







AI大模型学习地图
技术词扫盲
-
机器学习(Machine Learning,ML),是一种广泛的人工智能(AI)技术,它使计算机能够从数据中学习并做出预测或决策,而不需要明确的编程。机器学习算法可以分为监督学习、无监督学习和强化学习等几类。
-
数据挖掘(Data Mining,DM),从大量数据中提取有用信息的过程,它可以通过各种技术来实现,如聚类、分类、关联规则挖掘等。而机器学习则是让计算机自动学习数据中的模式和规律,以便能够做出预测和决策。
在实际应用中,机器学习和数据挖掘通常会相互结合,以解决各种问题。例如,数据挖掘可以用来发现数据中的异常点和噪声,以便在机器学习模型中进行更准确的预测。同时,机器学习可以用来优化数据挖掘的过程,比如通过自动化特征选择和模型选择来提高数据挖掘的效率和准确性。 -
深度学习(Deep Learning,DL),是机器学习的一种特殊形式,它使用多层神经网络来模拟人脑的神经网络结构,以实现对复杂数据的高级抽象和处理。深度学习的主要特点是能够处理大量数据和高维数据,并且可以自动学习特征和模型。
-
大语言模型(Large Language Model,LLM),是机器学习的一个子领域,它使用深度学习技术来处理和生成自然语言。
-
自然语言处理(Natural Language Processing,NLP),是大语言模型的一个重要应用。 NLP 是一种使计算机能够理解、解释和生成人类语言的技术。大语言模型在 NLP 中的应用包括机器翻译、文本摘要、情感分析、问答系统等。
-
神经网络(Neural network,NNs),也称为人工神经网络(Artificial Neural Network,ANNs),在机器学习和认知科学领域,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。
不同类型的神经网络都是专为解决特定问题而设计。它们通常按照数据从输入节点流向输出节点的方式进行分类。一些最常见的神经网络类型包括:- 前馈神经网络
一种最简单的神经网络,由输入层、隐藏层和输出层组成。信息只朝一个方向流动,即从输入节点流向输出节点。前馈神经网络使用反馈过程,可随着时间的推移不断改进预测,通常用于分类和回归等任务,以及计算机视觉、自然语言处理 (NLP) 和面部识别等技术中。 - 卷积神经网络 (CNN)
CNN 特别适用于对图像和视频进行识别、分类和分析。它们依靠大量卷积层作为筛选器来检测数据中的局部模式和层次结构。 - 反卷积神经网络 (DNN)
反卷积神经网络广泛用于图像合成和分析,是 CNN 的反向执行过程。它们能够检测到原本可能被 CNN 认为不重要的丢失的特征或信号。 - 循环神经网络 (RNN)
RNN 是一种更复杂的神经网络,专为处理序列数据而设计,通常使用时间序列数据来预测未来的结果。它们具有反馈连接,允许信息循环流动,从而能够保留过去输入的记忆并处理可变长度序列。自学习系统经常用于股市预测、销售预测和文本到语音的转换。 - 长短期记忆网络 (LSTM)
LSTM 网络是一种特殊类型的 RNN,可以有效处理序列数据中的长期依赖关系。它们通过添加一个可以将信息存储更长时间的存储单元,缓解与传统 RNN 相关的梯度消失问题。LSTM 通常用于手势和语音识别以及文本预测。 - Transformer,是一种基于自注意力机制的神经网络结构,主要用于处理序列数据。它不需要像LSTM一样使用循环结构,可以并行计算,从而提高了计算效率。Transformer的核心是多头自注意力机制,可以在输入序列中寻找相关性,从而更好地处理长序列数据。
- 前馈神经网络
-
检索增强生成(Retrieval-Augmented Generation,RAG),RAG 是一种混合架构,它结合了预训练的语言模型和基于检索的知识库来提高生成质量。对于特定查询,系统会先利用高效的索引机制从大型语料库中找到最相关的片段作为上下文输入给解码器部分。
AI推理和AI训练的区别
大模型流程:预训练(Pre-training,通用表示)→ 监督微调(Fine-tuning,任务适配)→ 推理(Inference,实际应用)。

其他几个概念:
-
监督学习(Supervised Learning)和无监督学习(Unsupervised Learning),机器学习的两大主要类型。监督学习应该是指有标签的数据,模型通过学习输入和输出之间的映射关系,比如分类和回归任务。而无监督学习是没有标签的数据,模型需要发现数据中的结构,比如聚类或者降维。这部分应该是对的。
-
自编码(Autoencoding)和自回归(Autoregressive),自编码器(Autoencoder)是一种无监督学习模型,用于数据压缩和特征学习,通过编码器和解码器结构,学习重构输入数据。而自回归模型(如ARIMA)在时间序列中常见,或者像GPT这样的模型,每次预测下一个词,基于之前的词。所以自回归应该是利用过去的信息预测未来的数据点,逐个生成。
监督微调 (Supervised Fine-Tuning,SFT)-> 强化学习(Reinforcement Learning,RL)分阶段训练:
-
Step 1 - 监督微调(SFT):
使用人工编写的对话数据,教模型基本的问答能力(如“如何做蛋糕?”→ 详细步骤)。 -
Step 2 - 奖励模型训练(RM):
让模型生成多个答案,人工标注答案质量排序 → 训练一个能自动打分的奖励模型。 -
Step 3 - 强化学习(RLHF):
用奖励模型作为“裁判”,通过PPO算法优化模型,使其生成更高分的回答(如更简洁、安全、符合逻辑)。
下图是深度学习模型的全生命周期图,主要分为两大类任务,训练任务和推理任务。

训练任务:
- AI训练的目标则是通过大量数据和算法,优化模型,使其能够更好地进行预测和决策。
- 训练过程通过设计合适的 AI 模型以及损失函数、优化算法等,前向传播并计算损失函数,反向计算梯度,利用优化函数来更新模型,最终目标是使损失函数最小。
- 通常需要执行数小时、数天,一般配置较大的 batch size 以实现较大的吞吐量,训练模型直到指定的准确度或错误率。
推理任务:
- AI推理的目标是根据给定条件,推断出未知信息。例如,在自动驾驶领域,AI推理可以帮助车辆判断前方道路的情况,并做出相应的行驶决策。
- 推理过程是在训练好的模型上,进行一次前向传播得到输出,最终目标是将模型部署在生产环境中。
- 执行 7 x 24 小时服务,此时模型已稳定无需训练,服务于真实数据进行推理预测,一般 batch size 较小。
神经网络的工作原理
神经网络的工作过程称为前向传播。通过一种受人类大脑启发的架构,输入数据逐层通过网络进行传递,以生成输出。神经网络中有多层节点,节点是一组定义好的输入、权重和函数。一层中的每个神经元接收上一层的输入,对每个输入施加一个权重,然后将加权和传递给一个激活函数。激活函数的输出将成为下一层的输入。
在训练期间,神经网络会调整权重,以尽可能减小预测输出与实际输出之间的差异。这一过程称为反向传播,会使用优化算法来更新权重并提升网络性能。通过试错的过程,可让它从错误中学习经验,并随着时间的推移提高准确性。最终,神经网络可以准确预测它从未遇到过的数据。
一个基本的神经网络由三层相互关联的神经元组成:
- 输入层:信息从输入层进入神经网络;然后,输入节点对数据进行处理和分析,并传递给下一层。
- 隐藏层:隐藏层从输入层或其他隐藏层获取输入,对来自上一层的输出进行分析和处理,并传递给下一层。
- 输出层:输出层生成最终结果,可以有单个或多个节点。
较大的深度学习网络会有许多隐藏层,其中有数百万个相互关联的神经元。
LLM推理任务
训练好的大模型在计算设备上部署完毕后,当用户推理请求到达后,用户数据会进行一些预处理,包括文本分割和归一化等。处理后的数据喂给大模型后,模型进行prefill和decode两个阶段迭代生成输出。紧接着对推理的结果进行后处理,对模型的输出进行解析和转换,使其成为用户可以理解的格式。
LLM 推理阶段
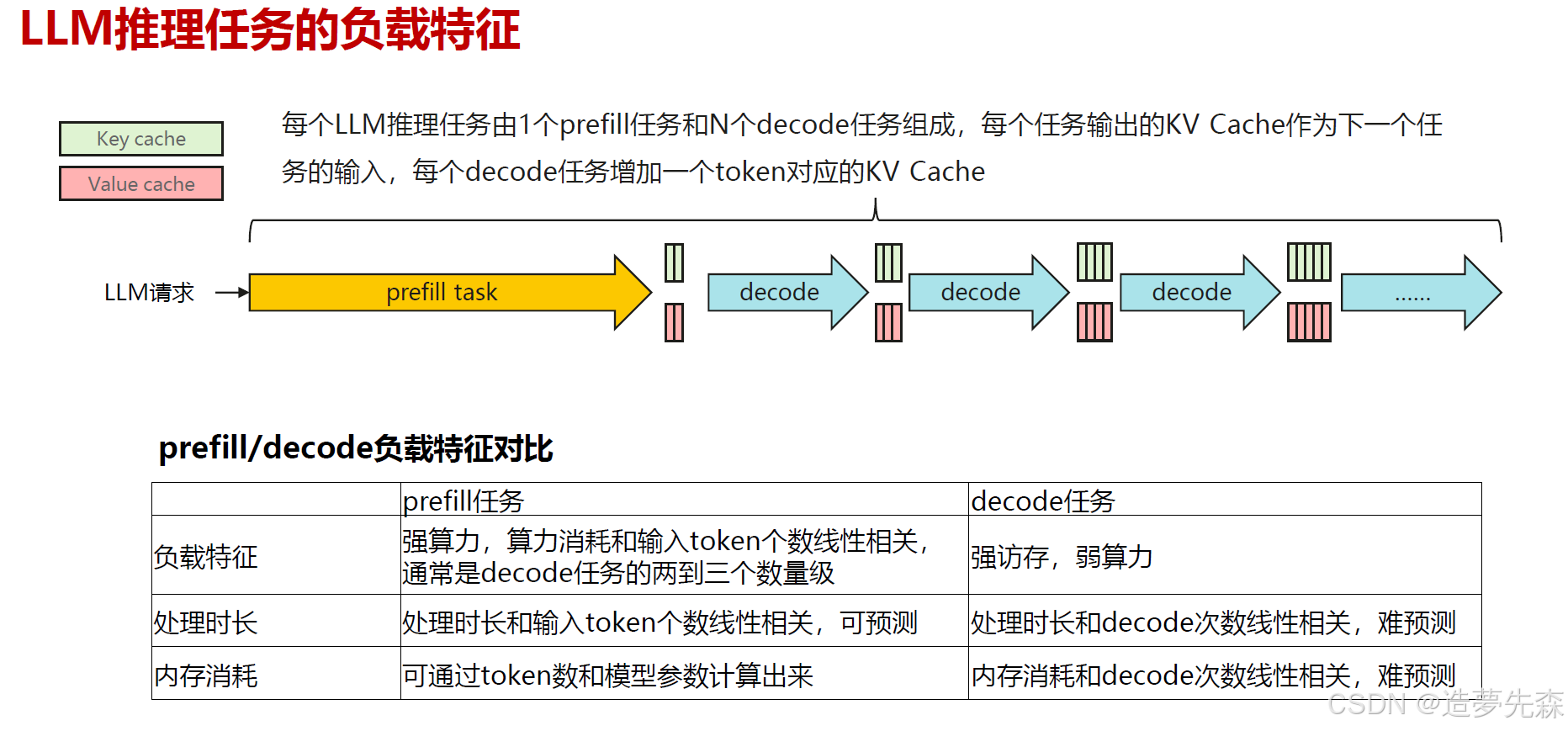
- prefill阶段: 发生在计算第一个输出token的过程中。输入的token进行前向传播计算并保存key cache和value cache,在输出token时完成KVCache的填充。在prefill的过程中存在大量矩阵与矩阵(MM, Matrix-Matrix)运算,属于compute-bound过程。
- decode阶段: 发生在计算第二个输出token到最后一个输出token的迭代生成过程中。在每轮推理中,将KVCache中的数据取出,并与上一轮推理的输出token的计算出的新的key值和Value值进行拼接更新KVCache。在这个过程中,已存代算,矩阵与矩阵运算降为矩阵与向量(MV, Matrix-Vector)运算,但KVCache涉及读写操作,属于memory-bound过程
让我们以 Llama2-7B(4096 序列长度,float16精度)为例,计算一下 batch_size = 1的理想推理速度(prompt是指输入到模型中的一段文本,而token则是指文本中的一个单词或符号)
- prefill:假设 prompt 的长度是 350 token,那么预填充所需要的时间 = number of tokens * ( number of parameters / accelerator compute bandwidth) = 350 * (2 * 7B) FLOP / 125 TFLOP/s = 39 ms(A10)。这个阶段主要是计算瓶颈。
- decoding:time/token = total number of bytes moved (the model weights) / accelerator memory bandwidth = (2 * 7B) bytes / (600 GB/s) = 23 ms/token(A10)。这个阶段的瓶颈是带宽。
LLM 推理的核心指标
想要优化 LLM 推理,首先要了解 LLM 推理的核心指标。
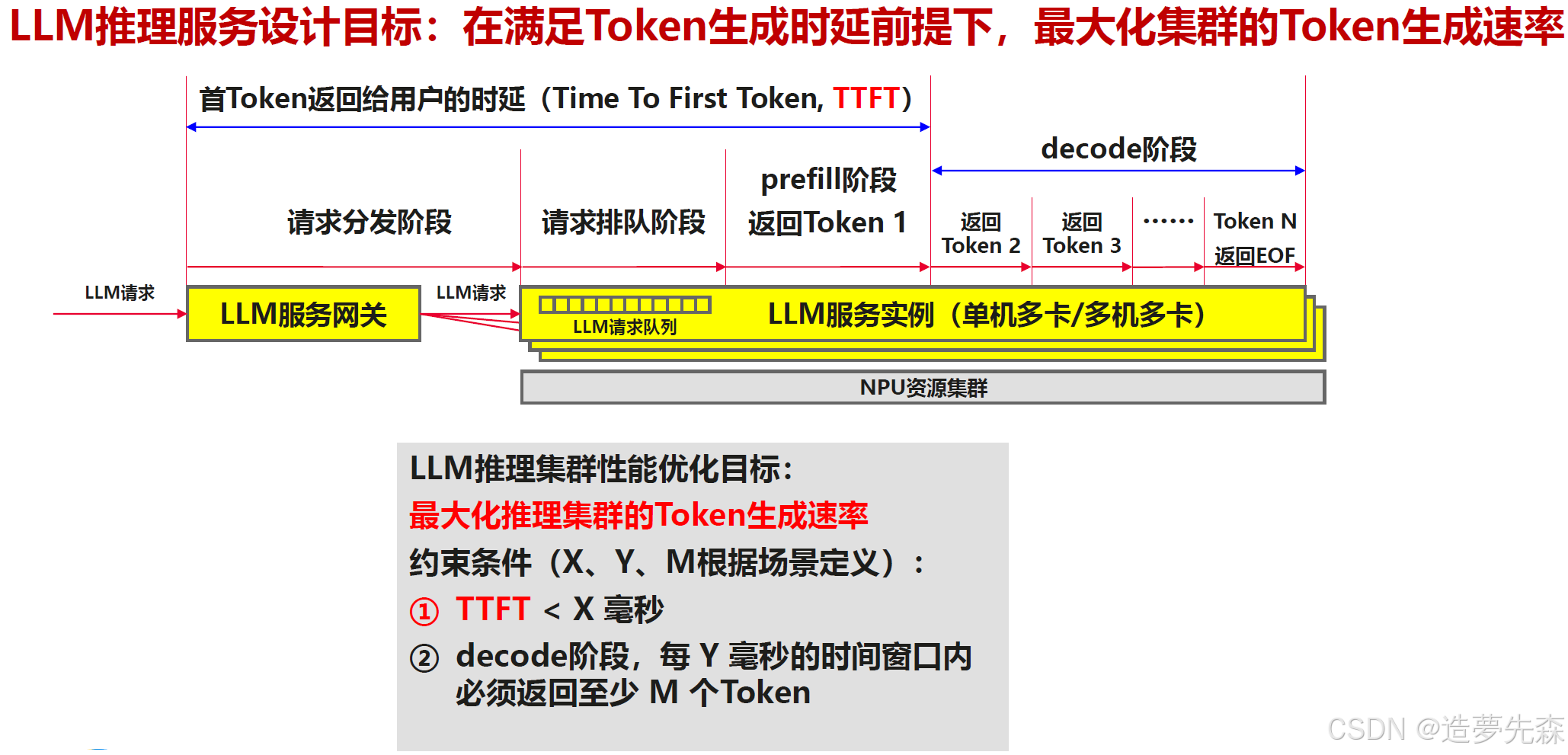
- Time To First Token (TTFT): 首 Token 延迟,即从输入到输出第一个 token 的延迟。在在线的流式应用中,TTFT 是最重要的指标,因为它决定了用户体验。
Time Per Output Token (TPOT): 每个输出 token 的延迟(不含首个Token)。在离线的批处理应用中,TPOT 是最重要的指标,因为它决定了整个推理过程的时间。 - Latency:延迟,即从输入到输出最后一个 token 的延迟。 Latency = (TTFT) + (TPOT) * (the number of tokens to be generated). Latency 可以转换为 Tokens Per Second (TPS):TPS = (the number of tokens to be generated) / Latency。
- Throughput:吞吐量,即每秒针对所有请求生成的 token 数。以上三个指标都针对单个请求,而吞吐量是针对所有并发请求的。
我们将 LLM 应用分为两种:
- 在线流式应用:对 TTFT、TPOT、Latency 敏感,需要尽可能快的生成 token。
- 离线批量应用:对 Throughput 敏感,需要在单位时间内尽可能多的生成 token。
而实际在某种应用(如在线流式应用),我们也应该在Latency 和 Throughput 之间进行权衡,提高 Throughtput 可以提高单个 GPU 承担的并发数,从而降低推理成本。
参考:
https://github.com/ninehills/llm-inference-benchmark/blob/main/LLM%E6%8E%A8%E7%90%86%E4%BC%98%E5%8C%96.md
https://zhuanlan.zhihu.com/p/630832593
https://www.showmeai.tech/tutorials/77
https://blog.youkuaiyun.com/weixin_45651194/article/details/132872588




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











