




目录
一、skip gram 基本实现
# 没有对FC层进行优化的 skip gram
import torch
import torch.nn.functional as F
import numpy as np
np.random.seed(1)
import pandas as pd
import torch.optim as optim
from torch.autograd import Variable, profiler
from collections import Counter
corpus = ['he is a king',
'she is a queen',
'he is a man',
'she is a woman',
'warsaw is poland capital',
'berlin is germany capital',
'paris is france capital']
# 构建 word2id 词汇表 与 id2word
words = []
for sen in corpus:
sen_words = sen.split()
for sen_word in sen_words:
if sen_word not in words:
words.append(sen_word)
word2id = {word:idx for idx,word in enumerate(words)}
id2word = {idx:word for idx,word in enumerate(words)}
print(words)
print(word2id)
print(id2word)
embedding_size = 10
window_size = 2
# 构建训练数据对(中心词onehot、上下文词index)
def train_data_generator(corpus,word2id):
for sen in corpus:
sen_index = [word2id[w] for w in sen.split()]
for cen_idx in range(len(sen_index)):
for i in range(-window_size,window_size+1): # i: -2 -1 0 1 2
context_idx = cen_idx + i
# 将上下文单词索引越界或等于中心词的索引去除
if context_idx < 0 or context_idx >= len(sen_index) or context_idx == cen_idx:
continue
cen_id = sen_index[cen_idx]
context_id = sen_index[context_idx]
# 将中心词转化为onehot格式
cen_onthot = np.zeros(len(word2id))
cen_onthot[cen_id] = 1
yield cen_onthot,cen_id,context_id
# 使用训练数据对进行训练
# 创建 w1 与 w2 矩阵参数
w1 = torch.tensor(np.random.randn(len(word2id),embedding_size)
,dtype=torch.float32,requires_grad=True)
w2 = torch.tensor(np.random.randn(embedding_size,len(word2id))
,dtype=torch.float32,requires_grad=True)
print(w1.size())
def trainer():
for epoch in range(600):
avg_loss = 0
samples = 0
for cen_onehot,_,context_id in train_data_generator(corpus,word2id):
cen_onehot = torch.from_numpy(np.array([cen_onehot])).float()
context_id = torch.from_numpy(np.array([context_id])).long()
samples += len(context_id)
# 计算
hidden_state = torch.matmul(cen_onehot,w1)
output = torch.matmul(hidden_state,w2)
# 计算 loss
output = F.log_softmax(output,dim=1)
loss = F.nll_loss(output,context_id)
loss.backward()
# 更新参数
w1.data -= 0.01 * w1.grad.data
w2.data -= 0.01 * w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
avg_loss += loss.item()
if epoch % 50 == 0:
print(avg_loss / samples)
if __name__ == "__main__":
trainer()
# 绘图
from scikitplot.decomposition import plot_pca_2d_projection
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
pca = PCA(n_components=2)
pca.fit(w1.data.numpy())
ax = plot_pca_2d_projection(pca, w1.data.numpy(), np.array(words), feature_labels=words, figsize=(12, 12),
text_fontsize=12)
# 为绘图的数据点添加txt
proj = pca.transform(w1.data.numpy())
for i, txt in enumerate(words):
ax.annotate(txt, (proj[i, 0], proj[i, 1]), size=16)
plt.show()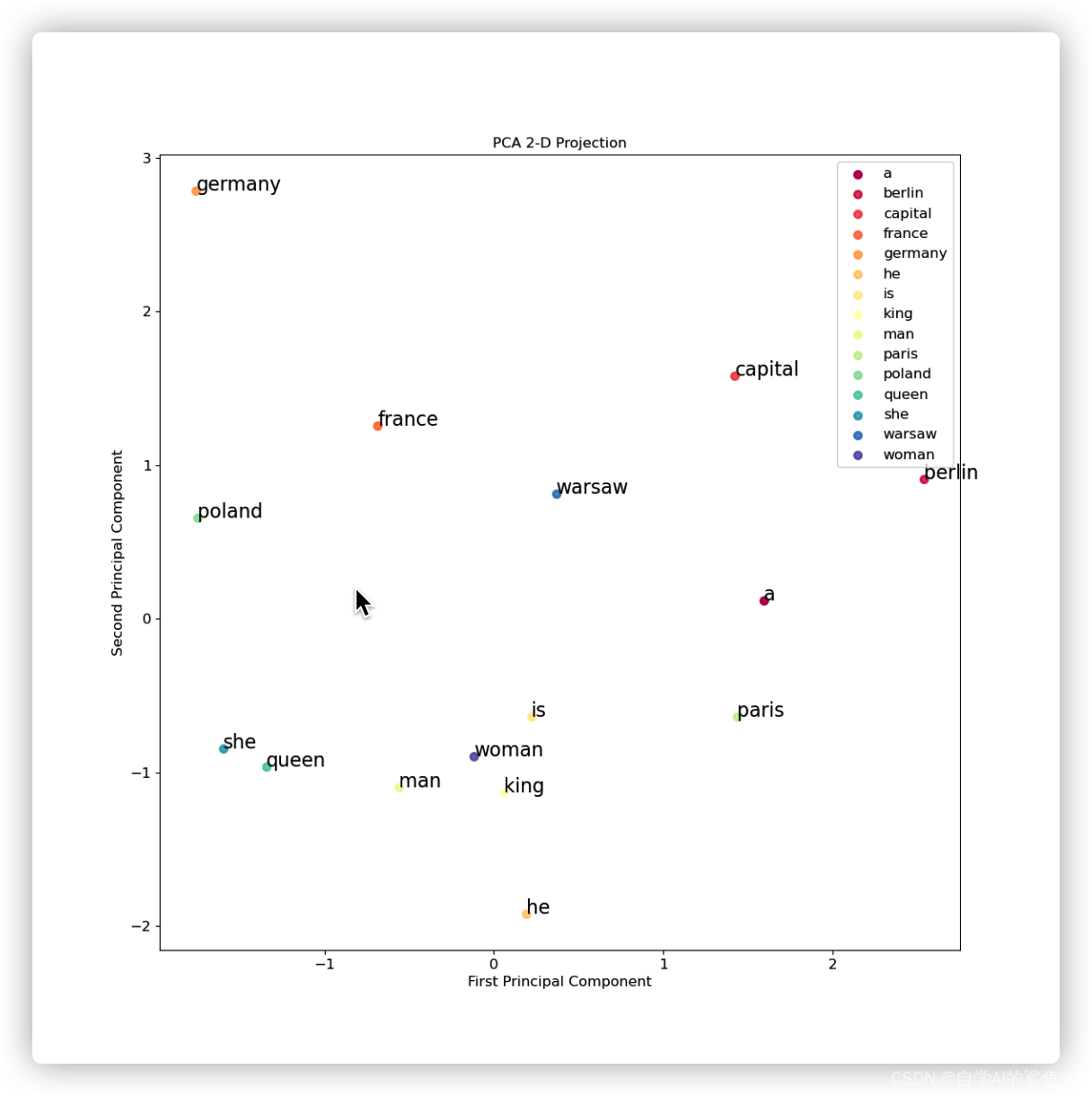
二、霍夫曼树实现
2.1、Huffman 树实现方法
# 构建霍夫曼树
# 构建霍夫曼树节点
class HuffmanNode():
def __init__(self,value,possibility):
# 节点的词频
self.possibility = possibility
# 节点的左右分支
self.left = None
self.right = None
# 节点的值
self.value = value
# 节点的Huffman编码
self.Huffman = ''
# 构建霍夫曼树
class HuffmanTree():
def __init__(self,word_dict,vector_size=10):
self.vector_size = vector_size
self.root = None
word_dict_list = list(word_dict.values())
node_list = [HuffmanNode(value=word_dict['word'],possibility=word_dict['possibility']) for word_dict in word_dict_list]
self.build_tree(node_list=node_list)
# 合并两个词频最小的节点
def merger_node(self,node1,node2):
# 计算合并后新节点的词频
possibility = node1.possibility + node2.possibility
merger_node = HuffmanNode(value=np.random.randn(self.vector_size),possibility=possibility)
# 将词频较大的节点放在左边
if node1.possibility >= node2.possibility:
merger_node.left = node1
merger_node.right = node2
else:
merger_node.left = node2
merger_node.right = node1
return merger_node
# 构建huffman树
def build_tree(self,node_list):
while node_list.__len__() > 1:
# 创建两个词频最小的节点的索引
i0 = 0 # 词频最小的节点
i1 = 1 # 词频第二小的节点
if node_list[i1].possibility < node_list[i0].possibility:
i0,i1 = i1,i0
# 找出最小的两个节点的索引
for idx in range(2,len(node_list)):
if node_list[idx].possibility < node_list[i1].possibility:
i1 = idx
if node_list[i1].possibility < node_list[i0].possibility:
i0, i1 = i1, i0
# 合并节点
merger_node = self.merger_node(node_list[i0],node_list[i1])
# 删除最小的两个节点,由于列表删除元素后会对该元素后面的元素的索引产生影响,因此我们优先从索引大的开始删起
if i1 > i0:
node_list.pop(i1)
node_list.pop(i0)
elif i0 > i1:
node_list.pop(i0)
node_list.pop(i1)
else:
raise RuntimeError('i1 不能与 i0 相等')
# 将合并的新节点加入到原列表中
node_list.insert(0,merger_node)
# 构建根节点
self.root = node_list[0]
# 计算huffman编码,TODO 利用栈遍历整个二叉树,深度优先
def generate_huffman_code(self,node,word_dict):
# 构建一个栈,深度优先遍历这个树
stack = [node]
while stack.__len__() > 0:
node = stack.pop()
# 判断节点是否为叶子节点
while node.left or node.right:
code = node.Huffman
node.left.Huffman = code + "1" # 左树词频较大的编码给1
node.right.Huffman = code + "0"
# 将右子树放入栈中
stack.append(node.right)
# 将node替换为左子树
node = node.left
word = node.value
code = node.Huffman
# 将霍夫曼编码计入词汇表的字典中
word_dict[word]['Huffman'] = code
return word_dict2.2、Huffman 优化 skip gram
import numpy as np
np.random.seed(1)
import pandas as pd
import torch.optim as optim
from torch.autograd import Variable, profiler
from collections import Counter
corpus = ['he is a king',
'she is a queen',
'he is a man',
'she is a woman',
'warsaw is poland capital',
'berlin is germany capital',
'paris is france capital']
# 构建 word2id 词汇表 与 id2word
words = []
for sen in corpus:
sen_words = sen.split()
for sen_word in sen_words:
if sen_word not in words:
words.append(sen_word)
word2id = {word:idx for idx,word in enumerate(words)}
id2word = {idx:word for idx,word in enumerate(words)}
print(words)
print(word2id)
print(id2word)
# 构建词频的字典
count_dic = {}
num_word = 0
for sen in corpus:
for word in sen.split():
if word not in count_dic:
count_dic[word] = 1
else:
count_dic[word] += 1
num_word += 1
print(count_dic)
count_dic = {word:count_dic[word] * 1.0/num_word for word in count_dic}
print(count_dic)
# 构建单词属性字典
word_dict = {}
for i,j in count_dic.items():
dic = {}
dic["word"] = i
dic['possibility'] = j
word_dict[i] = dic
print(word_dict)
# 构建霍夫曼树
# 构建霍夫曼树节点
class HuffmanNode():
def __init__(self,value,possibility):
# 节点的词频
self.possibility = possibility
# 节点的左右分支
self.left = None
self.right = None
# 节点的值
self.value = value
# 节点的Huffman编码
self.Huffman = ''
# 构建霍夫曼树
class HuffmanTree():
def __init__(self,word_dict,vector_size=10):
self.vector_size = vector_size
self.root = None
word_dict_list = list(word_dict.values())
node_list = [HuffmanNode(value=word_dict['word'],possibility=word_dict['possibility']) for word_dict in word_dict_list]
self.build_tree(node_list=node_list)
# 合并两个词频最小的节点
def merger_node(self,node1,node2):
# 计算合并后新节点的词频
possibility = node1.possibility + node2.possibility
merger_node = HuffmanNode(value=np.random.randn(self.vector_size),possibility=possibility)
# 将词频较大的节点放在左边
if node1.possibility >= node2.possibility:
merger_node.left = node1
merger_node.right = node2
else:
merger_node.left = node2
merger_node.right = node1
return merger_node
# 构建huffman树
def build_tree(self,node_list):
while node_list.__len__() > 1:
# 创建两个词频最小的节点的索引
i0 = 0 # 词频最小的节点
i1 = 1 # 词频第二小的节点
if node_list[i1].possibility < node_list[i0].possibility:
i0,i1 = i1,i0
# 找出最小的两个节点的索引
for idx in range(2,len(node_list)):
if node_list[idx].possibility < node_list[i1].possibility:
i1 = idx
if node_list[i1].possibility < node_list[i0].possibility:
i0, i1 = i1, i0
# 合并节点
merger_node = self.merger_node(node_list[i0],node_list[i1])
# 删除最小的两个节点,由于列表删除元素后会对该元素后面的元素的索引产生影响,因此我们优先从索引大的开始删起
if i1 > i0:
node_list.pop(i1)
node_list.pop(i0)
elif i0 > i1:
node_list.pop(i0)
node_list.pop(i1)
else:
raise RuntimeError('i1 不能与 i0 相等')
# 将合并的新节点加入到原列表中
node_list.insert(0,merger_node)
# 构建根节点
self.root = node_list[0]
# 计算huffman编码,TODO 利用栈遍历整个二叉树,深度优先
def generate_huffman_code(self,node,word_dict):
# 构建一个栈,深度优先遍历这个树
stack = [node]
while stack.__len__() > 0:
node = stack.pop()
# 判断节点是否为叶子节点
while node.left or node.right:
code = node.Huffman
node.left.Huffman = code + "1" # 左树词频较大的编码给1
node.right.Huffman = code + "0"
# 将右子树放入栈中
stack.append(node.right)
# 将node替换为左子树
node = node.left
word = node.value
code = node.Huffman
# 将霍夫曼编码计入词汇表的字典中
word_dict[word]['Huffman'] = code
return word_dict
if __name__ == "__main__":
vector_size = 10
huffman = HuffmanTree(word_dict=word_dict,vector_size=vector_size)
word_dict = huffman.generate_huffman_code(huffman.root,word_dict=word_dict)
print(word_dict)结果:
['he', 'is', 'a', 'king', 'she', 'queen', 'man', 'woman', 'warsaw', 'poland', 'capital', 'berlin', 'germany', 'paris', 'france']
{'he': 0, 'is': 1, 'a': 2, 'king': 3, 'she': 4, 'queen': 5, 'man': 6, 'woman': 7, 'warsaw': 8, 'poland': 9, 'capital': 10, 'berlin': 11, 'germany': 12, 'paris': 13, 'france': 14}
{0: 'he', 1: 'is', 2: 'a', 3: 'king', 4: 'she', 5: 'queen', 6: 'man', 7: 'woman', 8: 'warsaw', 9: 'poland', 10: 'capital', 11: 'berlin', 12: 'germany', 13: 'paris', 14: 'france'}
{'he': 2, 'is': 7, 'a': 4, 'king': 1, 'she': 2, 'queen': 1, 'man': 1, 'woman': 1, 'warsaw': 1, 'poland': 1, 'capital': 3, 'berlin': 1, 'germany': 1, 'paris': 1, 'france': 1}
{'he': 0.07142857142857142, 'is': 0.25, 'a': 0.14285714285714285, 'king': 0.03571428571428571, 'she': 0.07142857142857142, 'queen': 0.03571428571428571, 'man': 0.03571428571428571, 'woman': 0.03571428571428571, 'warsaw': 0.03571428571428571, 'poland': 0.03571428571428571, 'capital': 0.10714285714285714, 'berlin': 0.03571428571428571, 'germany': 0.03571428571428571, 'paris': 0.03571428571428571, 'france': 0.03571428571428571}
{'he': {'word': 'he', 'possibility': 0.07142857142857142}, 'is': {'word': 'is', 'possibility': 0.25}, 'a': {'word': 'a', 'possibility': 0.14285714285714285}, 'king': {'word': 'king', 'possibility': 0.03571428571428571}, 'she': {'word': 'she', 'possibility': 0.07142857142857142}, 'queen': {'word': 'queen', 'possibility': 0.03571428571428571}, 'man': {'word': 'man', 'possibility': 0.03571428571428571}, 'woman': {'word': 'woman', 'possibility': 0.03571428571428571}, 'warsaw': {'word': 'warsaw', 'possibility': 0.03571428571428571}, 'poland': {'word': 'poland', 'possibility': 0.03571428571428571}, 'capital': {'word': 'capital', 'possibility': 0.10714285714285714}, 'berlin': {'word': 'berlin', 'possibility': 0.03571428571428571}, 'germany': {'word': 'germany', 'possibility': 0.03571428571428571}, 'paris': {'word': 'paris', 'possibility': 0.03571428571428571}, 'france': {'word': 'france', 'possibility': 0.03571428571428571}}
{'he': {'word': 'he', 'possibility': 0.07142857142857142, 'Huffman': '1010'}, 'is': {'word': 'is', 'possibility': 0.25, 'Huffman': '01'}, 'a': {'word': 'a', 'possibility': 0.14285714285714285, 'Huffman': '110'}, 'king': {'word': 'king', 'possibility': 0.03571428571428571, 'Huffman': '10111'}, 'she': {'word': 'she', 'possibility': 0.07142857142857142, 'Huffman': '000'}, 'queen': {'word': 'queen', 'possibility': 0.03571428571428571, 'Huffman': '10110'}, 'man': {'word': 'man', 'possibility': 0.03571428571428571, 'Huffman': '10001'}, 'woman': {'word': 'woman', 'possibility': 0.03571428571428571, 'Huffman': '10000'}, 'warsaw': {'word': 'warsaw', 'possibility': 0.03571428571428571, 'Huffman': '10011'}, 'poland': {'word': 'poland', 'possibility': 0.03571428571428571, 'Huffman': '10010'}, 'capital': {'word': 'capital', 'possibility': 0.10714285714285714, 'Huffman': '001'}, 'berlin': {'word': 'berlin', 'possibility': 0.03571428571428571, 'Huffman': '11101'}, 'germany': {'word': 'germany', 'possibility': 0.03571428571428571, 'Huffman': '11100'}, 'paris': {'word': 'paris', 'possibility': 0.03571428571428571, 'Huffman': '11111'}, 'france': {'word': 'france', 'possibility': 0.03571428571428571, 'Huffman': '11110'}}

















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









