




 本文详细介绍了如何使用darknet框架中的YOLOv3模型,针对自定义数据集进行训练和预测。包括下载darknet源码、修改配置文件、准备数据集、训练模型、批量输出txt和jpg格式的预测结果,以及计算mAP值的过程。
本文详细介绍了如何使用darknet框架中的YOLOv3模型,针对自定义数据集进行训练和预测。包括下载darknet源码、修改配置文件、准备数据集、训练模型、批量输出txt和jpg格式的预测结果,以及计算mAP值的过程。
Reference
https://pjreddie.com/darknet/yolo/
https://blog.youkuaiyun.com/weixin_42731241/article/details/81352013
https://blog.youkuaiyun.com/mieleizhi0522/article/details/79989754
https://blog.youkuaiyun.com/yinhuan1649/article/details/82258703
目录
7. 修改./darknet/data/voc.name文件
8. 修改./darknet/cfg/yolov3-voc.cfg文件
3. 修改./darknet/cfg/yolov3-voc.cfg文件
2. 修改./darknet/example/detector.c文件
★训练阶段★
1. 下载darknet源码
在命令窗口(terminal)中进入你想存放darknet源码的路径,然后在该路径下输入依次输入以下命令:
git clone https://github.com/pjreddie/darknet
cd darknet上述命令首先从darknet的源码地址复制一份源码到本地,下载下来的是一个名为darknet的文件。然后进入这个名为darknet的文件夹。
2. 修改darknet的Makefile文件
Note:如果不需要darknet在GPU上运行,则略过此步骤,只需执行make命令。
在命令窗口输入以下命令打开Makefile文件:
vi Makefile将Makefile文件开头的GPU=0改为GPU=1,如下所示:
GPU=1
CUDNN=0
OPENCV=0
OPENMP=0
DEBUG=0修改完之后,需要执行make命令才可以生效。
make3. 准备数据集
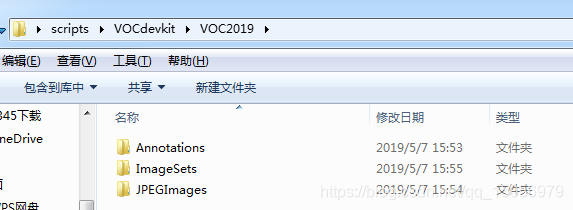
在./darknet/scripts文件夹下创建文件夹,命名为VOCdevkit,然后再在VOCdevkit文件夹下创建一系列文件夹,整个目录结构如下所示:
VOCdevkit
-VOC2019 # 这个文件夹的年份可以自己取
--Annotations # 在这个文件夹下存放所有的xml文件
--ImageSets
---Main # 在这个文件夹下新建两个TXT文件
----train.txt
----val.txt
--JPEGImages # 在这个文件夹下存放所有的图片文件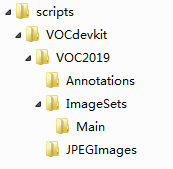
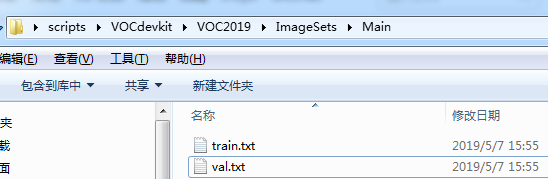
上述文件及文件夹创建好之后,下面来对我们的数据集生成train.txt和val.txt,这两个文件中存放训练图像和测试图像的文件名(不含.jpg后缀)。
新建一个create_txt.py文件(名字可以自己随便取),然后将以下代码复制进去(注意相应路径的修改)
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/darknet/scripts/VOCdevkit/VOC2019/JPEGImages/' # 修改为自己的路径
dest='/home/darknet/scripts/VOCdevkit/VOC2019/ImageSets/Main/train.txt' # 修改为自己的路径
dest2='/home/darknet/scripts/VOCdevkit/VOC2019/ImageSets/Main/val.txt' # 修改为自己的路径
file_list=os.listdir(source_folder)
train_file=open(dest,'a')
val_file=open(dest2,'a')
count = 0
for file_obj in file_list:
count += 1
file_name,file_extend=os.path.splitext(file_obj)
if(count<800): # 可以修改这个数字,这个数字用来控制训练集合验证集的分割情况
train_file.write(file_name+'\n')
else :
val_file.write(file_name+'\n')
train_file.close()
val_file.close()
制作好create_txt.py文件后,在命令行执行该文件:
python create_txt.py执行完毕之后可以看到刚刚我们新建的train.txt和val.txt文件中被写进了我们的数据集图片的文件名。
4. 修改voc_label.py
打开scripts文件夹下的 voc_label.py 文件,修改以下信息:
sets=[('2019', 'train'), ('2019', 'val')] # 此处的2019对应前面新建文件夹时的2019,train和val对应两个TXT文件的文件名
classes = ["car", "people"] # 此处为数据集的类别名称,一定要与xml文件中的类别名称一致,有几类就写几类
os.system("cat 2019_train.txt 2019_val.txt > train.txt") # 此处是将两个txt连接成一个txt,如果你训练时不用val.txt中的数据,可以注释掉这句话。
# 另外,删除另外一条os.system(...)语句。 保存修改后,运行该文件:
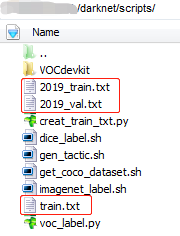
python voc_label.py执行完毕之后,会生成2019_train.txt、2019_val.txt、train.txt 三个文件,如下图:
5. 下载预训练模型
为了加速训练过程,可以在darknet官网上下载预训练模型,在该预训练模型上再进行训练。
在命令窗口输入以下命令:
wget https://pjreddie.com/media/files/darknet53.conv.74
下载过程可能非常慢,可以在网盘中下载:链接:https://pan.baidu.com/s/1HImtoeaYnk0u8540yXn2yw 提取码:pyhl
下载完之后,将该文件放在 ./darknet 目录下。
6. 修改./darknet/cfg/voc.data文件
将voc.data 文件做如下修改:
classes= 2 # 你的数据集的类别数
train = /darknet/scripts/2019_train.txt # 第4步中生成的txt文件路径
valid = /darknet/scripts/2019_val.txt # 第4步中生成的txt文件路径
names = data/voc.names
backup = backup7. 修改./darknet/data/voc.name文件
将voc.name文件做如下修改:
car
people内容为你的数据集的类别名称,注意和xml文件中的类别名称一致。
8. 修改./darknet/cfg/yolov3-voc.cfg文件
该文件为网络结构文件。
首先修改开头处如下:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16即,将训练模式打开,将测试模式的语句注释掉。
其中subdivisions为将一个batch(此处为64)分成多大的小batch。如果训练时提示超出内存,则可以相应的改小这两个参数的值。
接着视情况修改开头处的超参数(学习率,迭代次数等):
wi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 557
557






 到【灌水乐园】发言
到【灌水乐园】发言







