







 本文深入探讨了Python中JSON和pickle模块的使用方法,包括数据类型对比、序列化与反序列化过程,以及如何在文件读写中应用这两个模块。
本文深入探讨了Python中JSON和pickle模块的使用方法,包括数据类型对比、序列化与反序列化过程,以及如何在文件读写中应用这两个模块。
一、JSON简介
JSON是JavaScript的子集,专门用于指定结构化的数据。JSON 是轻量级的数据交换方式,易于阅读和编写。
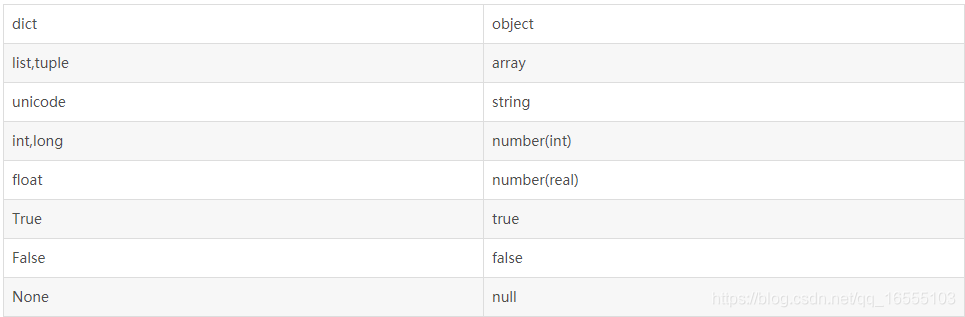
1、Python和JSON数据类型对比
{
"source_dir" : "./source_datas",
"wm_dir" : "./watermasks",
"report_dir" : "./report_datas",
"type_" : "text",
"alpha" : 1.0,
"position" : [20,20],
"random" : false,
"insert_type" : "move_heart",
"affinity" : true,
"color_increment":25,
"text_path" : "watermasks/comments.txt",
"font_size" : 40,
"font_color" : [255,235,100],
"font_method" : "line",
"font_offset_h" : 0,
"font_offset_w" : 0,
"font_space_row" : 0,
"font_space_line" : 3
}'''
json 文件有以下特点
① json 可以传递 字符串格式的字典、数组,不可以传递 元祖
② json 最后一行末尾不可以有‘ ,’
③ json 文件总 False True 需要用 false true 来表示
④ json 中的字符串必须用英文状态下的 双引号
'''
2、dumps()/loads() dump() load()
从Python2.6开始,标准库支持JSON。使用接口dumps()将Python对象编码成JSON字符串,loads(0将JSON字符串编码成Python对象。
JSON不使用单引号,都是使用双引号分隔字符串。从网络上获取JSON格式的数据,先转换成dict,list等结构,然后再操作。一、概念理解
1、json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串)
(1)json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
(2)json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
2、json.dump()和json.load()主要用来读写json文件函数json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None,
indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
json.loads(s[, encoding[, cls[, object_hook[, parse_float[, parse_int[, parse_constant[,
object_pairs_hook[, **kw]]]]]]]])
二、代码测试
1.py
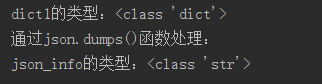
1 import json
2
3 # json.dumps()函数的使用,将字典转化为字符串
4 dict1 = {"age": "12"}
5 json_info = json.dumps(dict1)
6 print("dict1的类型:"+str(type(dict1)))
7 print("通过json.dumps()函数处理:")
8 print("json_info的类型:"+str(type(json_info)))运行截图:
2.py
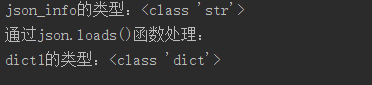
1 import json
2
3 # json.loads函数的使用,将字符串转化为字典
4 json_info = '{"age": "12"}'
5 dict1 = json.loads(json_info)
6 print("json_info的类型:"+str(type(json_info)))
7 print("通过json.dumps()函数处理:")
8 print("dict1的类型:"+str(type(dict1)))运行截图:
3.py
1 import json
2
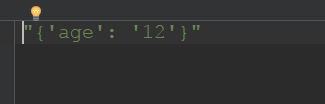
3 # json.dump()函数的使用,将json信息写进文件
4 json_info = "{'age': '12'}"
5 file = open('1.json','w',encoding='utf-8')
6 json.dump(json_info,file)运行截图(1.json文件):
4.py
1 import json
2
3 # json.load()函数的使用,将读取json信息
4 file = open('1.json','r',encoding='utf-8')
5 info = json.load(file)
6 print(info)运行截图:

二、pickle
需要注意的问题:
pickle模块支持python任意数据类型,包括对象。但是仅限于python程序间的交互。
pickle模块的读写模式都是wb、rb类型的,文件需要以wb、rb模式打开。
被pickle序列化后的文件内容不可读,但是反序列化后可以取出数据。pickle(python3.x)和cPickle(python2.x的模块)相当于java的序列化和反序列化操作。
常采用下面的方式使用:
import pickle
pickle.dump(obj,f)
pickle.dumps(obj,f)
pickle.load(f)
pickle.loads(f)使用pickle模块你可以把Python对象直接保存到文件,而不需要把他们转化为字符串,也不用底层的文件访问操作把它们写入到一
个二进制文件里。 pickle模块会创建一个python语言专用的二进制格式,你基本上不用考虑任何文件细节,它会帮你干净利落
地完成读写独享操作,唯一需要的只是一个合法的文件句柄。
pickle模块中的两个主要函数是dump()和load():
dump()函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存到给定的文件中。当我们使用load()函数从
文件中取出已保存的对象时,pickle知道如何恢复这些对象到它们本来的格式。
dumps()函数执行和dump() 函数相同的序列化。取代接受流对象并将序列化后的数据保存到磁盘文件,这个函数简单的返回序列化
的数据。
loads()函数执行和load() 函数一样的反序列化。取代接受一个流对象并去文件读取序列化后的数据,它接受包含序列化后的数据
的str对象, 直接返回的对象。实例:
# -*- coding:utf-8 -*-
import pickle
obj = 123, "abcdef", ["ac", 123], {"key": "value", "key1": "value1"}
print(obj)
# 序列化到文件
with open(r"F:\pycodes\ML\a.txt", "wb") as f:
pickle.dump(obj, f)
with open(r"F:\\pycodes\\ML\\a.txt", "rb") as f:
print(pickle.load(f))# 输出:(123, 'abcdef', ['ac', 123], {'key': 'value', 'key1': 'value1'})
# 序列化到内存(字符串格式保存),然后对象可以以任何方式处理如通过网络传输
obj1 = pickle.dumps(obj)
print(type(obj1))# 输出<class 'bytes'>
print(obj1)# 输出:python专用的存储格式 b'\x80\x03(K{X\x06\x00\x00\x00abcdefq\x00]q\x01(X\x02\x00\x00\x00acq
#\x02K{e}q\x03(X\x03\x00\x00\x00keyq\x04X\x05\x00\x00\x00valueq\x05X\x04\x00\x00\x00key1q\x
#06X\x06\x00\x00\x00value1q\x07utq\x08.'
obj2 = pickle.loads(obj1)
print(type(obj2))# 输出:<class 'tuple'>
print(obj2) # 输出:(123, 'abcdef', ['ac', 123], {'key': 'value', 'key1': 'value1'})
参考:
https://blog.youkuaiyun.com/wqx521/article/details/82772069#dumps()%2Floads() ------- Python3——JSON
https://blog.youkuaiyun.com/feng_zhiyu/article/details/82928973 -------------- Python3核心模块之pickle讲解

















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









