







文章目录
一 环境搭建
- 创建虚拟环境
conda create -n ArticleSpider python=3.7
conda env list # 查看存在哪些虚拟环境
activate ArticleSpider # 激活进入虚拟环境
- scrapy安装
pip install Scrapy # 安装Scrapy
scrapy startproject ArticleSpider # 创建scrapy项目 项目位置是C:\Users\userame\ArticleSpider
cd ArticleSpider
scrapy genspider cnblogs news.cnblogs.com # 要抓取的网址 二级域名
然后把C盘的项目复制粘贴到想要的地方,我这里放在D:\Code
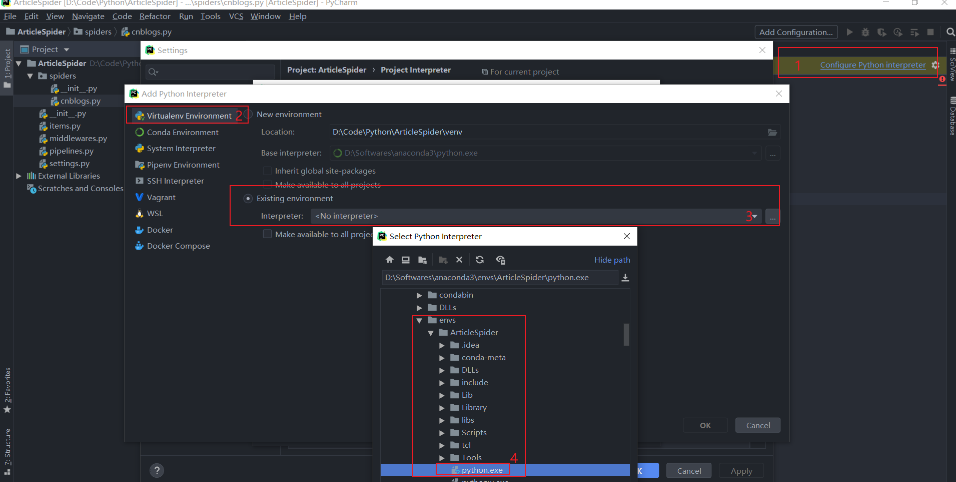
- pycharm配置使用虚拟环境
打开D:\Code里创建好的ArticleSpider项目
配置使用虚拟环境
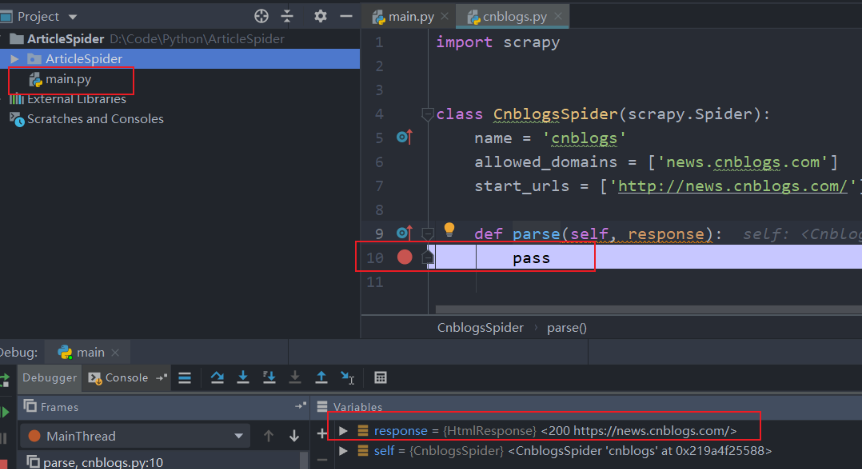
- pycharm 中调试scrapy代码
新建main.py
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__))) // 找到当前文件的绝对路径
execute(["scrapy", "crawl", "cnblogs"])
200状态码表示访问成功
二 分析与设计
2.1 需求分析
抓取博客园新闻栏目的信息
2.2 表设计
三 选择器
选择器的作用是定位所需要的信息,然后提取。
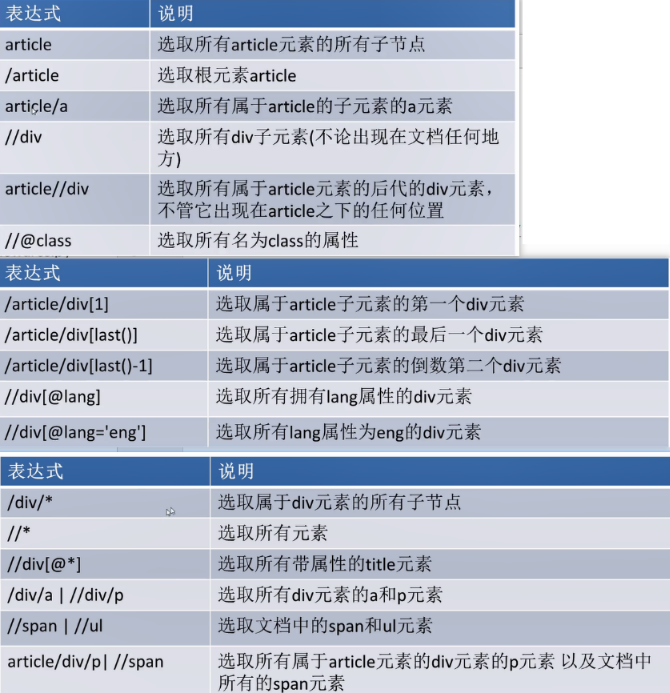
xpath选择器
简介:xpath使用路径表达式在xm和htm中进行导航
语法:
spider中使用xpath示例
博客园-新闻文章
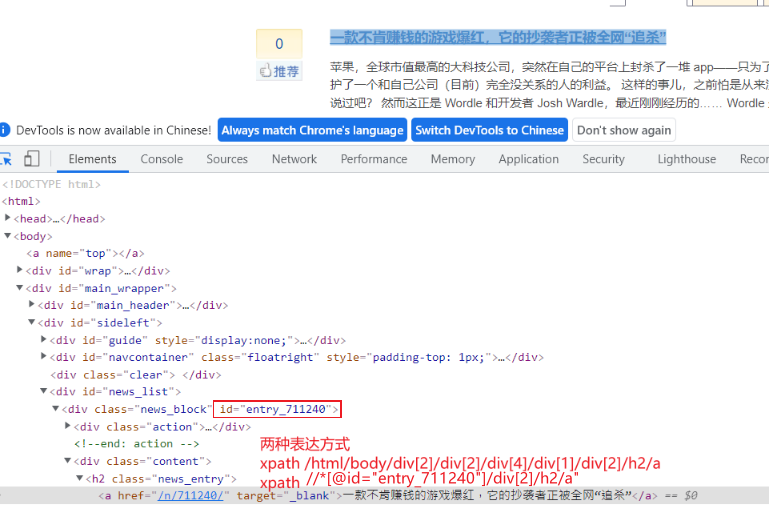
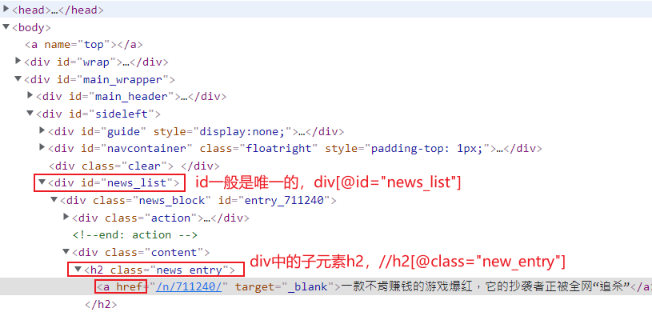
spider中提取信息 /n/711240/
url = response.xpath('//*[@id="entry_711240"]/div[2]/h2/a/@href').extract_first(""); // 提取id=entry_711240 下第二个div中h2中a标签的href属性;extract_first("")表示取第一个,不存在则赋值""空。
显然,使用这种xpath方法写法是固定死的,需要修改。
观察发现,不同文章的url是不同的,因此第一步是提取出各个文章的 /n/xxxxxx/
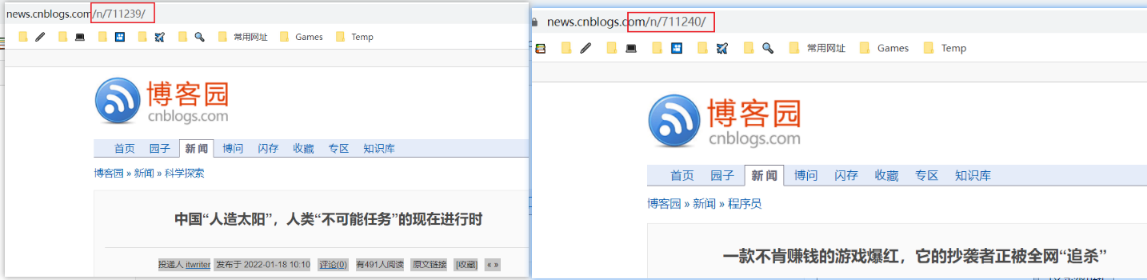
使用开发者模式观察/n/xxxxx/的位置
编写代码提取出该页面的所有 /n/xxx/ 信息列表
def parse(self, response):
url = response.xpath('//div[@id="news_list"]//h2[@class="news_entry"]/a/@href').extract()
效果图

css选择器
基本语法
spider中使用
urls = response.css('#news_list h2 a::attr(href)').extract() // # 代表id, ::取属性
当然也可以使用如下代码,效果是相同的
from scrapy import Selector
sel = Selector(text = response.text)
urls = sel.css('#news_list h2 a::attr(href)').extract()
四 编码
parse方法需要实现的功能
- 提取url,并交给scrapy下载,完成相应的解析
- 获取下一页的url,交给scrapy下载,并使用parse继续更进
4.1 封面图和文章url
观察—开发者模式查看
浏览器中关于属性的问题
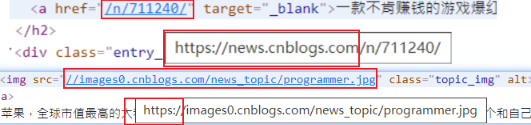
存在的问题
-
可以发现,href=‘/n/711240/’,但实际上,浏览器会自动加上它的域名。同样,src=‘//images.,’,浏览器会自动加上http。
-
但是有时候会出现 href=‘http:/baidu.com’ 这种完整链接的情况,因此我们需要处理这几种情况。
python中parse模块为我们提供了处理这种情况的简便方法。
url = parse.urljoin(response.url, post_url) # 如果post_url不是完整域名,则会从response中提取域名,然后进行组合
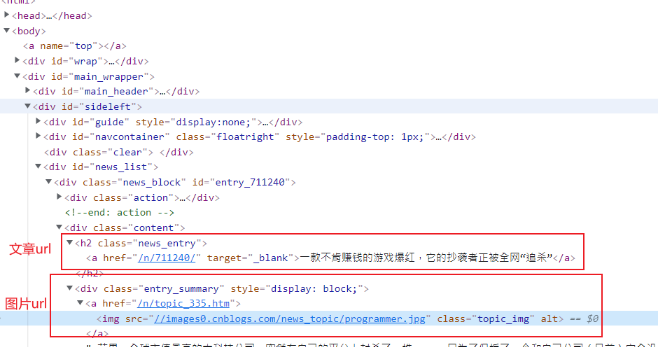
编写代码—图片和文章url
图片url分析
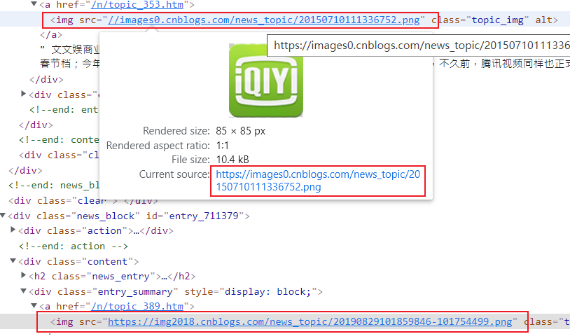
有一些图片前面没有https:,因此需要进行处理
if image_url.startswith("//"):
image_url = "https:" + image_url
post_nodes = response.css('#news_list .news_block')
for post_node in post_nodes:
image_url = post_node.css('.entry_summary a img::attr(src)').extract_first("")
post_url = post_node.css('.news_entry a::attr(href)').extract_first("")
yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url},
callback=self.parse_detail)
编写代码—获取下一页url
网页中点击next就可以跳到下一页,开发者模式查看一下next按钮的位置。

实现代码
next_url = response.xpath("//a[contains(text(), 'Next >')]/@href").extract_first("")
yield Request(url=parse.urljoin(response.url,next_url), callback=self.parse)
4.2 详情页信息
调试技巧
如果我们每提取一个信息都使用pycharm运行代码debug一下,这会造成了过多了请求,因此我们使用scrapy内附的功能进行代码调试。
进入该项目的虚拟环境以后
activate ArticleSpider # 进入虚拟环境
scrapy shell # 进入shell命令
scrapy shell https://news.cnblogs.com/n/711220/
也有可能需要登录,无法抓取到信息,此时,我们需要使用cookie和headers,因为这里是测试提取信息,所以不做模拟登录,而是直接使用cookie,在浏览器中获取到cookie,然后使用下面代码把cookie转换为字典类型。
import re
strs = '_g...'
strList = re.split(r';\S*', strs)
cookie = {}
for items in strList:
item = items.split('=')
key, value = item[0], item[1]
cookie[str(key)] = str(value) # 字典类型
print(cookie)
继续在虚拟环境中执行下面命令,把获取到的cookie代替下面cookies中的值
url_ = 'https://news.cnblogs.com/n/711220/' # 指定请求目标的 URL 链接
headers_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36', 'referer': 'https://news.cnblogs.com/'} # 自定义 Header
cookies_ = {642520268.522.415.93881', ' __utma': '66375729.537120372.1640693759.16472'}
# 构造需要附带的 Cookies 字典
req = scrapy.Request(url_, cookies=cookies_, headers=headers_) # 构造 Request 请求对象
fetch(req) # 发起 Request 请求
view(response) # 在系统默认浏览器查看请求的页面(主要为了检查是否正常爬取到内页)
信息的提取
文章的标题 css(’#news_title a::text’)

response.css("#news_title a::text").extract_first("")
发布时间 css(’#news_info .time::text’)

response.css(’#news_info .time::text’).extract_first("")
文章内容 css("#news_content")

response.css(("#news_content").extract()[0]
**文章标签 **文章标签可能是列表,因此我们不使用extract_first("")

tag_list = response.css("#news_more_info .news_tags a::text").extract()
mysql中没有存储list的,因此我们把它转换为字符串 tag = “,”.join(tag_list)
其他数据
分析——可以发现,response中是没有评论数和点赞数的
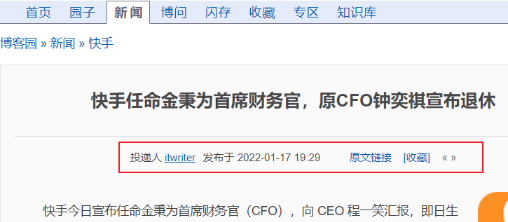
原因:在请求该页面时候通过js发出了另外带这些info的请求
解决:我们需要在它发出的请求中找到这些信息。
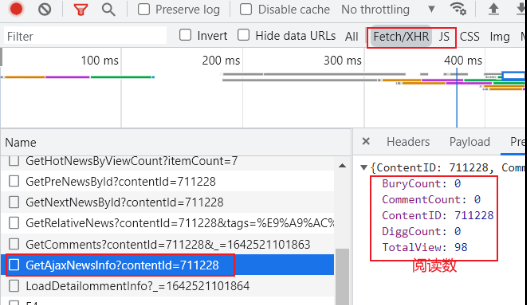
这里我们使用 requests 库中的get方法进行请求测试
虚拟环境中安装requests库
pip install requests
测试代码
scrapy shell
import requests
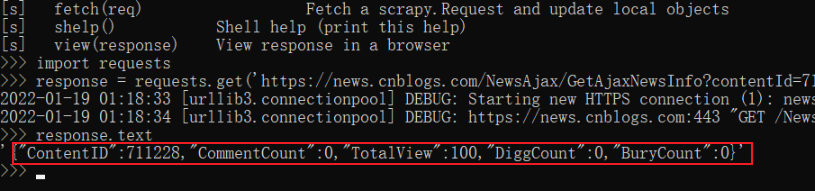
response = requests.get('https://news.cnblogs.com/NewsAjax/GetAjaxNewsInfo?contentId=711228')
response.text
效果图
把它变成json
import json
json.loads(response.text)
代码编写
抓取文章信息需要登录,此阶段我们先使用cookie进行登录
登录部分
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['news.cnblogs.com']
start_urls = ['http://news.cnblogs.com/']
cookie = {'_gid': 'GA1'}# 这里的cookie转换成字典了
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36',
'referer': 'https: // news.cnblogs.com / n / 711220 /'
}
def start_requests(self):
# 这里的url要求是字符串,因此需要转换一下
yield Request(url=''.join(self.start_urls), cookies=self.cookie, headers=self.headers, callback=self.parse)
文章基本信息及下一页信息提取
def parse(self, response):
# url = response.xpath('//div[@id="news_list"]//h2[@class="news_entry"]/a/@href').extract()
# urls = response.css('#news_list h2 a::attr(href)').extract()
# sel = Selector(text=response.text)
post_nodes = response.css('#news_list .news_block')[:1]
for post_node in post_nodes:
image_url = post_node.css('.entry_summary a img::attr(src)').extract_first("")
if image_url.startswith("//"): # 部分images是 //images/...png 需统一为https://imagegs/..png
image_url = "https:" + image_url
post_url = post_node.css('.news_entry a::attr(href)').extract_first("")
yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url},
cookies=self.cookie, headers=self.headers, callback=self.parse_detail)
#
# next_url = post_nodes.xpath("//a[contains(text(), 'Next >')]/@href").extract_first("")
# yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
每篇文章的评论数等数据的请求url是/NewsAjax/GetAjaxNewsInfo?contentId=711228。因此我们需要提取出文章的id,这里使用正则表达式提取。match_re = re.match(".*?(\d+.*)", response.url)
文章相信信息提取
def parse_detail(self, response):
match_re = re.match(".*?(\d+.*)", response.url)
if match_re:
# 标题
title = response.css("#news_title a::text").extract_first("")
# 发布时间
create_time = response.css('#news_info .time::text').extract_first("")
# 文章内容
content = response.css("#news_content").extract()[0]
# 标签列表
tag_list = tag_list = response.css("#news_more_info .news_tags a::text").extract()
tags = ",".join(tag_list) # 列表抓获为字符串
post_id = match_re.group(1).replace("/", "") # 去除 \
# print(parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)))
yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
callback=self.parse_nums)
又因为requests是同步的,因此我们改为使用Scrapy框架的Requset 来异步处理评论数点赞数等信息
评论数点赞数的处理
def parse_nums(self, response):
j_data = json.loads(response.text)
praise_nums = j_data["DiggCount"] # 收藏数
fav_nums = j_data["TotalView"] # 阅读数
comment_nums = j_data["CommentCount"] # 评论数
4.3 使用item优化
问:为什么需要item?
答:Item是保存结构数据的地方,tem提供了类字典的API,并且可以很方便的声明字段。简而言之就是可以方便存储数据。
定义item类
class CnblogsArticleItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field()
# front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()
tags = scrapy.Field()
content = scrapy.Field()
代码修改为使用item
上一步yield的front_image_url记得要拿出来,同时把item放到下一个yield的meta中
def parse_detail(self, response):
match_re = re.match(".*?(\d+.*)", response.url)
if match_re:
post_id = match_re.group(1).replace("/", "") # 去除 \
cnblogsArticleItem = CnblogsArticleItem()
# 标题
title = response.css("#news_title a::text").extract_first("")
# 发布时间
create_time = response.css('#news_info .time::text').extract_first("")
match_re = re.match(".*?(\d+.*)", create_time) # 发布于 2022-01-01
if match_re:
create_date = match_re.group(1) # 2022-01-01
# 文章内容
content = response.css("#news_content").extract()[0]
# 标签列表
tag_list = tag_list = response.css("#news_more_info .news_tags a::text").extract()
tags = ",".join(tag_list) # 列表抓获为字符串
# print(parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)))
cnblogsArticleItem["title"] = title
cnblogsArticleItem["create_date"] = create_date
cnblogsArticleItem["content"] = content
cnblogsArticleItem["tags"] = tags
cnblogsArticleItem["url"] = response.url
cnblogsArticleItem["front_image_url"] = response.meta.get("front_image_url", "") # 使用get可避免为空导致出错的情况
yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={"cnblogsArticleItem": cnblogsArticleItem}, callback=self.parse_nums)
为了生成文章的uuid,我们使用md5,放在utils.common下面
def get_md5(url):
if isinstance(url, str):
url = url.encode("utf-8")
m = hashlib.md5()
m.update(url)
return m.hexdigest()
把item yield出去,pipeline中会自动获取到item
def parse_nums(self, response):
j_data = json.loads(response.text)
praise_nums = j_data["DiggCount"] # 收藏数
fav_nums = j_data["TotalView"] # 阅读数
comment_nums = j_data["CommentCount"] # 评论数
cnblogsArticleItem = response.meta.get("cnblogsArticleItem")
cnblogsArticleItem["praise_nums"] = praise_nums
cnblogsArticleItem["comment_nums"] = comment_nums
cnblogsArticleItem["fav_nums"] = fav_nums
cnblogsArticleItem["url_object_id"] = common.get_md5(cnblogsArticleItem['url'])
yield cnblogsArticleItem
setting中 设置是否遵循爬取协议
ROBOTSTXT_OBEY = False # 不遵循
setting中 设置item_pipelines 优先速度,取消注释
ITEM_PIPELINES = {
'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
} # 数值越小,优先级越高
4.4 图片下载
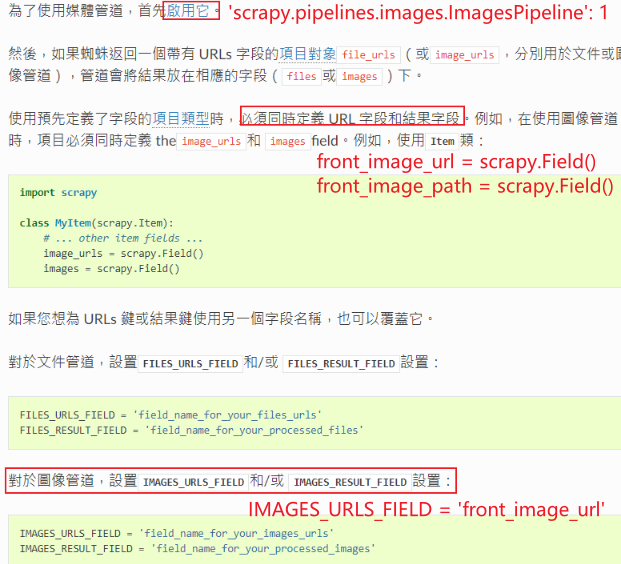
scrapy中的配置
配置pipeline可下载图片,参考官方文档:启用并设置目录—定义两个字段变量—设置images_urls_field
启用
setting.py中配置如下
project_dir = os.path.dirname(os.path.abspath(__file__))
IMAGES_STORE = os.path.join(project_dir, 'images')
设置目录为项目的images文件夹
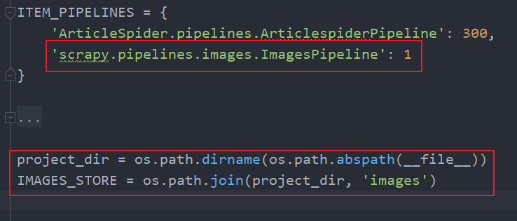
item定义两个字段
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
setting.py中设置images_urls_field
IMAGES_URLS_FIELD = 'front_image_url'
完成上述步骤后,在yield item后scrapy就会自动把front_image_url的图片下载到指定的目录(项目的images目录)
其他问题
报错:ValueError:Missing scheme in request url:h
解决:scrapy中要求图片的url的列表,因此需要 [images_url]
if response.meta.get("front_image_url", ""):
cnblogs_article_item["front_image_url"] = [response.meta.get("front_image_url", "")] # 使用get可避免为空导致出错的情况
else:
cnblogs_article_item["front_image_url"] = []
另外,scrapy下载图片还需要pillow库,没有该库时候不能下载图片且没有保持提示
pip install pillow
图片信息的获取
下载完成图片后,因为我们后期需要写入数据库,因此需要获取它的路径和文件名字。
自定义Pipeline重载item_completed方法
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
if "front_image_url" in item:
for ok, value in results:
image_file_path = value["path"]
item["front_image_path"] = image_file_path
return item
setting.py中设置使用该Pipeline
ITEM_PIPELINES = {
'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
'ArticleSpider.pipelines.ArticleImagePipeline': 1,
}
4.5 数据写入json
https://docs.scrapy.org/en/latest/topics/exporters.html
定义Pipeine—启用
自定义版
import codecs
import json
class JsonWithEncodingPipeline(object):
#自定义json文件的导出
def __init__(self):
self.file = codecs.open('article.json', 'w', encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False, default=json_serial) + "\n"
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()
setting.py中启用设置
ITEM_PIPELINES = {
'ArticleSpider.pipelines.ArticleImagePipeline': 1,
'ArticleSpider.pipelines.JsonWithEncodingPipeline': 2,
'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
}
效果图

标准版
使用官方文档的JsonItemExporter
from scrapy.exporters import JsonItemExporter
class JsonExporterPipleline(object):
#调用scrapy提供的json export导出json文件
def __init__(self):
self.file = open('articleexport.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
setting.py中启用该Pipeline
'ArticleSpider.pipelines.JsonExporterPipleline': 3,
4.6 数据写入mysql
表结构定义
CREATE TABLE `cnblog_article` (
`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`url` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`url_object_id` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`front_image_path` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`front_image_ur` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`praise_nums` int(255) NOT NULL,
`comment_nums` int(255) NULL DEFAULT NULL,
`fav_nums` int(11) NULL DEFAULT NULL,
`tags` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`content` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL,
`create_date` datetime NULL DEFAULT NULL,
PRIMARY KEY (`url_object_id`)
)
ENGINE = InnoDB
AUTO_INCREMENT = 0
AVG_ROW_LENGTH = 0
DEFAULT CHARACTER SET = utf8mb4
COLLATE = utf8mb4_general_ci
KEY_BLOCK_SIZE = 0
MAX_ROWS = 0
MIN_ROWS = 0
ROW_FORMAT = Dynamic;
安装库
pip install mysqlclient
定义Pipeline
class MysqlPipeline(object):
# 采用同步的机制写入mysql
def __init__(self):
self.conn = MySQLdb.connect('127.0.0.1', 'root', 'ya2269276', 'article_spider', charset="utf8",
use_unicode=True)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into cnblog_article(url_object_id,title, url, create_date, fav_nums, praise_nums)
VALUES (%s, %s, %s, %s, %s, %s)
"""
# self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"]))
self.cursor.execute(insert_sql, (
item.get("url_object_id", ""), item.get("title", ""), item["url"], item["create_date"], item["fav_nums"],
item["praise_nums"]))
self.conn.commit()
return item
setting.py ‘ArticleSpider.pipelines.MysqlPipeline’: 4,
异步插入
上面使用MySQLdb直接插入是同步操作,这会降低爬虫的速度,因此我们借助Twisted的api完成异步操作
from twisted.enterprise import adbapi
import MySQLdb.cursors
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) #处理异常
return item
def handle_error(self, failure, item, spider):
#处理异步插入的异常
print (failure)
def do_insert(self, cursor, item):
#执行具体的插入
#根据不同的item 构建不同的sql语句并插入到mysql中
# insert_sql, params = item.get_insert_sql() 用此方法需要在item里面添加get_insert_sql()方法
insert_sql = """ insert into cnblog_article(url, tags) VALUES (%s, %s) """
params.append(item.get("url",""))
params.append(item.get("tags",""))
cursor.execute(insert_sql, tuple(params)
setting.py中配置数据库信息
MYSQL_HOST = "127.0.0.1"
MYSQL_DBNAME = "article_spider"
MYSQL_USER = "root"
MYSQL_PASSWORD = "1111"
解决主键冲突
ON DUPLICATE KEY UPDATE :当主键存在时,我们选择更新某些字段
例如 insert into table (key, word) VALUES (%s, %s) ON DUPLICATE KEY UPDATE word=VALUES(word)
4.7 itemloader的使用
在真实开发中,我们可能有几十上百个信息要提取,这样就有很多选择器,以及数据入库时候很多字段要管理,比较混乱,因此使用itemloader统一进行管理。
信息提取部分改成使用itemloader
from scrapy.loader import ItemLoader
def parse_detail(self, response):
cnblogs_article_item = CnblogsArticleItem()
item_loader = ItemLoader(item=cnblogs_article_item, response=response)
基本使用
add_css(“field”, cssSelector)
title = response.css("#news_titlea::text").extract_first("")
cnblogs_article_item["title"] = title
# 等价于
item_loader.add_css("title", "#news_titlea::text")
add_value
item_loader.add_value("url", response.url)
# 等价于
cnblogs_article_item["url"] = response.url
疑问:extract_first("")在loader中并没有体现啊,这样会导致后面的信息处理,插入数据库都出错吧?还有有时候用的正则表达式等等。
解答:是的,loader把所有的信息都变成了list,我们统一在定义item处为这些字段添加输入前或输出后的处理方法,把它们转换为想要的格式.
修改代码如下
def parse_detail(self, response):
match_re = re.match(".*?(\d+.*)", response.url)
if match_re:
post_id = match_re.group(1).replace("/", "") # 去除 \
item_loader = ItemLoader(CnblogsArticleItem(), response=response)
item_loader.add_css("title", "#news_titlea::text")
item_loader.add_css("content", "#news_content")
item_loader.add_css("tags", "#news_more_info .news_tags a::text")
item_loader.add_css("create_date", '#news_info .time::text')
item_loader.add_value("url", response.url)
item_loader.add_value("front_image_url", response.meta.get("front_image_url", ""))
cnblogs_article_item = item_loader.load_item() # 把上面提取到的值放回到item
debug可发现,loader里面的value都是list
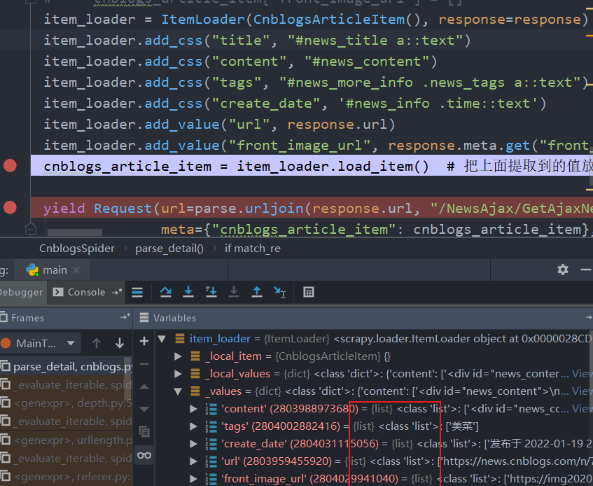
解决数据处理
上面提到,有一些数据我们需要list,有一些需要str,还有一些要做正则,我们同一在item定义里面进行处理
loader.processors的MapCompose方法
这个方法可以帮助我们都loader里面的每一个元素都执行自定义个方法。
比如,我们想让每个title的末尾都加上jojo;每个title的前面都加上test 【给MapCompose传入两个方法参数】
from scrapy.loader.processors import MapCompose
def add1(value):
return value + 'jojo'
def add2 (value):
return 'test' + value
class CnblogsArticleItem(scrapy.Item):
title = scrapy.Field(
input_processor = MapCompose(add1,add2))
测试
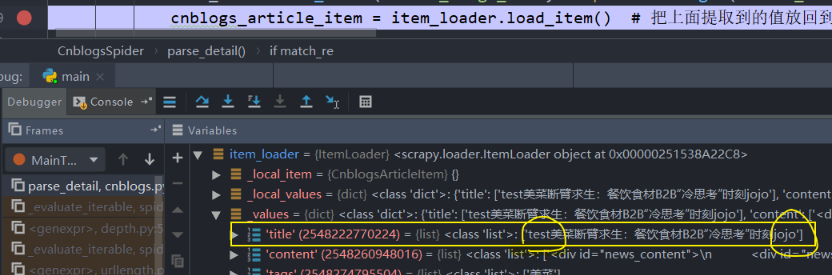
title字段我们数据库定义的是字符串,因此在操作后把list变为str。我们使用TakeFirst() 获取第一个字符串

修改代码
from scrapy.loader.processors import TakeFirst
class CnblogsArticleItem(scrapy.Item):
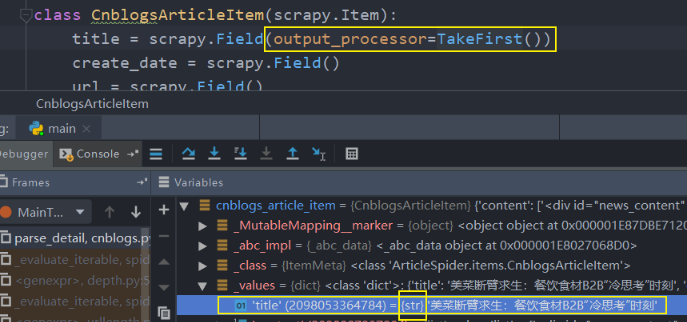
title = scrapy.Field(output_processor=TakeFirst())
效果图
日期的处理
在处理日期时候,我们使用了正则表达式提取出来
def date_convert(value):
match_re = re.match(".*?(\d+.*)", value)
if match_re:
return match_re.group(1)
else:
return "0000-00-00"
create_date = scrapy.Field(
input_processor=MapCompose(date_convert)
)
标签的处理
tags在网站上是多个a标签里面的value,使用Loader.add_css获取它们时候得到的是一个list,如果使用TakeFirst(),根据源码可知,只会return第一个标签,即后面的标签会被丢失
剩余parse代码统一使用Loader
其实也不一定全部统一的,哪种更好就用哪种,混合用也是可的
自定义ItemLoader
假设,我们的字段有很多的str类型的,一个个取output = TakeFirst()过于麻烦,因此我们自定义一个itemloader,它继承原来提供的类,但是我们设置它默认输出的时候自动调用TakeFirst() 就可以达到目的了
from scrapy.loader import ItemLoader
class ArticleItemLoader(ItemLoader):
# 自定义itemloader
default_output_processor = TakeFirst()
实例化时候使用自定义的Loader
def parse_detail(self, response):
item_loader = ArticleItemLoader(CnblogsArticleItem(), response=response)
但是,这又出现了一个问题,之前提到过,是大部分字段是str,但不是全部,因为自定义的loader默认输出时候自动调用takefirst(),因此所有字段都变成了str。故应在不需要str的字段进行设置不调用takefirst()
from scrapy.loader.processors import Identity
front_image_url = scrapy.Field(output_processor=Identity())
如果使用insert_sql, params = item.get_insert_sql()来化简sql语句,item需要添加get_insert_sql方法
class CnblogsArticleItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field(input_processor=MapCompose(date_convert))
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field(output_processor=Identity())
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()
tags = scrapy.Field(output_processor=Join(separator=","))
content = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into cnblog_article
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE fav_nums=VALUES(fav_nums)
"""
params = (
self.get("title", ""),
self.get("url", ""),
self.get("url_object_id", ""),
self.get("front_image_path", ""),
self.get("front_image_url", ""),
self.get("parise_nums", 0),
self.get("comment_nums", 0),
self.get("fav_nums", 0),
self.get("tags", ""),
self.get("content", ""),
self.get("create_date", "0000-00-00"),
)
return insert_sql, params
一些警告
ScrapyDeprecationWarning: scrapy.loader.processors.TakeFirst is deprecated, instantiate itemloaders.processors.TakeFirst instead.
default_output_processor = TakeFirst()
from itemloaders.processors import TakeFirst, MapCompose, Join, Identity
五 总结
虚拟环境的搭建、使用shell调试技巧、使用cookie登录、评论点赞收藏数的获取、主键冲突处理、使用Twisted异步数据库插入

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









