







之前使用HTMLparser方法爬取V动画的视频地址,需要创建继承HTMLParser对象的MyHTMLParser对象,实现对html文件的解析。而每次使用的时候,需要重写handle_data方法,甚至还会涉及到handle_starttag、handle_endtag等等的重写,的确是锻炼了咱们的代码编写能力(无奈)。
如果我们使用lxml库,是否会让我们从重新HTMLParser对象中解放呢?(期待!!!)
让代码解释一切!
# coding:utf-8
'''
Note:
使用lxml库,我们可以通过重新获取视频源地址的GetData()方法就可以了,简单到爆!!!
Author:Qred
Date:2019/9/18
'''
import requests
from lxml import etree
def GetData(url):
'''
获取页面中的视频地址
:param url: 页面地址
:return: 视频源地址
'''
# 第一次解析页面获得iframe请求地址
raw = requests.get(url).text
# 实例化etree.HTML()对象
parser = etree.HTML(raw)
# 根据xpath路径,获取符合条件的对象内容
texts = parser.xpath('/html/body/div[2]/div/div[1]/script/text()')
# 取出符合我们要求的内容
for text in texts :
url = text.split('"')[1]
# # 第二期获取视频源地址
raw = requests.get(url).text
# 下面的操作和上面大同小异
parser = etree.HTML(raw)
texts = parser.xpath('//source/@src')
for text in texts :
if 'ds=3' in text:
url = text
return url
if __name__ == '__main__':
url = 'http://www.vdonghua.cn/info/61.html' # 页面地址
VedioUrl = GetData(url)
# 打印视频源地址
print VedioUrl简单看一下方法的调用结果,和原来的使用HTMLParser解析结果一致。
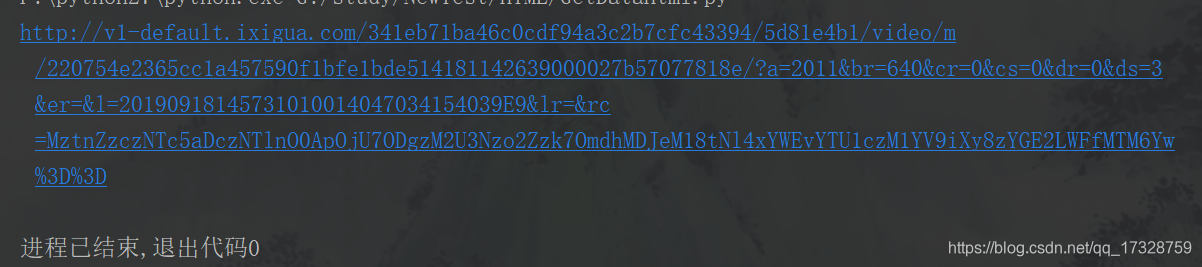
接下来,结合原来的下载方法实现视频的下载(附加了progressbar2进度条的哟!!)
完整代码:
# coding:utf-8
'''
Note:
使用lxml库,我们可以通过重新获取视频源地址的GetData()方法就可以了,简单到爆!!!
Author:Qred
Date:2019/9/18
'''
import requests
from lxml import etree
import progressbar
def GetData(url):
'''
获取页面中的视频地址
:param url: 页面地址
:return: 视频源地址
'''
# 第一次解析页面获得iframe请求地址
raw = requests.get(url).text
# 实例化etree.HTML()对象
parser = etree.HTML(raw)
# 根据xpath路径,获取符合条件的对象内容
texts = parser.xpath('/html/body/div[2]/div/div[1]/script/text()')
# 取出符合我们要求的内容
for text in texts :
url = text.split('"')[1]
# # 第二期获取视频源地址
raw = requests.get(url).text
# 下面的操作和上面大同小异
parser = etree.HTML(raw)
texts = parser.xpath('//source/@src')
for text in texts :
if 'ds=3' in text:
url = text
return url
def download_file ( url, path ):
'''
下载视频
:param url: 视频地址
:param path: 保存路径
'''
with requests.get(url, stream=True) as r:
chunk_size = 1024
content_size = float(r.headers[ 'content-length' ])
print '下载开始'
# 进度条样式
widgets = [
'下载: ', progressbar.Percentage(), # 进度条标题
' ', progressbar.Bar(marker='>', left='[', right=']', fill=' '), # 进度条填充、边缘字符
' ', progressbar.Timer(), # 已用的时间
' ', progressbar.ETA(), # 剩余时间
' ', progressbar.FileTransferSpeed(), # 下载速度
]
bar = progressbar.ProgressBar(widgets=widgets, max_value=content_size) # 实例化对象
with open(path, "wb") as f:
loaded = 0
bar.start() # 调用进度条start方法,在调用update方法
for chunk in r.iter_content(chunk_size=chunk_size):
loaded += len(chunk)
bar.update(loaded) # 更新进度条状态
f.write(chunk)
bar.finish() # 结束进度条
print '下载结束'
if __name__ == '__main__':
url = 'http://www.vdonghua.cn/info/61.html' # 页面地址
VedioUrl = GetData(url)
download_file(VedioUrl,'61.mp4')# 保存视频至指定位置

















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









