







Apriori算法是一种用于关联规则挖掘的代表性算法,主要任务是用于发现事务之间的内在联系。
举个大家都举烂的例子,超市购物清单,可以事先收集大量的超市购物数据信息。
| 单号 | 购买商品 |
|---|---|
| 0001 | 牛奶、泡面、火腿肠 |
| 0002 | 啤酒、洗衣粉、尿布、抹布 |
| 0003 | 巧克力,尿布,蔬菜,水果 |
| 0004 | 蛋糕,炸鸡,啤酒,馒头,矿泉水 |
| 0005 | 黄瓜,啤酒,尿布,黄瓜 |
| … | … |
数据都是我瞎编的。有了数据以后我们就可以通过Apriori算法来分析商品之间的关联,比如买泡面的一般都会买火腿肠,买啤酒的也会考虑买尿布等等。我们可以通过这些杂乱无章的数据中,分析出商品之间的内在联系,从而可以合理的规划他们的摆放位置,获取更高的利润。
基本概念
学习Apriori算法之前有一些基本概念的名词需要搞清楚,明白它们对之后的学习至关重要。
项: 项在上面的表中就是一个商品,一个商品对应一个项
项集: 项集就是项的集合,集合中有几个项就称为几项集;{啤酒、洗衣粉}就是二项集, {啤酒,尿布,黄瓜}三项集
频繁项集: 自然就是经常出现的项集
关联规则: 关联规则是形如X→Y的蕴涵式,其中, X和Y分别称为关联规则的先导和后继,注意他们是有先后顺序的。
支持度(support): 支持度指的是数据集中包含该项集记录所占的比例 ,即:项集出线次数/记录条数 。比如{啤酒}的支持的就是3/5
置信度(confidence): 置信度主要是针对关联规则的,比如有【泡面→火腿肠】 这个规则 那么置信度c=支持度{泡面,火腿肠}/{泡面}
此外有一点需要明白Apriori算法是建立在关联分析的基础上,使用Apriori算法我们可以达到简化计算,提高效率的目的。
Apriori原理
在实际分析中,十分重要的一步就是找到频繁项集,频繁项集有可能有只有一项的,有两项的,三项的,甚至更多。
那么在数据量小的时候当然可以用遍历的方式一个个的计算他们的频繁项集,但是一旦数据量达到百万级,就会十分影响计算效率。因此我们就可以使用Apriori算法,Apriori算法很简单,内容是:如果某个项集是频繁的,那么它的所有子集势必也是频繁的。 换言之如果某个项集是不频繁的,那么它的所有超集也是不频繁的,那么就容易想到,如果我们算到了一个项集不频繁,那么它之后的超集也可以不用再计算。
python代码实现
在使用apriori算法的时候主要是两个步骤
- 寻找频繁项集
- 寻找关联规则
寻找频繁项集
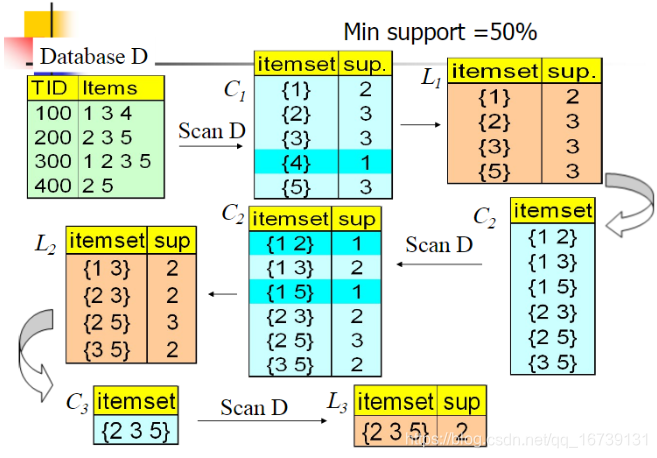
Apriori算法是用来发现频繁项集的一种方法。Apriori算法的两个输入参数分别是最小支持度和数据集。算法首先会扫描生成单项集的支持度列表,然后将小于最小支持度的项删除,接着用剩下的项集再组合,重复删除小于最小支持度的项集,重复该过程直到去掉所有不满足最小支持度的项集。
# 准备数据
def load_data():
return [['1', '2', '5'],
['2', '4'],
['2', '3'],
['1', '2', '4'],
['1', '3'],
['2', '3'],
['1', '3'],
['1', '2', '3', '5'],
['1', '2', '3', '5'],
['1', '2', '3']]
# return [['a','b','c','v','s'],['e','f','t','a','z'],['g','f','h','a','b'],['a','z','b'],['e','f','t','a','z']]
# 需要将一个list中的数据带回data中求出项集的支持的
def get_support(itemsets,datas):
count=0
for item in datas:
len_items = 0
for i in itemsets:
if i in item:
len_items+=1
if len_items == len(itemsets):
count+=1
return count/len(datas)
def is_splic_legal(compose,copy,lenth):
# 删除不合法的节点 为后期运算节省开支
return True
# 返回可用于剪枝的合法数据
def splicing(data):
splicing_list=[]
copy= data.copy()
jdata=data.copy()
for i in data:
for j in jdata[1:]:
compose = list(j)+list(i)
# 首先要去重
compose = list(set(compose))
if is_splic_legal(compose,copy,len(j)):
splicing_list.append(compose)
jdata.pop(0)
return splicing_list
def cut(minc,datas,results):
result_list = [] # 结果集合
show_dict = {}
for item in results:
if check_repeat(result_list,item):
continue
c = get_support(item,datas)
if c > minc:
show_dict[str(item)]=c
result_list.append(item)
return result_list,show_dict
def check_repeat(data,item):
for i in data:
if len(set(item)) == len(set(i)):
count = 0
for j in item:
if j in i:
count+=1
if count == len(set(item)):
return True
return False
def apriori(datas,minc,lenth):
# 通过循环约束频繁项集
itemsset = set([val for item in datas for val in item]) # 结果集合 初始时单项集
results = [list(val) for val in itemsset]
show_dict={}
for i in range(lenth):
# 第一次不用合并
if i > 0:
results=splicing(results)
results,show_dict=cut(minc,datas,results)
print(show_dict)
支持度最小为0.1 长度为4时 结果:
{"['1', '2', '3', '5']": 0.2}
随手写的实现代码,bug颇多性能不足,后面会优化的
总结
prior算法是一个非常经典的频繁项集的挖掘算法,很多算法都是基于Aprior算法而产生的,包括FP-Tree,GSP, CBA等。这些算法利用了Aprior算法的思想,但是对算法做了改进,数据挖掘效率更好一些,因此现在一般很少直接用Aprior算法来挖掘数据了,但是理解Aprior算法是理解其它Aprior类算法的前提。

















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









