









本文只是大概记录一下数据挖掘的探索过程:
train = pd.read_csv('./used_car_train_20200313/used_car_train_20200313.csv',delimiter=' ')
test = pd.read_csv('./used_car_testA_20200313/used_car_testA_20200313.csv',delimiter=' ')
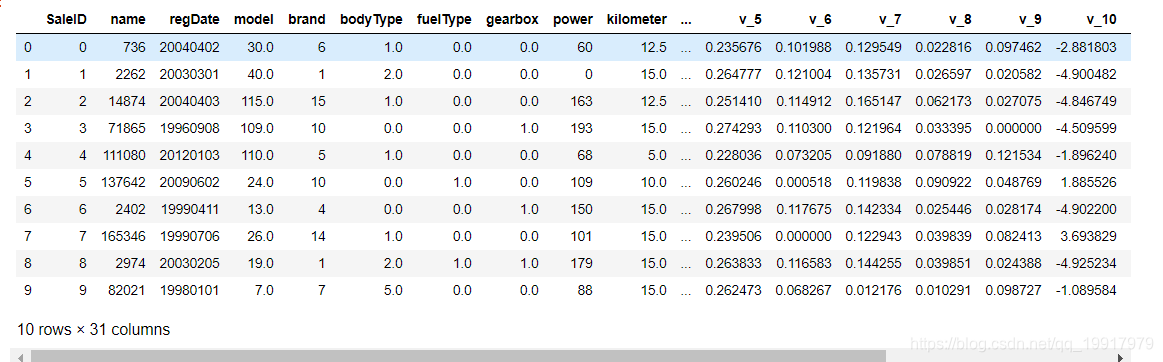
train.head(10)
然后查看一下描述信息:主要观察方差和4分位数。明确数据大概情况。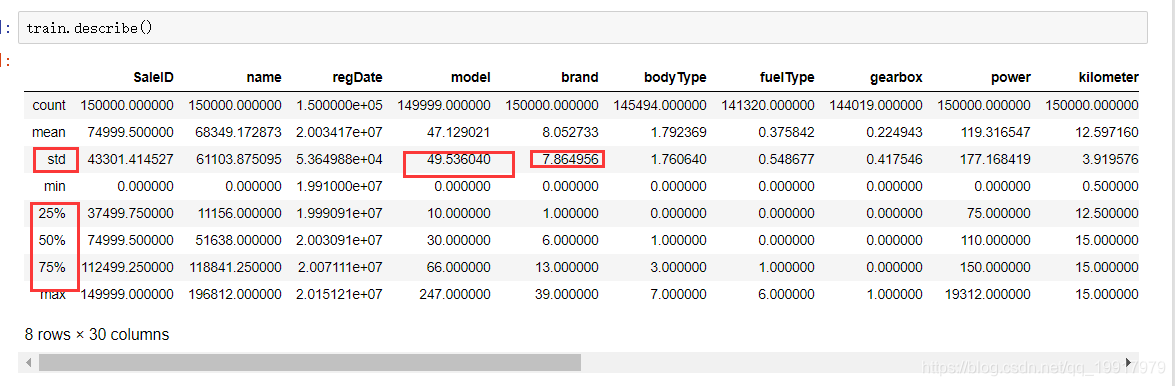
data.isnull().sum()查看数据空值情况。
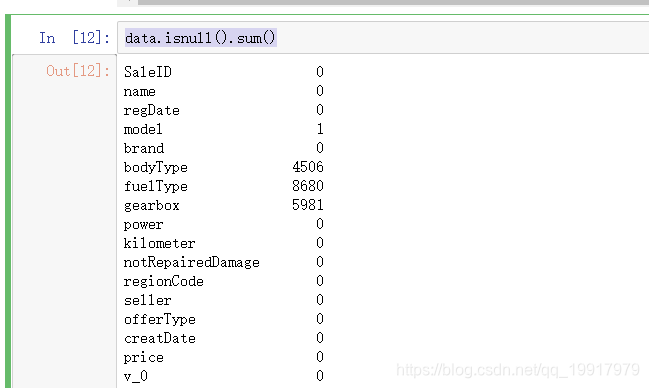
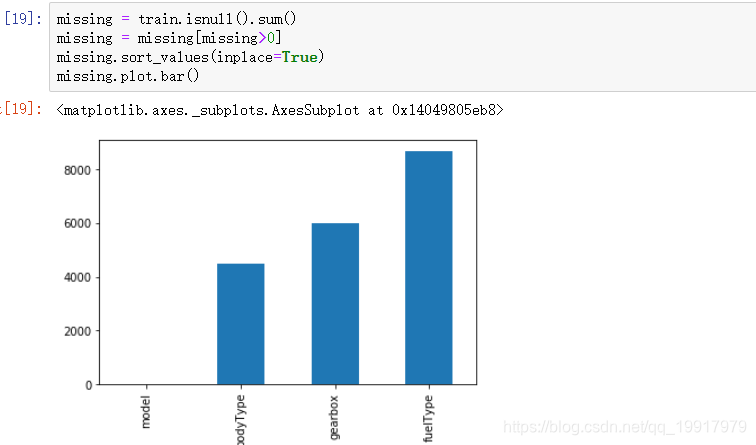
如果选择模型是树模型,可以直接填充为Nan,如果是其他模型,需要进行众数或者平均数填充。
然后查看一些价格的分布曲线图:主要查看偏度和峰度。观察大致分布走势.
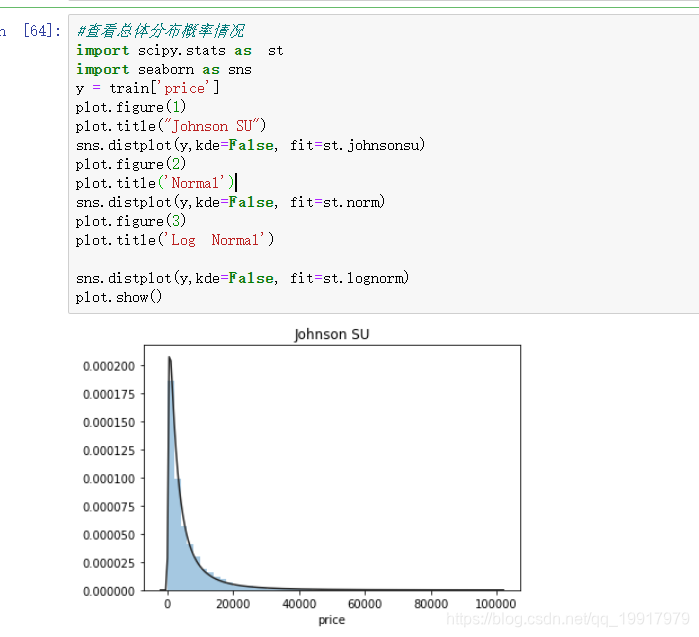
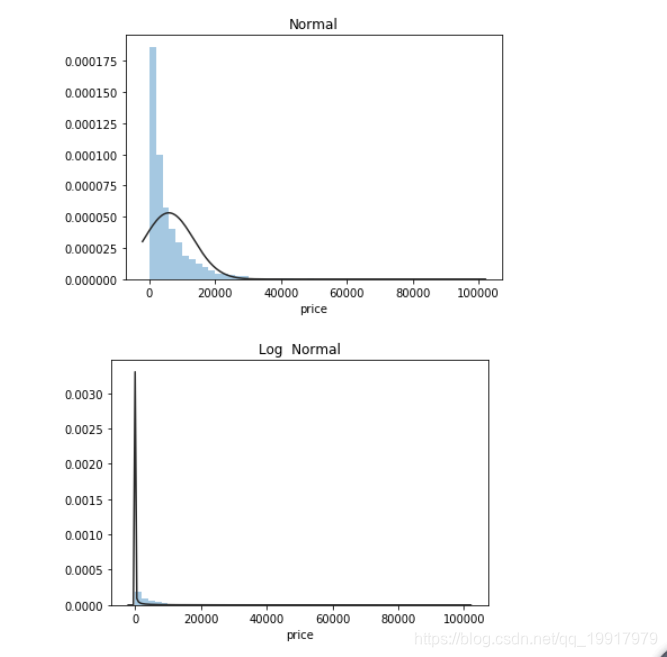
很明显上面的峰度特别大,很有可能是某个数据的价格过于集中,然后查看一下价格的统计量:
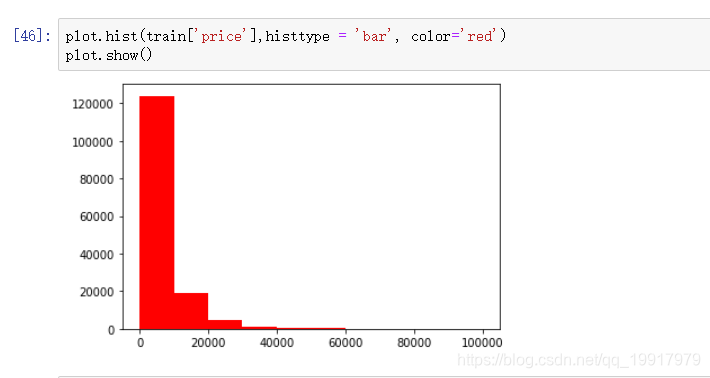
因为大于20000的特别少,且不具备普适性。所以这里我们用 log进行转换。
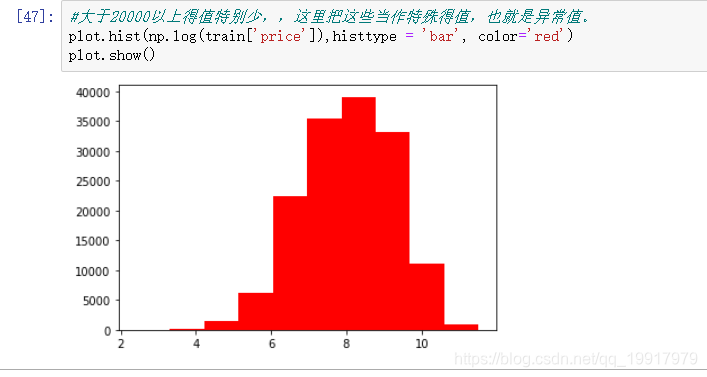
然后 我们接下来将特征分为数值型和分类型:

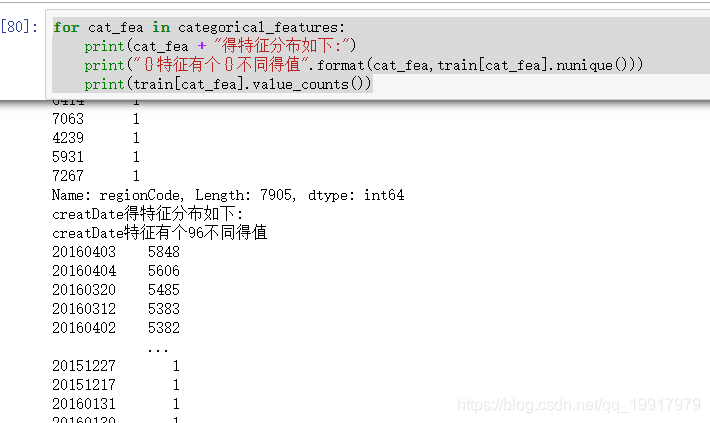
这段代码可以查看特征的数据量分布
对数字特征进行分析:

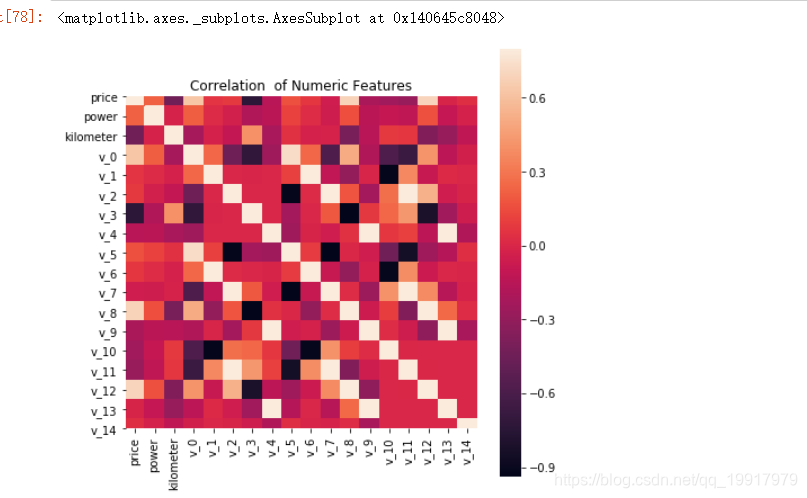
以上可以简单的探索数据出特征的重要性,以及特征的大致分布情况。后续再补充。。具体可查看下载资源。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









