了'__all__'和exclude除外
fields = "__all__"
# fields = ('id', 'name', 'leader', 'interfaces_set', 'token')
# c.exclude指定模型类中哪些字段不需要转化为序列化器字段,其他的字段都需要转化
# exclude = ('create_time', 'update_time')
# 方式二:
# a.如果自动生成的序列化器字段,只有少量不满足要求,可以在Meta中extra_kwargs字典进行微调
# b.将需要调整的字段作为key,把具体需要修改的内容字典作为value
extra_kwargs = {
'leader': {
'label': '负责人',
'max_length': 15,
'min_length': 2,
# 'read_only': True
# 'validators': []
},
'name': {
'min_length': 5
}
}
# 可以将需要批量需要设置read_only=True参数的字段名添加到Meta中read_only_fields元组
# read_only_fields = ('leader', 'is_execute', 'id')
# def create(self, validated_data):
# """
# a.继承ModelSerializer之后,ModelSerializer中实现了create和update方法
# b.一般无需再次定义create和update方法
# c.如果父类提供的create和update方法不满足需要时,可以重写create和update方法,最后再调用父类的create和update方法
# :param validated_data:
# :return:
# """
# validated_data.pop('myname')
# validated_data.pop('myage')
# instance = super().create(validated_data)
# instance.token = "xxxxxxx"
# return instance
class ProjectModelSerializer1(serializers.ModelSerializer):
"""
定义模型序列化器类
1、继承serializers.ModelSerializer类或者其子类
2、需要在Meta内部类中指定model、fields、exclude类属性参数
3、model指定模型类(需要生成序列化器的模型类)
4、fields指定模型类中哪些字段需要自动生成序列化器字段
5、会给id主键、指定了auto_now_add或者auto_now参数的DateTimeField字段,添加read_only=True,仅仅只进行序列化输出
6、有设置unique=True的模型字段,会自动在validators列表中添加唯一约束校验<UniqueValidator
7、有设置default=True的模型字段,会自动添加required=False
8、有设置null=True的模型字段,会自动添加allow_null=True
9、有设置blank=True的模型字段,会自动添加allow_blank=True
"""
class Meta:
model = Projects
exclude = ('id', 'create_time')
class ProjectsNamesModelSerailizer(serializers.ModelSerializer):
class Meta:
model = Projects
fields = ('id', 'name')
模型序列化器类ModelSerializer
from rest_framework import serializers
from rest_framework.validators import UniqueValidator
from interfaces.models import Interfaces
from .models import Projects
class ProjectModelSerializer(serializers.ModelSerializer):
"""
定义模型序列化器类
1、继承serializers.ModelSerializer类或者其子类
2、需要在Meta内部类中指定model、fields、exclude类属性参数
3、model指定模型类(需要生成序列化器的模型类)
4、fields指定模型类中哪些字段需要自动生成序列化器字段
5、会给id主键、指定了auto_now_add或者auto_now参数的DateTimeField字段,添加read_only=True,仅仅只进行序列化输出
6、有设置unique=True的模型字段,会自动在validators列表中添加唯一约束校验<UniqueValidator
7、有设置default=True的模型字段,会自动添加required=False
8、有设置null=True的模型字段,会自动添加allow_null=True
9、有设置blank=True的模型字段,会自动添加allow_blank=True
"""
自动生成字段
from rest_framework import serializers
from rest_framework.validators import UniqueValidator
from interfaces.models import Interfaces
from .models import Projects
class ProjectModelSerializer(serializers.ModelSerializer):
class Meta:
""" 指定哪个模型类转化为模型序列化器类 """
model = Projects
"""
fields指定模型类中哪些字段需要自动生成序列化器字段
a.如果指定为"__all__",那么模型类中所有的字段都需要自动转化为序列化器字段
b.可以传递需要转化为序列化器字段的模型字段名元组
c.fields元祖中必须指定进行序列化或者反序列化操作的所有字段名称,指定了'__all__'和exclude除外
"""
fields = "__all__"
fields = ('id', 'name', 'leader', 'interfaces_set', 'token')
""" c.exclude指定模型类中哪些字段不需要转化为序列化器字段,其他的字段都需要转化 """
exclude = ('create_time', 'update_time')
控制台查看哪些自动生成字段
python manage.py shell
优化自动生成的字段
重新定义一个字段
class ProjectModelSerializer(serializers.ModelSerializer):
"""
方式一:
a.可以重新定义模型类中同名的字段
b.自定义字段的优先级会更高(会覆盖自动生成的序列化器字段)
name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5,
error_messages={
'min_length': '项目名称不能少于5位',
'max_length': '项目名称不能超过20位'
}, validators=[UniqueValidator(queryset=Projects.objects.all(), message='项目名称不能重复'),
is_contains_keyword])
interfaces_set = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
token = serializers.CharField(read_only=True)
"""
class Meta:
model = Projects
"""可以将需要批量需要设置read_only=True参数的字段名添加到Meta中read_only_fields元组"""
read_only_fields = ('leader', 'is_execute', 'id')
在自动生成的字段上修改
class ProjectModelSerializer(serializers.ModelSerializer):
class Meta:
model = Projects
"""
a.如果自动生成的序列化器字段,只有少量不满足要求,可以在Meta中extra_kwargs字典进行微调
b.将需要调整的字段作为key,把具体需要修改的内容字典作为value
"""
extra_kwargs = {
'leader': {
'label': '负责人',
'max_length': 15,
'min_length': 2,
# 'read_only': True
# 'validators': []
},
'name': {
'min_length': 5
}
}
"""可以将需要批量需要设置read_only=True参数的字段名添加到Meta中read_only_fields元组"""
read_only_fields = ('leader', 'is_execute', 'id')
视图模块
类视图的设计原则?
a.类视图尽量要简单
b.根据需求选择相应的父类视图
c.如果DRF中的类视图有提供相应的逻辑,那么就直接使用父类提供的
d.如果DRF中的类视图,绝大多数逻辑都能满足需求,可以重写父类实现
e.如果DRF中的类视图完全不满足要求,那么就直接自定义即可APIView
提供的功能
- 解析器来进行接口请求入参解析
- 渲染器进行接口请求出参解析
- 认证
- 授权
- 限流
- return将使用Response
解析器
DRF中的解析器(类)
1、可以根据请求头中的Content-Type来自动解析参数,使用统一的data属性来获取即可
2、默认JSONParser、FormParser、MultiPartParser三个解析器类
3、可以在全局配置文件(settings.py)中修改DRF全局参数,REST_FRAMEWORK作为名称
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser',
'rest_framework.parsers.FormParser',
'rest_framework.parsers.MultiPartParser'
],渲染器
DRF中的渲染器(类)
1、可以根据请求头中的Accept参数来自动渲染前端需要的数据格式,也就是出参,返回的数据
2、默认的渲染器为JSONRenderer、BrowsableAPIRenderer
3、如果前端请求头未指定Accept参数或者指定为application/json,那么会自动返回json格式的数据
4、如果前端请求头指定Accept参数为text/html,那么默认会返回可浏览的api页面(api进行管理)
5、可以在DEFAULT_RENDERER_CLASSES中指定需要使用的渲染器
'DEFAULT_RENDERER_CLASSES': [
'rest_framework.renderers.JSONRenderer',
'rest_framework.renderers.BrowsableAPIRenderer',
],import json
from django.http import HttpResponse, JsonResponse
from django.views import View
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework import status
from .models import Projects
from .serializers import ProjectSerilizer, ProjectModelSerializer
# class ProjectsView(View):
class ProjectsView(APIView):
"""
继承APIView父类(Django中View的子类)
a.具备View的所有特性
b.提供了认证、授权、限流功能
"""
def get(self, request):
queryset = Projects.objects.all()
serializer = ProjectSerilizer(instance=queryset, many=True)
# return JsonResponse(serializer.data, safe=False)
# 在DRF中Response为HTTPResponse的子类
# a.data参数为序列化之后的数据(一般为字典或嵌套字典的列表)
# b.会自动根据渲染器来将数据转化为请求头中Accept需要的格式进行返回
# c.status指定响应状态码
# d.content_type指定响应头中的Content-Type,一般无需指定,会根据渲染器来自动设置
return Response(serializer.data, status=status.HTTP_200_OK, content_type='ap')
def post(self, request):
# a.一旦继承APIView之后,request是DRF中Request对象
# b.Request是在HttpRequest基础上做了拓展
# c.兼容HttpRequest的所有功能
# d.前端传递的查询字符串参数:GET、query_params
# e.前端传递application/json、application/x-www-form-urlencoded、multipart/form-data参数
# 可以根据请求头中Content-Type,使用统一的data属性获取
# try:
# python_data = json.loads(request.body)
# except Exception as e:
# return JsonResponse({'msg': '参数有误'}, status=400)
# python_data = request.data
serializer = ProjectModelSerializer(data=request.data)
# if not serializer.is_valid():
# # return JsonResponse(serializer11.errors, status=400)
# return Response(serializer.errors, status=400)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
class ProjectsDetailView(APIView):
def get(self, request, pk):
try:
project_obj = Projects.objects.get(id=pk)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
serializer = ProjectSerilizer(instance=project_obj)
return Response(serializer.data, status=status.HTTP_200_OK)
def get_object(self, pk):
try:
project_obj = Projects.objects.get(id=pk)
return project_obj
except Exception as e:
return Response({'msg': '参数有误'}, status=400)
def put(self, request, pk):
project_obj = self.get_object(pk)
serializer = ProjectSerilizer(instance=project_obj, data=request.data)
# if not serializer.is_valid():
# return JsonResponse(serializer.errors, status=400)
# 在序列化器对象调用is_valid(raise_exception=True),校验失败时,会抛出异常,DRF框架会自动处理异常
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
def delete(self, request, pk):
project_obj = self.get_object(pk)
# 3、执行删除
project_obj.delete()
# return JsonResponse({'msg': '删除成功'}, status=204)
return Response(status=status.HTTP_204_NO_CONTENT)
解析器和渲染器应用
# class ProjectsView(View):
class ProjectsView(APIView):
"""
继承APIView父类(Django中View的子类)
a.具备View的所有特性
b.提供了认证、授权、限流功能
"""
def get(self, request):
queryset = Projects.objects.all()
serializer = ProjectSerilizer(instance=queryset, many=True)
# return JsonResponse(serializer.data, safe=False)
# 在DRF中Response为HTTPResponse的子类
# a.data参数为序列化之后的数据(一般为字典或嵌套字典的列表)
# b.会自动根据渲染器来将数据转化为请求头中Accept需要的格式进行返回
# c.status指定响应状态码
# d.content_type指定响应头中的Content-Type,一般无需指定,会根据渲染器来自动设置
return Response(serializer.data, status=status.HTTP_200_OK, content_type='ap')
def post(self, request):
# a.一旦继承APIView之后,request是DRF中Request对象
# b.Request是在HttpRequest基础上做了拓展
# c.兼容HttpRequest的所有功能
# d.前端传递的查询字符串参数:GET、query_params
# e.前端传递application/json、application/x-www-form-urlencoded、multipart/form-data参数
# 可以根据请求头中Content-Type,使用统一的data属性获取
# try:
# python_data = json.loads(request.body)
# except Exception as e:
# return JsonResponse({'msg': '参数有误'}, status=400)
# python_data = request.data
serializer = ProjectModelSerializer(data=request.data)
# if not serializer.is_valid():
# # return JsonResponse(serializer11.errors, status=400)
# return Response(serializer.errors, status=400)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
return将使用Response
class ProjectsView(APIView):
def get(self, request):
queryset = Projects.objects.all()
serializer = ProjectSerilizer(instance=queryset, many=True)
# return JsonResponse(serializer.data, safe=False)
# 在DRF中Response为HTTPResponse的子类
# a.data参数为序列化之后的数据(一般为字典或嵌套字典的列表)
# b.会自动根据渲染器来将数据转化为请求头中Accept需要的格式进行返回
# c.status指定响应状态码
# d.content_type指定响应头中的Content-Type,一般无需指定,会根据渲染器来自动设置
return Response(serializer.data, status=status.HTTP_200_OK, content_type='ap')request.data自动将请求体的表单和json转字典
serializer.is_valid(raise_exception=True) 校验不通过抛出异常
class ProjectsView(APIView):
def post(self, request):
# a.一旦继承APIView之后,request是DRF中Request对象
# b.Request是在HttpRequest基础上做了拓展
# c.兼容HttpRequest的所有功能
# d.前端传递的查询字符串参数:GET、query_params
# e.前端传递application/json、application/x-www-form-urlencoded、multipart/form-data参数
# 可以根据请求头中Content-Type,使用统一的data属性获取
# try:
# python_data = json.loads(request.body)
# except Exception as e:
# return JsonResponse({'msg': '参数有误'}, status=400)
# python_data = request.data
serializer = ProjectModelSerializer(data=request.data)
# if not serializer.is_valid():
# # return JsonResponse(serializer11.errors, status=400)
# return Response(serializer.errors, status=400)
# 优化成一行
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)GenericAPIView
提供的功能
- 提供分页
- 提供搜索过滤
一些改动
class ProjectsView(GenericAPIView):
"""改动1"""
# 一旦继承GenericAPIView之后,往往需要指定queryset、serializer_class类属性
# queryset指定当前类视图的实例方法需要使用的查询集对象
queryset = Projects.objects.all()
# serializer_class指定当前类视图的实例方法需要使用的序列化器类
serializer_class = ProjectSerilizer
def get(self, request: Request):
# name_param = request.query_params.get('name')
# if name_param:
# queryset = Projects.objects.filter(name__exact=name_param)
# else:
# queryset = Projects.objects.all()
# queryset = Projects.objects.all()
"""改动2
1、在实例方法中,往往使用get_queryset()方法获取查询集对象
2、一般不会直接调用queryset类属性,原因:为了提供让用户重写get_queryset()
3、如果未重写get_queryset()方法,那么必须得指定queryset类属性"""
# queryset = self.queryset
# queryset = self.get_queryset()
"""改动3
1、在实例方法中,往往使用get_serializer()方法获取序列化器类
2、一般不会直接调用serializer_class类属性,原因:为了让用户重写get_serializer_class()
3、如果未重写get_serializer_class()方法,那么必须得指定serializer_class类属性"""
# serializer = self.serializer_class(instance=queryset, many=True)
serializer = self.get_serializer(instance=queryset, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
过滤/搜索
class ProjectsView(GenericAPIView):
"""1、filter_backends在继承了GenericAPIView的类视图中指定使用的过滤引擎类(搜索、排序)
优先级高于全局
2、在继承了GenericAPIView的类视图中,search_fields类属性指定模型类中需要进行搜索过滤的字段名
3、使用icontains查询类型作为过滤类型
4、可以在字段名称前添加相应符号,指定查询类型
'^': 'istartswith',
'=': 'iexact',
'$': 'iregex'
"""
filter_backends = [filters.SearchFilter, filters.OrderingFilter]
search_fields = ['^name', '=leader', 'id']
"""ordering_fields类属性指定模型类中允许前端进行排序的字段名称
前端默认可以使用ordering作为排序功能查询字符串参数名称,默认改字段的升序
如果在字段名称前添加“-”,代表改字段降序
如果指定多个排序字段,使用英文逗号进行分割"""
ordering_fields = ['id', 'name', 'leader']
def get(self, request: Request):
# filter_queryset对查询对象进行过滤操作
queryset = self.filter_queryset(self.get_queryset())
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(instance=page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(instance=queryset, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
排序
from django.http import JsonResponse
from rest_framework.request import Request
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework.generics import GenericAPIView
from rest_framework import status
from rest_framework import filters
from .models import Projects
from .serializers import ProjectSerilizer, ProjectModelSerializer
class ProjectsView(GenericAPIView):
"""1、filter_backends在继承了GenericAPIView的类视图中指定使用的过滤引擎类(搜索、排序)
优先级高于全局"""
filter_backends = [filters.SearchFilter, filters.OrderingFilter]
"""ordering_fields类属性指定模型类中允许前端进行排序的字段名称
前端默认可以使用ordering作为排序功能查询字符串参数名称,默认改字段的升序
如果在字段名称前添加“-”,代表改字段降序
如果指定多个排序字段,使用英文逗号进行分割"""
ordering_fields = ['id', 'name', 'leader']
def get(self, request: Request):
# filter_queryset对查询对象进行过滤操作
queryset = self.filter_queryset(self.get_queryset())
# serializer = ProjectSerilizer(instance=queryset, many=True)
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(instance=page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(instance=queryset, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)分页
重写分页方法

from rest_framework.pagination import PageNumberPagination as _PageNumberPagination
class PageNumberPagination(_PageNumberPagination):
# 指定默认每一页显示3条数据
page_size = 3
# 前端用于指定页码的查询字符串参数名称
page_query_param = 'pp'
# 前端用于指定页码的查询字符串参数描述
page_query_description = '获取的页码'
# 前端用于指定每一页显示的数据条数,查询字符串参数名称
page_size_query_param = 'ss'
page_size_query_description = '每一页数据条数'
max_page_size = 50
invalid_page_message = '无效页码'
# 重写返回数据,当前页和最大页
def get_paginated_response(self, data):
response = super().get_paginated_response(data)
response.data['current_num'] = self.page.number
response.data['max_num'] = self.page.paginator.num_pages
return response
修改setting

应用
from django.http import JsonResponse
from rest_framework.request import Request
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework.generics import GenericAPIView
from rest_framework import status
from rest_framework import filters
from rest_framework import mixins
from rest_framework import generics
from rest_framework import viewsets
from .models import Projects
from .serializers import ProjectSerilizer, ProjectModelSerializer
from utils.pagination import PageNumberPagination
class ProjectsView(GenericAPIView):
queryset = Projects.objects.all()
serializer_class = ProjectModelSerializer
filter_backends = [filters.SearchFilter, filters.OrderingFilter]
search_fields = ['=name', '=leader', '=id']
ordering_fields = ['id', 'name', 'leader']
# 可以在类视图中指定分页引擎类,优先级高于全局
pagination_class = PageNumberPagination
def get(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
# 3、调用paginate_queryset方法对查询集对象进行分页
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(instance=page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(instance=queryset, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
# a.python中支持多重继承,一个类可以同时继承多个父类
# b.类中的方法和属性是按照__mro__所指定的继承顺序进行搜索
print(ProjectsView.__mro__)
return self.list(request, *args, **kwargs)
Mixin 拓展类
提供的功能
提供了各种封装好的请求方法,但目前无法自动解析匹配对应方法。
a.直接继承Mixin拓展类,拓展类只提供了action方法
b.action方法有哪些呢?
list --> 获取列表数据
retrieve --> 获取详情数据
create --> 创建数据
update --> 更新数据(完整)
partial_update --> 更新数据(部分)
destroy --> 删除数据
c.类视图往往只能识别如下方法?
get --> list
get --> retrieve
post --> create
put --> update
patch --> partial_update
delete --> destroy
d.为了进一步优化代码,需要使用具体的通用视图XXXAPIView ModelViewSet(终极BOSS)
ModelViewSet(终极BOSS)
提供的功能
能够自动根据路由入参和请求方式匹配上对应的action方法,注释掉了,代表无需再写,只是为了看的明白。

如何选择视图
1.ModelViewSet是一个最完整的视图集类
a.提供了获取列表数据接口、获取详情数据接口、创建数据接口、更新数据接口、删除数据的接口
b.如果需要多某个模型进行增删改查操作,才会选择ModelViewSet
2.ReadOnlyModelViewSet
a.仅仅只对某个模型进行数据读取操作(取列表数据接口、获取详情数据接口),一般会选择不同的action使用不同的序列化器类····
from rest_framework.response import Response
from rest_framework import filters,viewsets
from rest_framework.decorators import action
from .models import Projects
from .serializers import ProjectSerilizer, ProjectModelSerializer, ProjectModelSerializer1, ProjectsNamesModelSerailizer
from utils.pagination import PageNumberPagination
class ProjectViewSet(viewsets.ModelViewSet):
queryset = Projects.objects.all()
# 该视图集默认用的序列化器类
serializer_class = ProjectModelSerializer
filter_backends = [filters.SearchFilter, filters.OrderingFilter]
search_fields = ['=name', '=leader', '=id']
ordering_fields = ['id', 'name', 'leader']
pagination_class = PageNumberPagination
@action(methods=['GET'], detail=False)
def names(self, request, *args, **kwargs):
# 获取项目的查询集对象
queryset = self.get_queryset()
queryset = self.filter_queryset(queryset)
names_list = []
for project in queryset:
names_list.append({
'id': project.id,
'name': project.name
})
# 调用定义的序列化器类
serializer = self.get_serializer(queryset, many=True)
# return Response(names_list, status=200)
return Response(serializer.data, status=200)
def get_serializer_class(self):
"""
a.可以重写父类的get_serializer_class方法,用于为不同的action提供不一样的序列化器类
b.在视图集对象中可以使用action属性获取当前访问的action方法名称
:return:
"""
if self.action == 'names':
return ProjectsNamesModelSerailizer
else:
# return self.serializer_class
return super().get_serializer_class()

不要过滤
# 干掉过滤
def filter_queryset(self, queryset):
if self.action == "names":
return self.queryset
else:
return super().filter_queryset(queryset)
不要分页
# 干掉分页
def paginate_queryset(self, queryset):
if self.action == "names":
return
else:
return super().paginate_queryset(queryset)
自动生成路由条目
SimpleRouter路由对象
from django.urls import path, include
from rest_framework import routers
from . import views
"""
1、可以使用路由器对象,为视图集类自动生成路由条目
2、路由器对象默认只为通用action(create、list、retrieve、update、destroy)生成路由条目,自定义的action不会生成路由条目
"""
"""
创建SimpleRouter路由对象
DefaultRouter与SimpleRouter功能类似,仅有的区别为:DefaultRouter会自动生成一个根路由(显示获取数据的入口)
router = routers.DefaultRouter()
"""
router = routers.SimpleRouter()
"""
4、使用路由器对象调用register方法进行注册
5、prefix指定路由前缀:r'projects'
6、viewset指定视图集类,不可调用as_view:views.ProjectViewSet
"""
# 方法一
router.register(r'projects', views.ProjectViewSet)
# 方式二:
# router.urls为列表
urlpatterns = []
urlpatterns += router.urls视图类-自定义action改动
"""
1、如果需要使用路由器机制自动生成路由条目,那么就必须得使用action装饰器
2、methods指定需要使用的请求方法,可以不指定,默认为GET
3、detail指定是否为详情接口,是否需要传递当前模型的pk值
需要detail=True,不需要detail=False
4、url_path指定url路径,默认为action方法名称:172.168.1.1:8080/projects/names/
5、url_name指定url路由条目名称后缀,默认为action方法名称"""
# @action(methods=['GET'], detail=False, url_path='xxx', url_name='yyyy')
@action(methods=['GET'], detail=False)
def names(self, request, *args, **kwargs):
# 获取项目的查询集对象
queryset = self.get_queryset()
queryset = self.filter_queryset(queryset)
names_list = []
for project in queryset:
names_list.append({
'id': project.id,
'name': project.name
})
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data, status=200)
自动生成接口文档
安装
coreapi(必选)
Pygments(可选)
Markdown(可选)
drf-yasg(不错)配置
全局settings
REST_FRAMEWORK = {
# 指定用于支持coreapi的Schema
'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema',
}
INSTALLED_APPS = [
'drf_yasg',
]主路由
schema_view = get_schema_view(
openapi.Info(
title="Lemon API接口文档平台", # 必传
default_version='v1', # 必传
description="这是一个美轮美奂的接口文档",
terms_of_service="http://api.keyou.site",
contact=openapi.Contact(email="keyou100@qq.com"),
license=openapi.License(name="BSD License"),
),
public=True,
)
urlpatterns = [
path('', include('projects.urls')),
path('docs/', include_docs_urls(title='测试平台接口文档', description='xxx接口文档')),
re_path(r'^swagger(?P<format>\.json|\.yaml)$', schema_view.without_ui(cache_timeout=0), name='schema-json'),
path('swagger/', schema_view.with_ui('swagger', cache_timeout=0), name='schema-swagger-ui'),
path('redoc/', schema_view.with_ui('redoc', cache_timeout=0), name='schema-redoc'),
]访问
访问本地地址例如:172.0.0.1:8080/swagger
项目实战
架构设计

相关配置
子应用寻址
将子应用放置到一个文件夹内,统一管理,所以要修改sys配合寻址。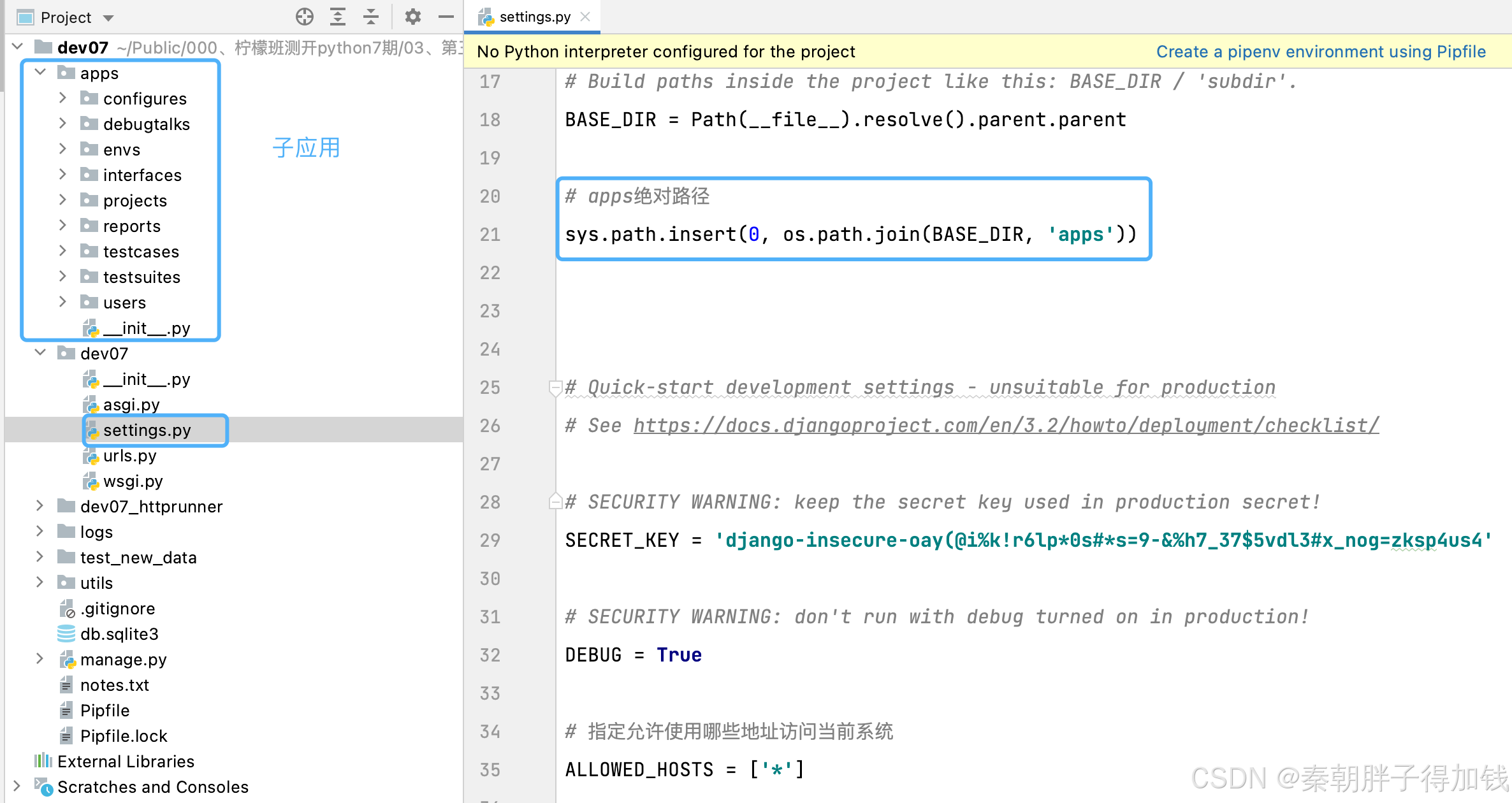
配置访问地址



日志
# setting里追加
LOGGING = {
# 指定日志版本
'version': 1,
# 指定是否禁用其他日志,False为不禁用
'disable_existing_loggers': False,
# 定义日志输出格式
'formatters': {
# 简单格式
'simple': {
'format': '%(asctime)s - [%(levelname)s] - [msg]%(message)s'
},
# 复杂格式
'verbose': {
'format': '%(asctime)s - [%(levelname)s] - %(name)s - [msg]%(message)s - [%(filename)s:%(lineno)d ]'
},
},
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
# 指定日志输出渠道(日志输出的地方)
'handlers': {
# 指定在console控制台(终端)的日志配置行李箱
'console': {
# 指定日志记录等级
'level': 'DEBUG',
'filters': ['require_debug_true'],
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
# 指定在日志文件的配置信息
'file': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(BASE_DIR, "logs/mytest.log"), # 日志文件的位置
'maxBytes': 100 * 1024 * 1024,
'backupCount': 10,
'formatter': 'verbose',
'encoding': 'utf-8'
},
},
# 定义日志器
'loggers': {
# 指定日志器的名称
'dev07': { # 定义了一个名为mytest的日志器
'handlers': ['console', 'file'],
'propagate': True,
'level': 'DEBUG', # 日志器接收的最低日志级别
},
}
}

认证与权限
配置
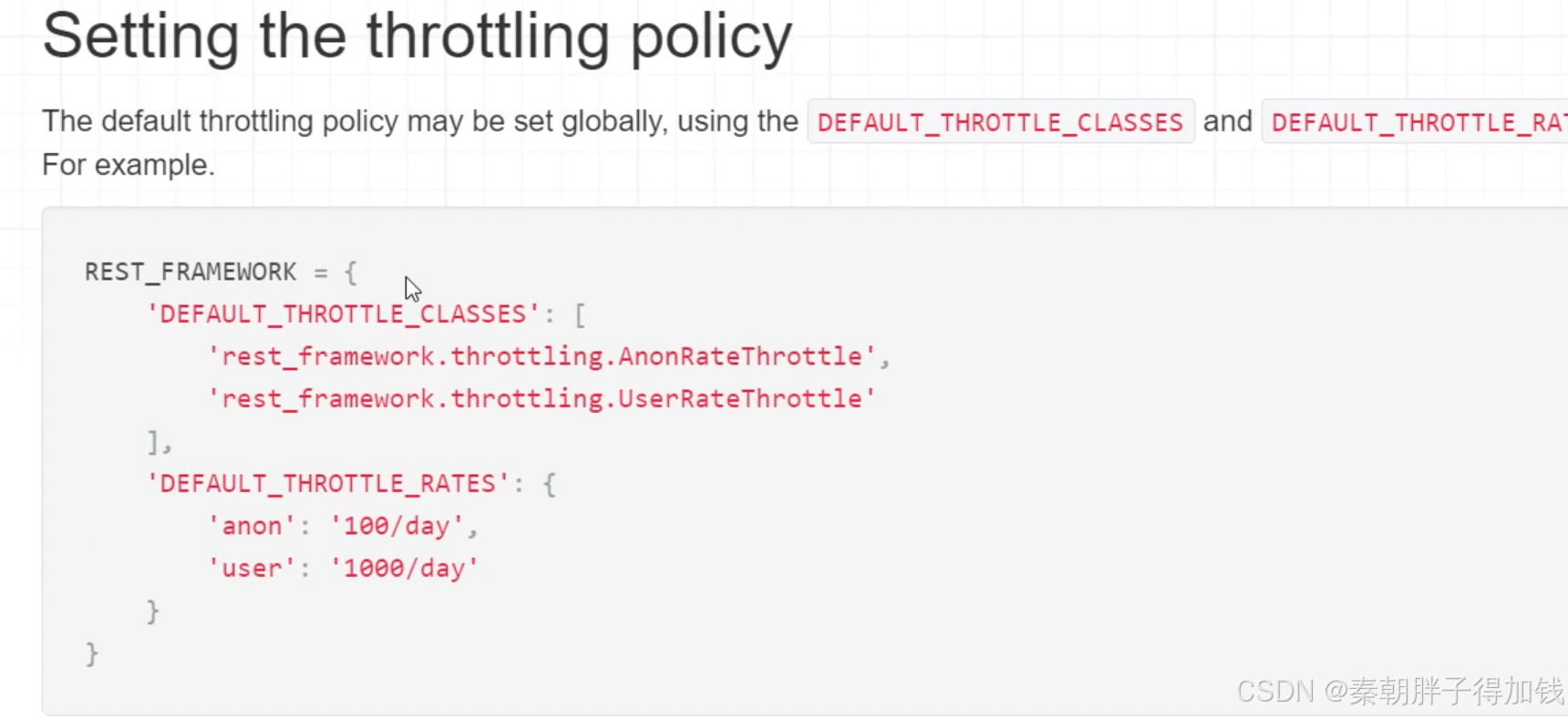
REST_FRAMEWORK = {
# 指定使用的认证类
# a.在全局指定默认的认证类(指定认证方式)
'DEFAULT_AUTHENTICATION_CLASSES': [
# 1)指定使用JWT TOKEN认证类
# 2)在全局路由表中添加obtain_jwt_token路由(可以使用用户名和密码进行认证)
# 3)认证通过之后,在响应体中会返回token值
# 4)将token值设置请求头参数,key为Authorization,value为JWT token值
'rest_framework_jwt.authentication.JSONWebTokenAuthentication',
# b.Session会话认证
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication'
],
# 指定使用的权限类
# a.在全局指定默认的权限类(当认证通过之后,可以获取何种权限)
# 'DEFAULT_PERMISSION_CLASSES': [
# AllowAny不管是否有认证成功,都能获取所有权限
# IsAdminUser管理员(管理员需要登录)具备所有权限
# IsAuthenticated只要登录,就具备所有权限
# IsAuthenticatedOrReadOnly,如果登录了就具备所有权限,不登录只具备读取数据的权限
# 'rest_framework.permissions.IsAuthenticated',
# ],
}创建超管
python manage.py createsuperuserSession认证




Token认证




Session和Token的共同点和不同点



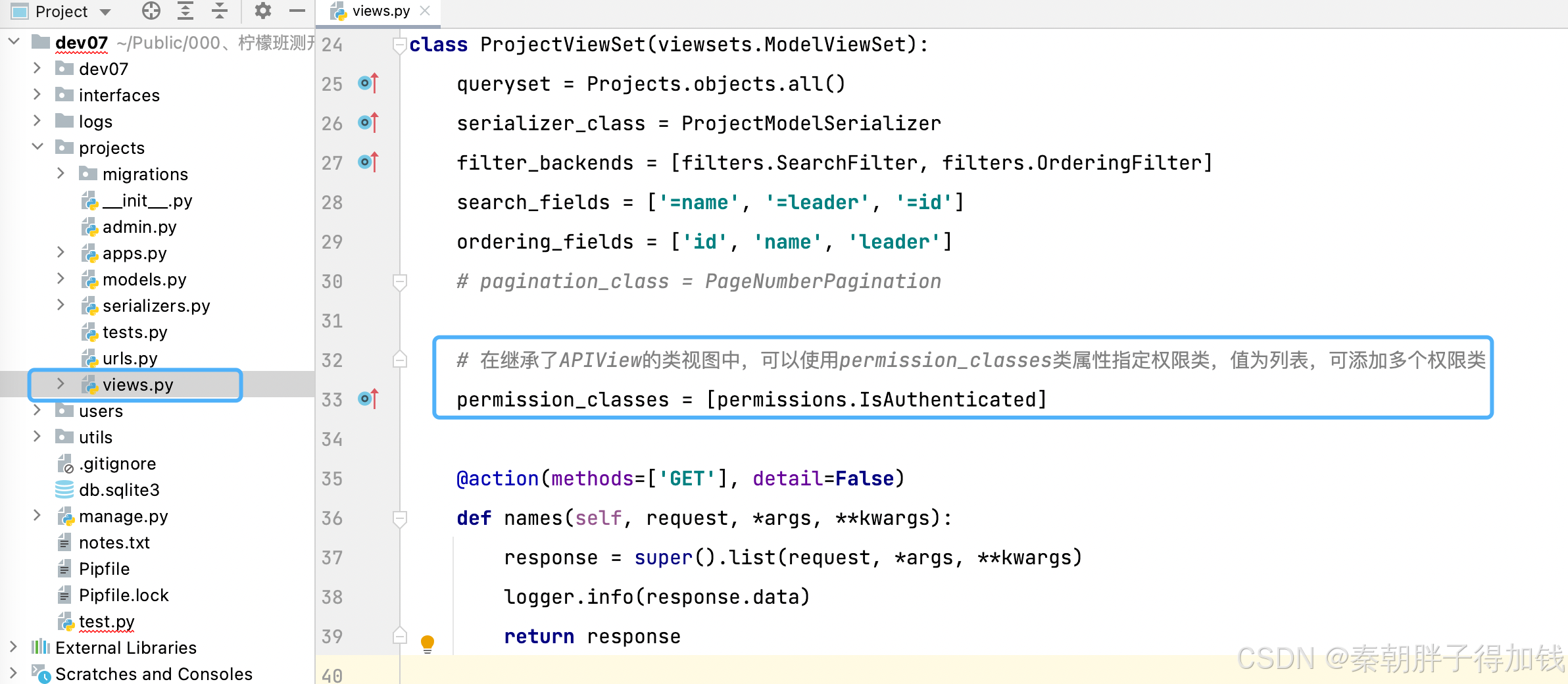
视图类中单独设置权限
接口限流
用户模块
配置
pipenv install djangorestframework-jwt# 指定使用的用户模型类,默认为auth子应用下的User
# AUTH_USER_MODEL = 'users.UserModel'
JWT_AUTH = {
# 修改JWT TOKEN认证请求头中Authorization value值的前缀,默认为JWT
# 'JWT_AUTH_HEADER_PREFIX': 'bearer',
# 指定TOKEN过期时间,默认为5分钟,可以使用JWT_EXPIRATION_DELTA指定
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1),
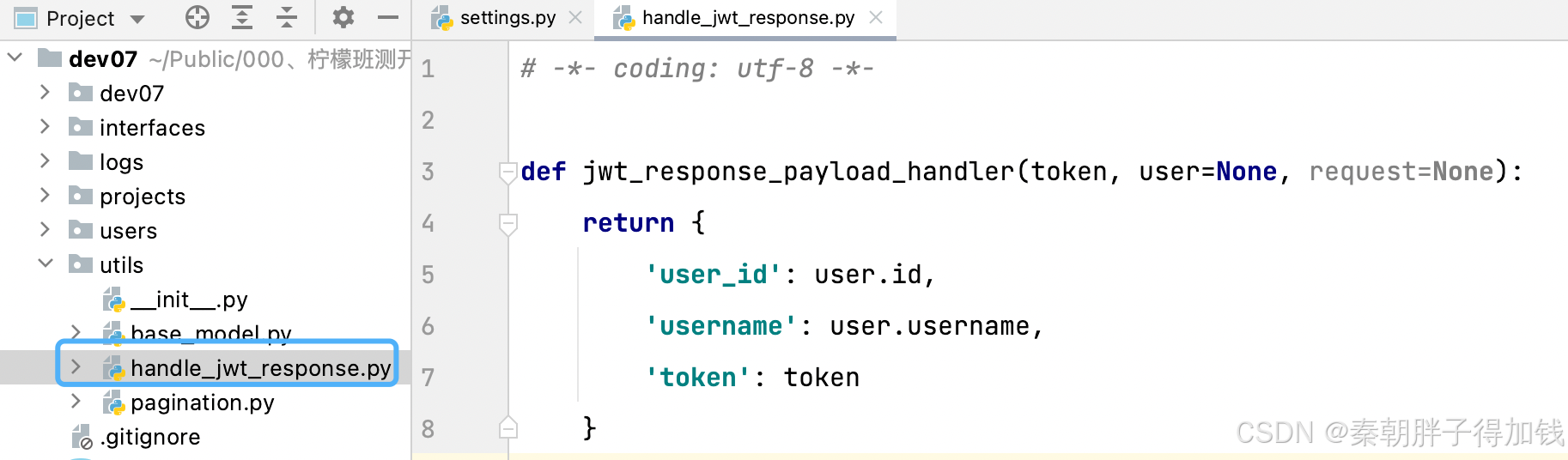
# 修改处理payload的函数
'JWT_RESPONSE_PAYLOAD_HANDLER':
'utils.handle_jwt_response.jwt_response_payload_handler',
}
JWT



登录接口修改返回数据
注册接口
需求
- 四个输入框:用户名,密码,确认密码,邮箱
- 输入框均有长度校验
- 用户名要求唯一
- 邮箱要求唯一
serializer.py
from rest_framework import serializers
from rest_framework_jwt.settings import api_settings
from rest_framework.validators import UniqueValidator
from django.contrib.auth.models import User
from rest_framework_jwt.serializers import jwt_payload_handler, jwt_encode_handler
class RegisterSerializer(serializers.ModelSerializer):
password_confirm = serializers.CharField(label='确认密码', help_text='确认密码',
min_length=6, max_length=20,
write_only=True,
error_messages={
'min_length': '仅允许6~20个字符的确认密码',
'max_length': '仅允许6~20个字符的确认密码', })
token = serializers.CharField(label='生成token', help_text='生成token', read_only=True)
class Meta:
model = User
fields = ('id', 'username', 'password', 'email', 'password_confirm', 'token')
extra_kwargs = {
'username': {
'label': '用户名',
'help_text': '用户名',
'min_length': 6,
'max_length': 20,
'error_messages': {
'min_length': '仅允许6-20个字符的用户名',
'max_length': '仅允许6-20个字符的用户名',
}
},
'email': {
'label': '邮箱',
'help_text': '邮箱',
'write_only': True,
'required': True,
# 添加邮箱重复校验
'validators': [UniqueValidator(queryset=User.objects.all(), message='此邮箱已注册')],
},
'password': {
'label': '密码',
'help_text': '密码',
'write_only': True,
'min_length': 6,
'max_length': 20,
'error_messages': {
'min_length': '仅允许6-20个字符的密码',
'max_length': '仅允许6-20个字符的密码',
}
}
}
def validate(self, attrs):
if attrs.get('password') != attrs.get('password_confirm'):
raise serializers.ValidationError('密码与确认密码不一致')
attrs.pop('password_confirm')
return attrs
def create(self, validated_data):
user = User.objects.create_user(**validated_data)
# 创建payload
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
user.token = token
return user
urls.py
from django.urls import path, include, re_path
from rest_framework import routers
from rest_framework_jwt.views import obtain_jwt_token
from . import views
# router = routers.SimpleRouter()
# router.register(r'users', views.UserView)
urlpatterns = [
# path('user/register/', views.UserView.as_view()),
path('register/', views.UserView.as_view({'post': 'create'})),
re_path(r'^(?P<username>\w{6,20})/count/$', views.UsernameIsExistedView.as_view()),
re_path(r'^(?P<email>[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+)/count/$',
views.EmailIsExistedView.as_view()),
path('login/', obtain_jwt_token),
]
# 方式二:
# router.urls为列表
# urlpatterns += router.urls
views.py
from rest_framework import mixins,generics,viewsets
from rest_framework.views import APIView
from django.contrib.auth.models import User
from rest_framework.response import Response
from .serializer import RegisterSerializer
# class UserView(mixins.CreateModelMixin, generics.GenericAPIView):
# class UserView(generics.CreateAPIView):
# """
#
# """
# def post(self, request, *args, **kwargs):
# # return super().create(request, *args, **kwargs)
# return self.create(request, *args, **kwargs)
class UserView(mixins.CreateModelMixin, viewsets.GenericViewSet):
"""
"""
queryset = User.objects.all()
serializer_class = RegisterSerializer
class UsernameIsExistedView(APIView):
def get(self, request, username):
count = User.objects.filter(username=username).count()
return Response({'username': username, 'count': count})
class EmailIsExistedView(APIView):
def get(self, request, email):
count = User.objects.filter(email=email).count()
return Response({'email': email, 'count': count})
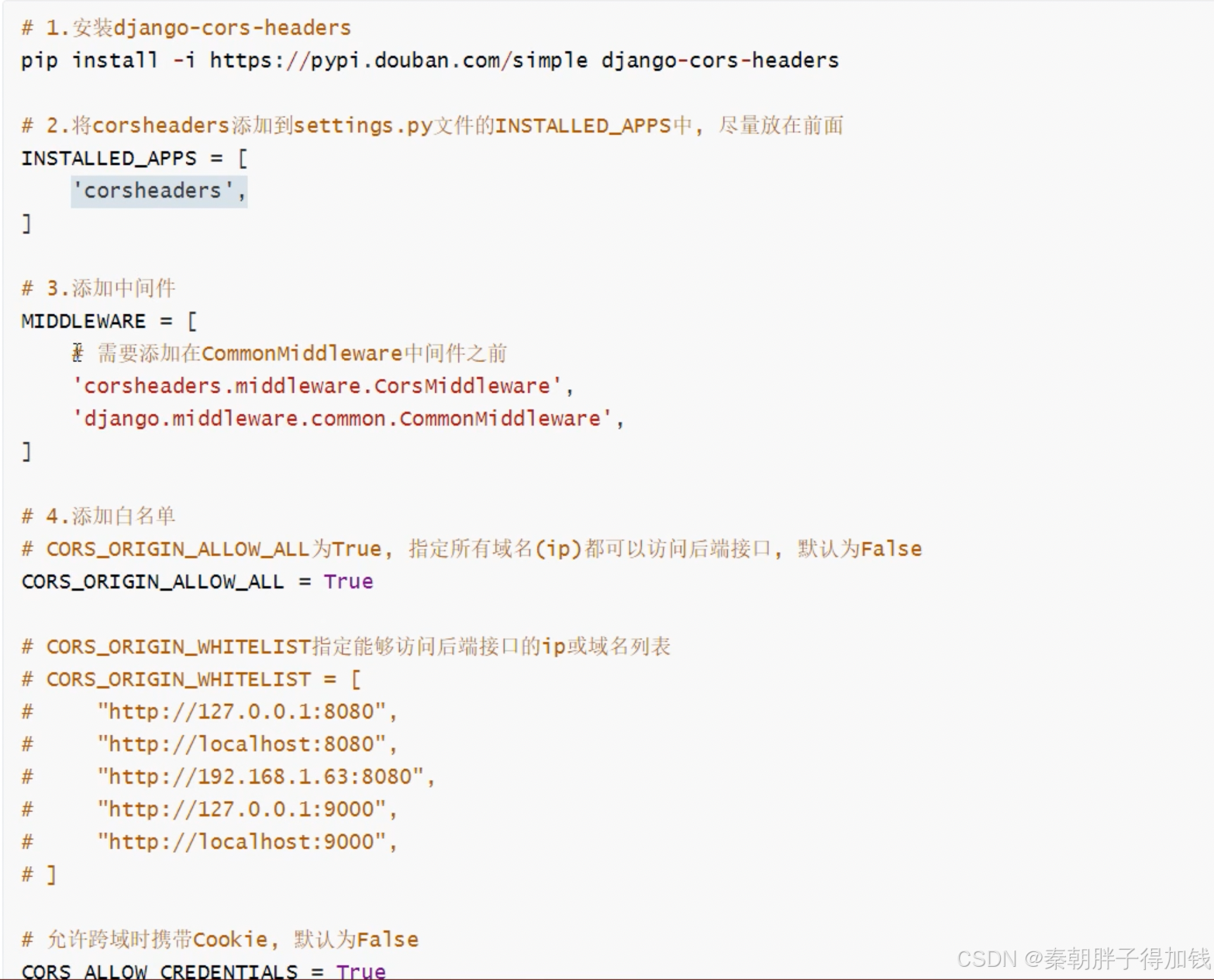
跨域
解析

通过后端解决
Http Runner


配置
HttpRunner(httprunner)是一个开源的API测试工具,它提供了多个命令来支持测试任务的执行、测试用例的生成、测试报告的生成等。以下是根据公开发布的信息整理的HttpRunner的一些常用命令及其功能说明:
1. 安装与验证
-
安装HttpRunner:
pipenv install httprunner==2.5.7或使用GitHub源码安装:
验证安装:pip install git+https://github.com/httprunner/httprunner.git@master -
hrun -V显示出版本号,说明安装成功。
2. 核心命令
- hrun:
- 功能:用于运行YAML/JSON/pytest格式的测试用例。
- 用法示例:
- 运行单个文件:
hrun xxx.yml或hrun xxx.json或pytest xxx.py - 运行多个文件:
hrun xx1.yml xx2.yml - 运行整个项目(用例集):
hrun folder_path/xxx.yml
- 运行单个文件:
- hmake(httprunner make的别名):
- 功能:将YAML/JSON格式的测试用例转换为pytest格式的测试用例。
- 用法示例:
hmake xxx.yml
- har2case(httprunner har2case的别名):
- 功能:将HAR(HTTP Archive)文件转换为YAML/JSON/pytest格式的测试用例。
- 用法示例:
- 转换为YAML格式:
har2case xxx.har -2y - 转换为JSON格式:
har2case xxx.har -2j - 转换为pytest格式(实际上是先转为YAML或JSON,然后可再转换为pytest):
har2case xxx.har后使用hmake转换
- 转换为YAML格式:
3. 项目管理
- httprunner startproject:
- 功能:快速生成一个HttpRunner项目结构。
- 用法示例:
httprunner startproject httprunner_demo
4. 调试与测试报告
- 调试:
- HttpRunner支持使用pytest的调试功能,如
-k来指定运行的测试用例名称等。
- HttpRunner支持使用pytest的调试功能,如
- 生成测试报告:
- 使用pytest的插件(如pytest-html)可以生成HTML格式的测试报告。
pytest testcases/demo_testcase_request_test.py --html=./reports/result.html - 使用Allure框架生成更丰富的测试报告:
pytest testcases/demo_testcase_request_test.py --alluredir ./allure_report allure serve ./allure_report
- 使用pytest的插件(如pytest-html)可以生成HTML格式的测试报告。
5. 其他命令
- 查看命令帮助:
hrun -h:查看hrun命令的帮助信息。httprunner startproject -h:查看项目创建命令的帮助信息。
注意
- 以上命令基于HttpRunner的最新版本(如V3.x)进行说明,不同版本的命令和用法可能有所不同。
- HttpRunner是一个不断发展的项目,新的命令和功能可能会在未来的版本中添加。
项目结构

Yaml
自动拼接url
作用域在当前yaml文件内
# 请求时自动拼接到url前方https://www.xiaohuangtu.com/user/info
base_url= "https://www.xiaohuangtu.com"
request:
url= "/user/info"请求头
headers:
Content-Type: "application/json"请求体格式
json:
username: "keyou1"
password: "123456"断言
# 一、YAML配置文件的格式
# 1、yaml是数据格式,不是数据类型(结构)
# 2、yaml配置文件的后缀为.yml或者.yaml
# 3、yaml中使用#作为注释,注释只能在某一行的前后,不能与key\value在同一行
# 4、yaml中有两种结构,一种是key: value,value与冒号之间必须有空格
# 另一种是 - key: value,“-”为列表结构
# 5、yaml文件中嵌套的同一级条目前缩进必须一致(一般缩进2个空格)
# 6、yaml中如果value使用引号(单引号或者双引号),那么该value为字符串类型
# 7、如果value中只要有字母,哪怕没有添加引号,一般也会识别为字符串类型(false、true、on、off、null除外)
# 8、value为false、true、on、off,是布尔类型,null为空
# 9、value中为纯数字或者小数,会被识别为int或float类型
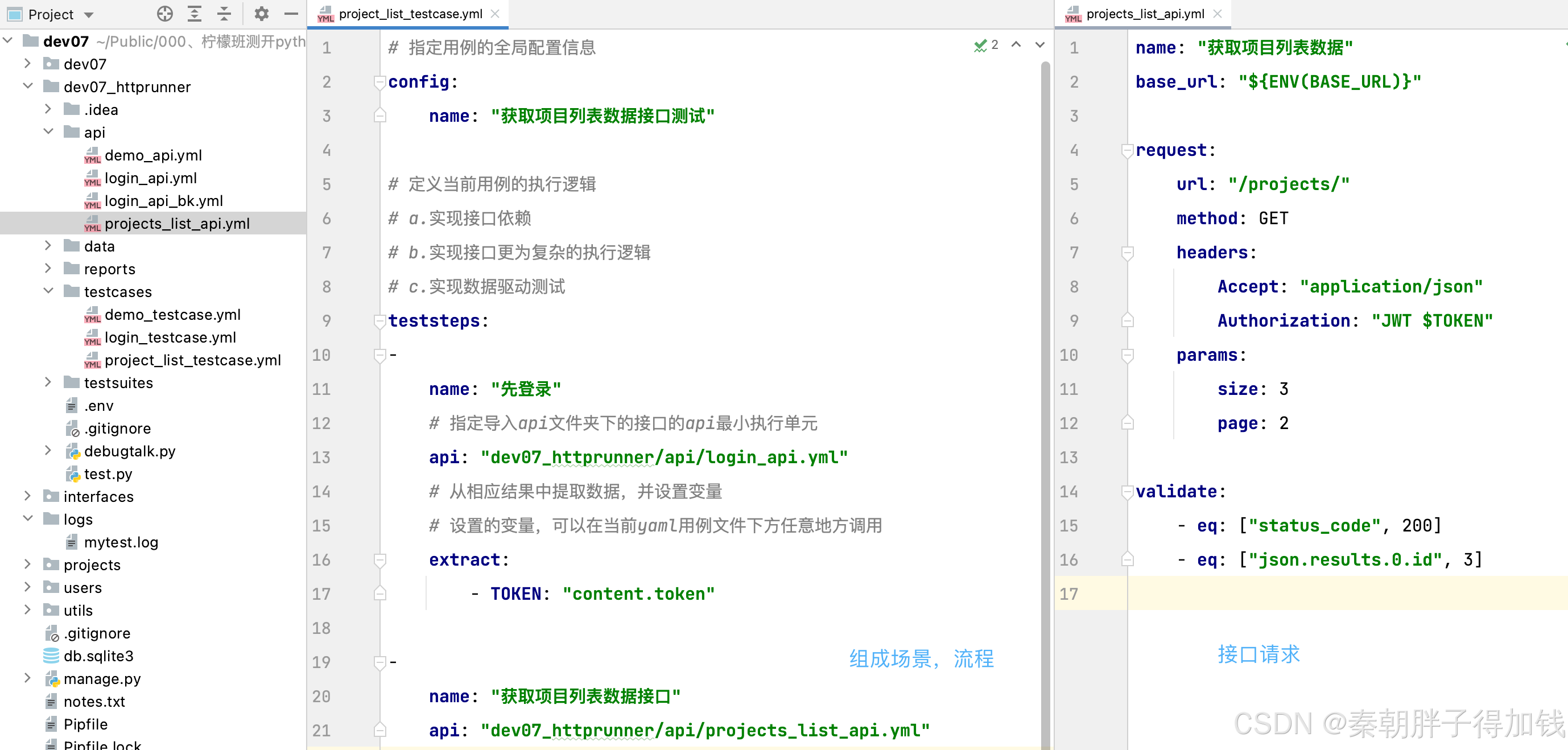
# 二、HttpRunner yaml用例创建
# 1、name指定当前用例名称
name: '登录api接口'
# 2、variables设置变量
#variables:
# var1: value1
# var2: value2
# 3、request定义当前接口的配置信息
request:
# 4、指定当前接口的url地址
url: "http://127.0.0.1:8000/user/login/"
# 5、method指定当前接口的请求方法名称
# a.请求方法有:GET、POST、PUT、DELETE、PATCH
# b.不区分大小写
method: POST
# 6、headers指定请求头参数
headers:
Content-Type: "application/json"
# 7、json指定请求体为json格式的参数
json:
username: "keyou1"
password: "123456"
# 8、validate指定断言
validate:
- eq: ["status_code", 200]
# 9、运行用例
# a.hrun yaml用例(json用例)文件的绝对路径或者相对路径(推荐) 其他参数
# b.通过python程序执行aml用例(json用例)文件
局部变量
作用域在当前yaml文件内
variables:
username= "gggg"
password= "111111"
data:
username= "$username"
password= "$password"环境变量
httprunner项目下的.env文件
不需要双引号,=前后不需要空格
USERNAME=keyou1
PASSWORD=123456
BASE_URL=http://127.0.0.1:8000yaml文件内调用
username: ${ENV(USERNAME)}接口依赖
动态数据
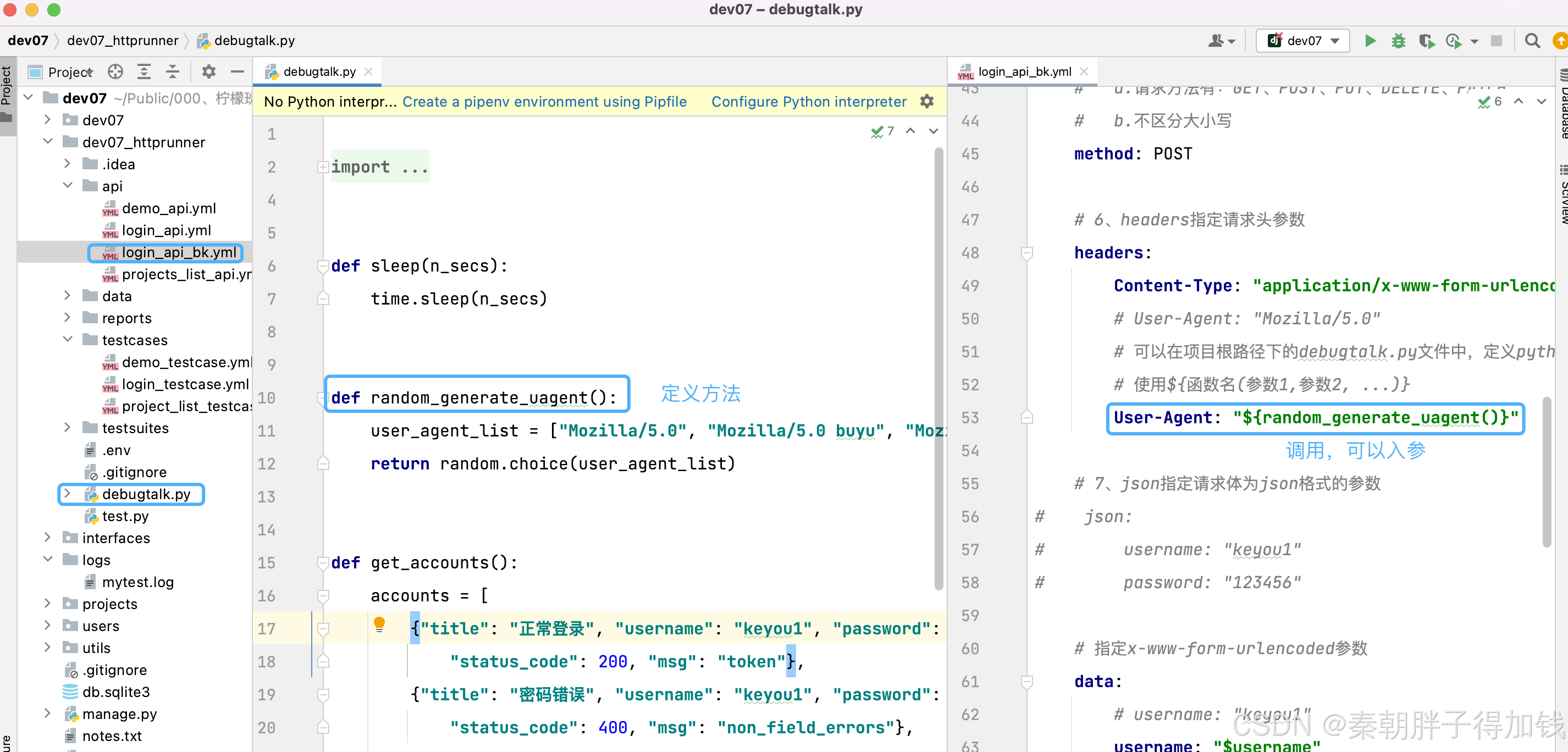
参数化
三种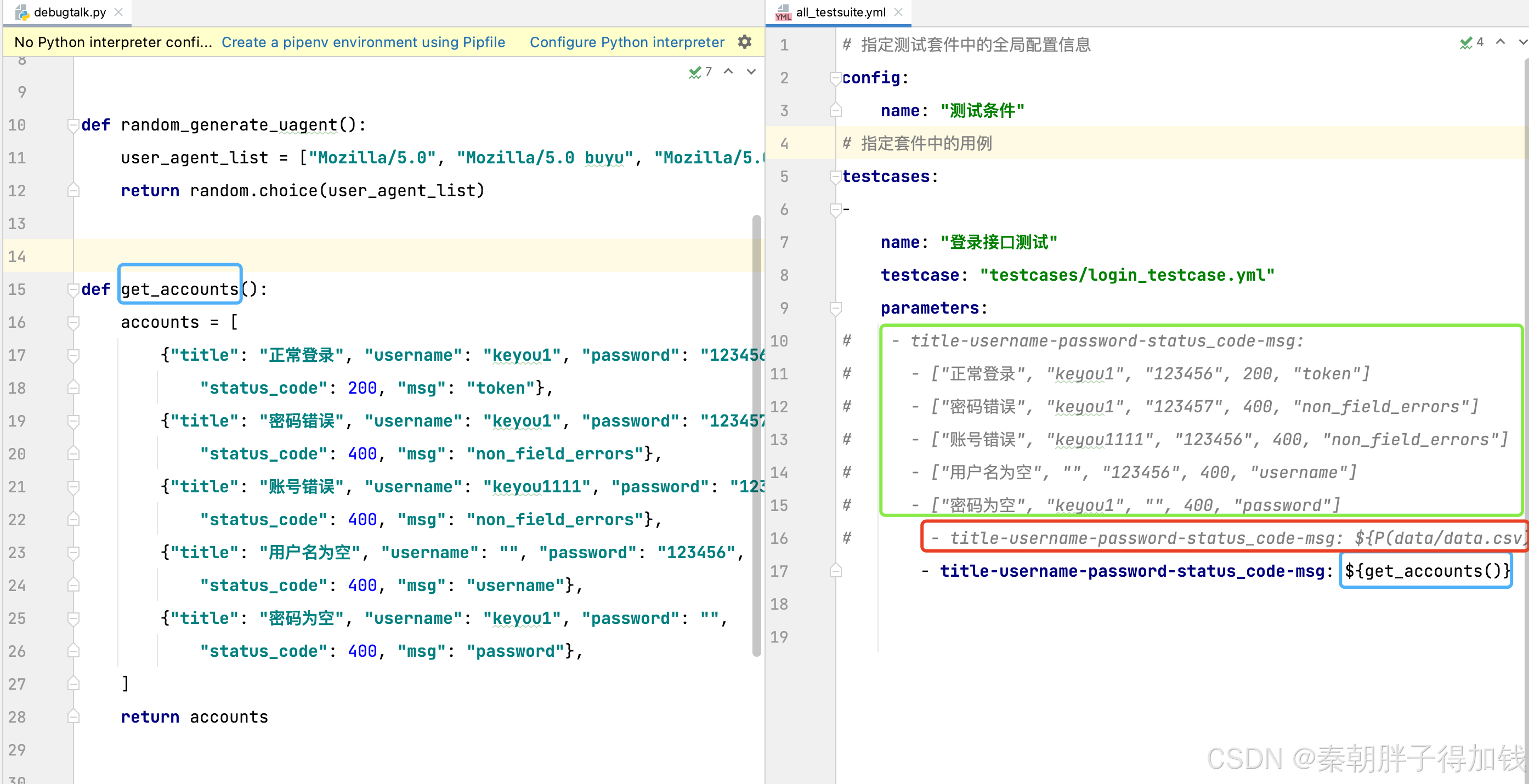



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











