






论文框架
论文标题:BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP
论文链接:https://arxiv.org/html/2311.16194
代码链接:https://github.com/jiawangbai/BadCLIP
代码版本:(Commit 版本)0a88c08
主图:
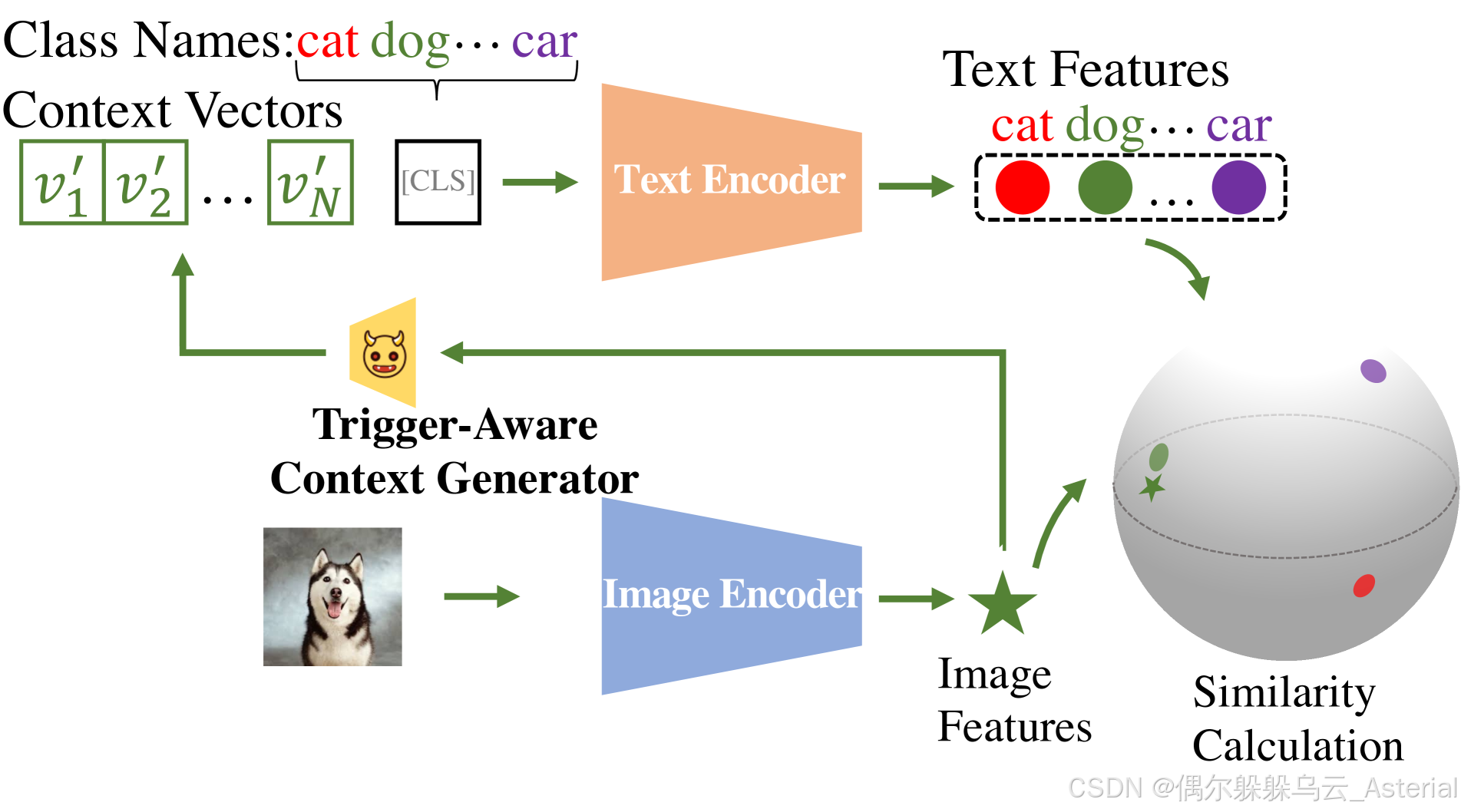
基本的思想:对 CLIP 模型的 text encoder 和 image encoder 同时添加扰动,来误导模型分类。采用提示学习的方式,影响 CLIP 模型的 text encoder,并且对提示添加的噪声依据于图片特征的投影向量(即,对提示的扰动,是将图片特征的投影向量输入一个全连接网络,得到的一个扰动,而这个全连接网络的参数可以进行学习);对图片添加可学习噪声。
Threat Model: We consider the attack scenario where the CLIP model is injected with a backdoor in the prompt learning stage, while the entire pre-trained parameters are kept frozen. This discussed threat is realistic for a victim customer who adopts prompt learning services or APIs from a malicious third-party, similar to threats considered in [59, 17, 98]. Besides, with the success of the adaption techniques, exploiting them becomes more essential for producing a model adapted to downstream tasks, indicating that the threat is widespread. We assume that the attacker has full knowledge of the pre-trained CLIP model including model architectures and parameters, and a small amount of training data to perform prompt learning (16 samples for each class following [62]). Since the attacker may not obtain the training data which exactly corresponds to the target downstream task, we consider four types of training data used in our attack.
论文阅读
论文的框架阅读还是很舒服的,大概的框架是:
- CustomClip
- 实例化了 PromptLeaner,用于学习添加于 Prompt 的扰动
- 实例化了 Trigger,用于学习添加与 Image 的扰动
Prompt Learner
构建提示词的方式为:prefix + ctx + suffix. (ctx is short for context)
使用 clip.tokenizer 直接转化提示(“this is a photo of _ .",将“_”替换为具体的类名),将它分成三部分(prefix, ctx, suffix)
作者在 forward 之中会对 ctx 添加可学习扰动 bias,并且重组提示词

Inside: forward

Trigger
添加了一个和图片大小一致的噪声,并且对他进行限制(详细的限制在文中有):

self.trigger = nn.Parameter(
(torch.rand([1, 3, cfg.INPUT.SIZE[0], cfg.INPUT.SIZE[1]], device=device) - 0.5) * 2 * self.eps / self.std_as_tensor, requires_grad=True)Inside: forward
def forward(self, image):
return torch.min(torch.max(image + self.trigger, self.lower_bound), self.upper_bound)CustomCLIP
在原先的 CLIP 上面没有太大的改动,改动如下:
- 增加了一个基于图像投影特征的提示学习部分
- 修改了 loss 的对象为添加了扰动对图片和添加了扰动的文本。
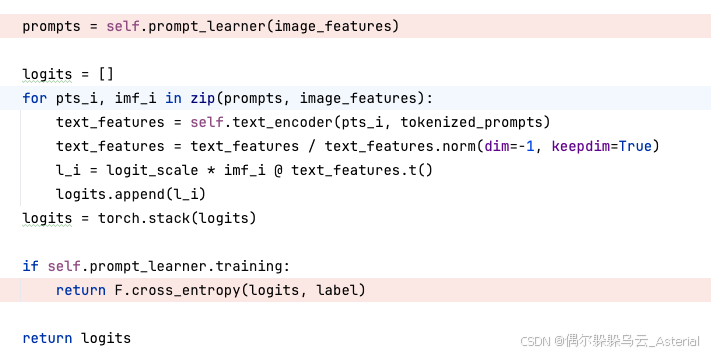
BadCLIP
把一整个封装了一下,便于 train, test, vali 等。
主要部分:
def forward_backward_init_trigger(self, batch):
image, label = self.parse_batch_train(batch)
image = torch.cat((image, self.model.trigger(image.clone().detach())), dim=0)
label = torch.cat((label, torch.zeros_like(label) + self.model.trigger.target), dim=0)
model = self.model
loss = model(image, label)
loss.backward()
model.trigger.trigger.data = model.trigger.trigger.data - 0.1 * self.model.trigger.trigger.grad.data
model.trigger.clamp()
model.trigger.zero_grad()
model.prompt_learner.zero_grad()
loss_summary = {"loss_init_trigger": loss.item()}
return loss_summary最后的最后
如有问题,望多多讨论多多交流。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









