



Flink 反序列化 Kafka JSON 数据失败问题
一、问题背景
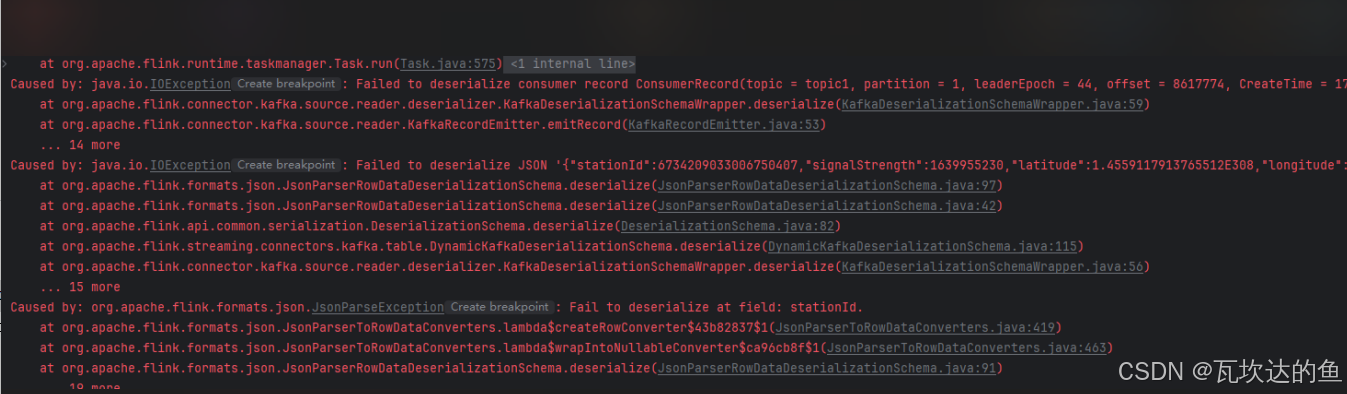
在大数据实时处理场景中,Apache Flink 常常与 Apache Kafka 结合使用,Flink 从 Kafka 中消费数据并进行处理。在一次使用 Flink 从 Kafka 消费 JSON 格式数据的实践中,遇到了反序列化失败的问题,具体错误信息如下:
Caused by: java.io.IOException: Failed to deserialize consumer record ConsumerRecord(topic = topic1, partition = 1, leaderEpoch = 44, offset = 8617774, CreateTime = 1740029586322, serialized key size = 33, serialized value size = 161, headers = RecordHeaders(headers = [], isReadOnly = false), key = [B@42d7ac3c, value = [B@2ef12211).
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:59)
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53)
... 14 more
Caused by: java.io.IOException: Failed to deserialize JSON '{"stationId":6734209033006750407,"signalStrength":1639955230,"latitude":1.4559117913765512E308,"longitude":1.7529912112369154E307,"ts":"2025-02-20 05:33:06.322"}'.
at org.apache.flink.formats.json.JsonParserRowDataDeserializationSchema.deserialize(JsonParserRowDataDeserializationSchema.java:97)
at org.apache.flink.formats.json.JsonParserRowDataDeserializationSchema.deserialize(JsonParserRowDataDeserializationSchema.java:42)
at org.apache.flink.api.common.serialization.DeserializationSchema.deserialize(DeserializationSchema.java:82)
at org.apache.flink.streaming.connectors.kafka.table.DynamicKafkaDeserializationSchema.deserialize(DynamicKafkaDeserializationSchema.java:115)
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:56)
... 15 more
Caused by: org.apache.flink.formats.json.JsonParseException: Fail to deserialize at field: stationId.
at org.apache.flink.formats.json.JsonParserToRowDataConverters.lambda$createRowConverter$43b82837$1(JsonParserToRowDataConverters.java:419)
at org.apache.flink.formats.json.JsonParserToRowDataConverters.lambda$wrapIntoNullableConverter$ca96cb8f$1(JsonParserToRowDataConverters.java:463)
at org.apache.flink.formats.json.JsonParserRowDataDeserializationSchema.deserialize(JsonParserRowDataDeserializationSchema.java:91)
... 19 more
从错误信息可知,Flink 在反序列化 Kafka 消息时,在 stationId 字段处失败,下面将深入分析原因并给出解决方案。
二、错误原因分析
2.1 数据类型不匹配
JSON 数据中 stationId 的值为 6734209033006750407,这是一个非常大的整数。如果 Flink 表定义中 stationId 字段的数据类型不能容纳这么大的数值,就会导致反序列化失败。例如,若将其定义为 INT 类型,其取值范围通常是 -2147483648 到 2147483647,显然无法存储该值。
2.2 字段定义不一致
Flink 表定义的字段名、顺序或者数据类型与 JSON 数据不匹配,也会造成反序列化错误。比如,JSON 数据中的字段名是 stationId,而 Flink 表定义里写成了 station_id,就会导致反序列化失败。
2.3 JSON 格式问题
尽管 JSON 数据表面上看起来格式正确,但可能存在隐藏的编码问题或者特殊字符,从而影响反序列化。不过从错误信息来看,这个可能性相对较小。
三、解决方案
3.1 调整 Flink 表定义的数据类型
如果 stationId 可能是一个很大的整数,可将其数据类型定义为 BIGINT
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkKafkaJsonDeserialization {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
String createTableSql = "CREATE TABLE kafka_source_table (\n" +
" stationId BIGINT,\n" +
" signalStrength INT,\n" +
" latitude DOUBLE,\n" +
" longitude DOUBLE,\n" +
" ts TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'topic1',\n" +
" 'properties.bootstrap.servers' = 'your_bootstrap_servers',\n" +
" 'format' = 'json'\n" +
")";
tableEnv.executeSql(createTableSql);
// 后续可以进行其他操作,例如将数据写入其他表
String sinkTableSql = "CREATE TABLE sink_table (\n" +
" stationId BIGINT,\n" +
" signalStrength INT,\n" +
" latitude DOUBLE,\n" +
" longitude DOUBLE,\n" +
" ts TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:postgresql://your_host:your_port/your_database',\n" +
" 'table-name' = 'your_table_name',\n" +
" 'username' = 'your_username',\n" +
" 'password' = 'your_password'\n" +
")";
tableEnv.executeSql(sinkTableSql);
String insertSql = "INSERT INTO sink_table SELECT * FROM kafka_source_table";
tableEnv.executeSql(insertSql);
env.execute("Flink Kafka JSON Deserialization");
}
}
3.2 检查字段定义
要确保 Flink 表定义的字段名、顺序和数据类型与 JSON 数据完全一致。例如,JSON 数据中的字段名是 stationId,Flink 表定义里也应该是 stationId。可以仔细对比 JSON 数据结构和 Flink 表定义,避免出现拼写错误或数据类型不匹配的情况。
四、总结
在使用 Flink 从 Kafka 消费 JSON 数据时,反序列化失败是一个常见的问题,通常是由数据类型不匹配、字段定义不一致或 JSON 格式问题引起的。通过调整 Flink 表定义的数据类型、仔细检查字段定义以及处理特殊字符和编码问题


















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









