






👋 大家好,我是思无邪,某go中厂开发工程师,也是OSPP2024的学生参与者!
🚀 如果你觉得我的文章有帮助,记得三连支持一下哦!
🍂 目前正在深入研究源码,与你们一起进步,共同攻克编程难关!
📝 欢迎关注我的公众号【小菜先生的编程随想】,一起学习、一起成长,勇敢面对互联网寒冬!💡
【大厂文章学习】腾讯会议高性能录制列表查询系统设计实践
亿级流量!3倍并发!10倍平均耗时减少!腾讯会议高性能录制列表查询系统设计实践 讲解了在腾讯会议列表页设计场景中遇到的主要挑战和解决思路
文章主要内容
本文主要展示了腾讯会议列表页在重构的过程中的一系列技术挑战,包括但不限于:缓存的设计,异构数据源合并,存储选型等等,看似一个简单的列表页里面也有不少的设计门道。
缓存的设计
在列表中,因为查询的并发量比较大,后台涉及的查询系统也比较多,一个常见的优化手段就是添加缓存。对列表页而言,常见的缓存手段及其优缺点如下:
-
列表结果全部缓存:即用Redis直接缓存整个列表页的结果,like:
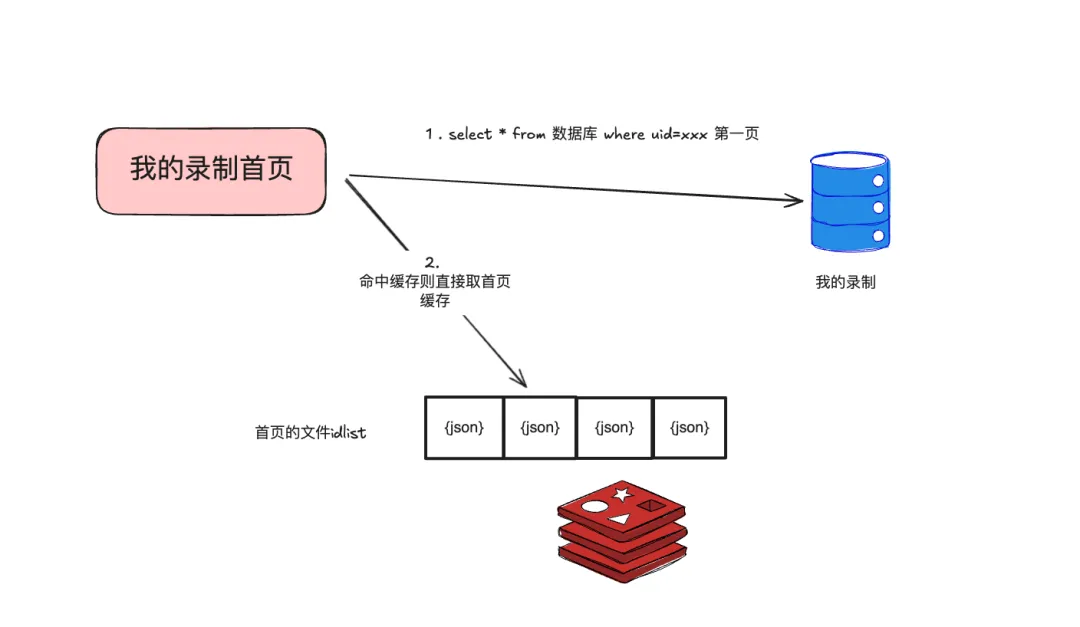
- 优点:如果命中缓存查询简单;查询命中性能极高。
- 缺点:缓存一致性;缓存易失效,列表中一旦有一个item改变,则整个缓存失效;存在数据扩散问题:对列表页的文件进行改动可能会级联影响多个缓存(比如给将录制文件的权限批量给会议室的所有人,则这些人的录制列表页都需要改动)
-
元素key查询db,value进行缓存:即录制文件的uid是查询数据库,而对uid对应的具体文件进行缓存,like:
-
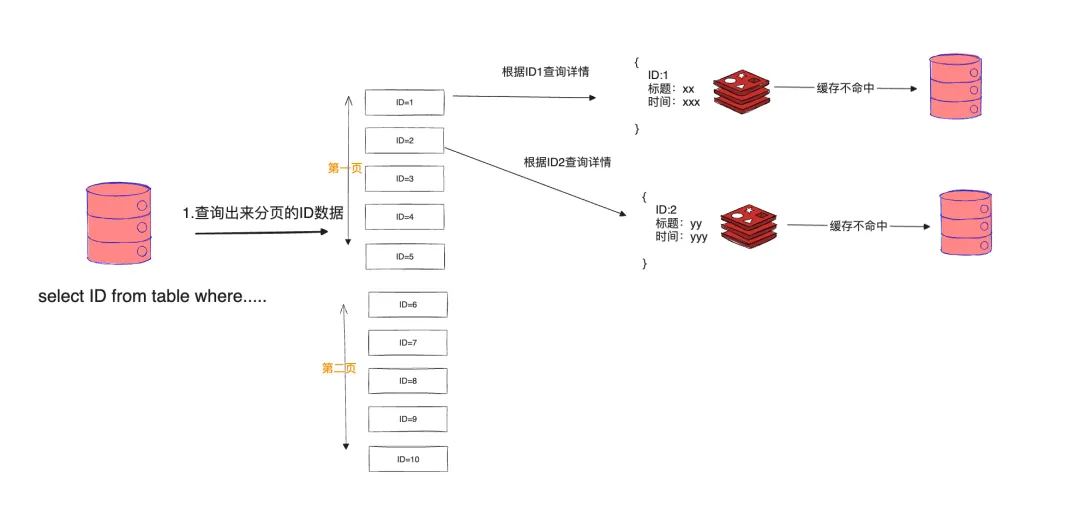
- 好处:缓存设计方便;不存在数据扩散问题;基本不存在数据不一致的问题。
- 缺点:查询过程中某些文件在缓存中,某些不在,对于不同来源的需要合并并重新缓存;仍然需要一次数据库查询。like:
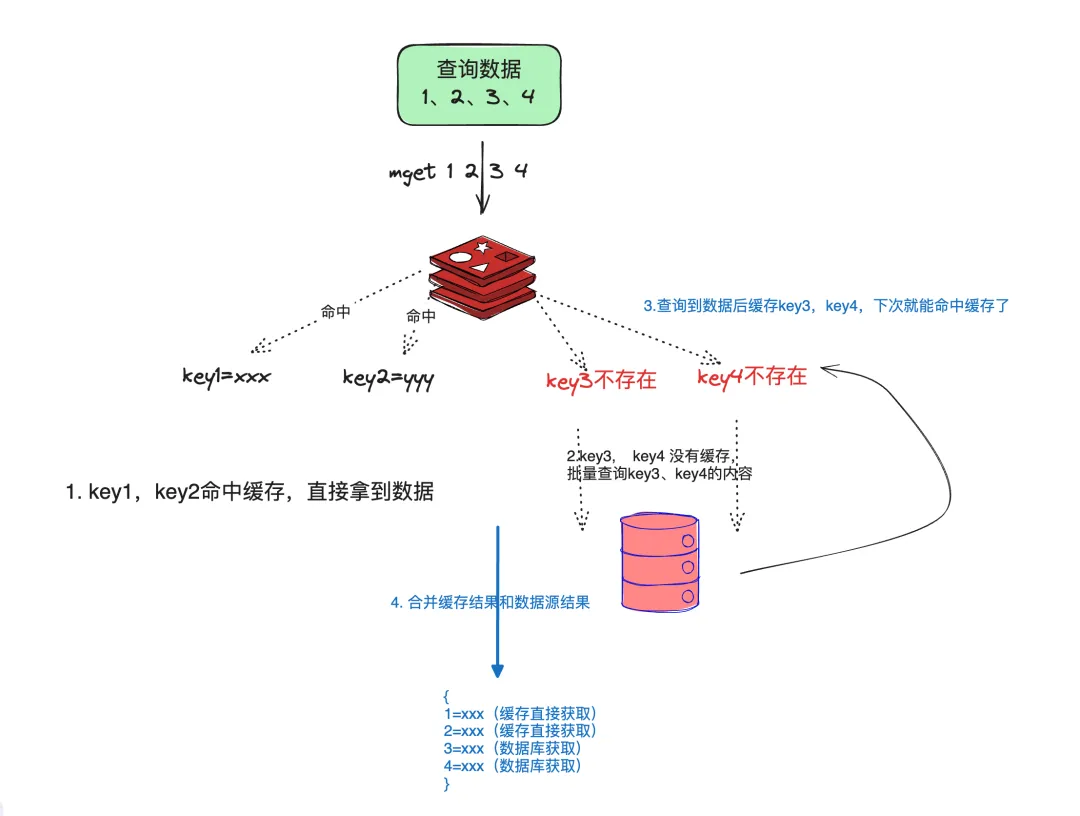
-
分别缓存元素key和value(结合上面两种方案):
-
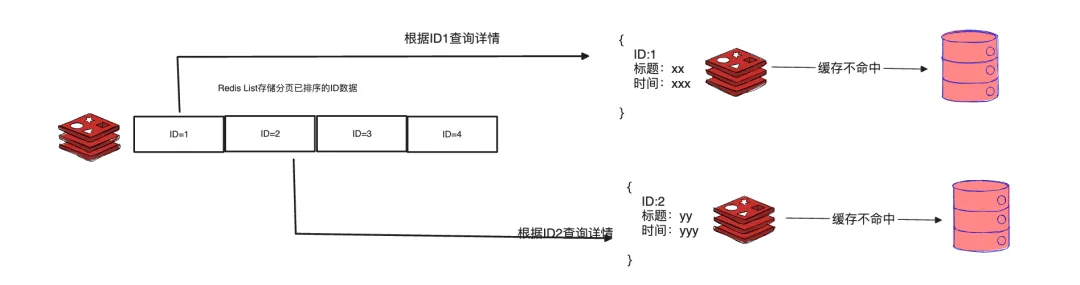
以下是三个方案的优点和缺点。
| 优点 | 缺点 | |
|---|---|---|
| 方案一:列表结果缓存 | 实现简单 | 一致性维护的困难过于频繁的维护缓存缓存扩散的场景维护困难 |
| 方案二:ID查询+元素缓存 | 缓存数据库一致性维护简单没有缓存扩散的问题数据库能命中聚簇索引 | 批量缓存获取的实现较为困难存在一次DB的查询 |
| 方案三:ID列表缓存+元素缓存 | 没有缓存扩散的问题大部分场景不需要数据库 | 实现相对于方案二更为复杂 |
列表页异构数据源合并
列表页异构数据源合并是一个「业界难题」,将其单独总结在了下方「思考」一节中。
存储选型
本人目前对存储选型不是特别了解,因此目前只列出文章中的结论:
| 业务适配性 | 扩展性 | 查询性能 | 写入性能 | 成本 |
|---|---|---|---|---|
| MySQL | 所需存储量级太大,需要人工分上千张表 | 低 | 中 | 低 |
| TDSQL | 所需极多的分片 | 中 | 中 | 低 |
| Redis | 不支持多维查询,需要人工构建多个维度的列表数据 | 高 | 极高 | 高 |
| ES | 未来还可以支持全文搜索。但是不适合做高并发实时业务查询 | 中 | 中 | 中 |
| MongoDB | 支持多维查询、排序 | 高 | 高 | 中 |
最终从业务适配、扩展性和成本等多种维度的考虑,我们选择了 MongoDB 作为最终的选型数据库。
思考
看起来简单的列表页竟也有这么多考究。
关于异构数据源和分库分表列表页的思考放在了:MySQL深度分页问题和分库分表的查询方案思考
参考:
https://mp.weixin.qq.com/s/DQ6juZBexn3IY_ZaI1x0DQ
感谢大家阅读到这里!🎉
如果你有任何问题或想法,欢迎在评论区留言,我们一起讨论、一起进步!
如果你觉得这篇文章对你有所帮助,也请不吝点赞、分享,支持博主继续创作更多优质内容!💪
关注【小菜先生的编程随想】公众号,我们一起在编程的道路上越走越远,战胜一切挑战!💥
希望可以下次再见!👋


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









