







开源代码
https://gitee.com/qq874455953/cleanlab_nlp_keras/
目前可能是数据集选的不好, 数据集本身没什么噪声 所以有点小问题 不过总体框架是搭建起来的
前言
在做一个项目的时候,发现数据集噪声非常多,项目是是一个文本分类问题, 但是数据集中经常出现 label 错误的情况, 也就是所谓的
label noise问题,在这样的数据集对模型进行训练效果非常差。关于label noise感兴趣可以看 Noisy Label 20 篇论文纵览 ,也是一个研究的热门方向,且对于工业界意义很大。
笔者在经过一些相关的调研之后, 从实现难度,教程数量, 原理理解这些方面角度,最终选取置信学习这种方式对数据集合进行去噪
置信学习相关介绍
那什么是置信学习呢?这个概念来自一篇由MIT和Google联合提出的paper:《Confident Learning: Estimating Uncertainty in Dataset Labels[1] 》。论文提出的置信学习(confident learning,CL)是一种新兴的、具有原则性的框架,以识别标签错误、表征标签噪声并应用于带噪学习(noisy label learning)
置信学习主要包括3个部分
- Count:估计噪声标签和真实标签的联合分布
- Clean:找出并过滤掉错误样本
- Re-training:过滤错误样本后,重新训练
其中count 阶段
-
可以理解为 找到 可能是噪声的集合,
-
如何判断是否可能为噪声 则是根据是否大于平均概率得到的,
-
平均概率则是所有label 为class a 的平均概率
例子:
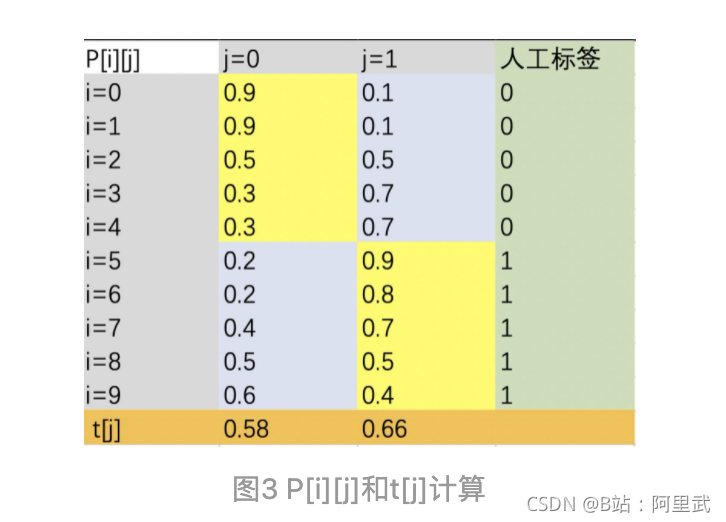
类别0的平均概率则是mean([0.9 , 0.9, 0.5, 0.3, 0.3])
所以我们进行置信学习 需要的有
- 每个样本在每个类别的概率 —> count 阶段用
- 每个样本实际属于哪个类别 —> count 阶段用
Clean阶段则是
- 对于Count 阶段得到的 不可信集合中 以一定的策略进行可信度排序
- 然后根据顺序取出最不可信的样本
- 文章给了5种策略 感兴趣可以阅读https://zhuanlan.zhihu.com/p/146557232 这个作者的例子举的很好
置信学习开源工具:cleanlab
作者对这个置信学习框架进行了开源, 地址如下
https://github.com/cgnorthcutt/cleanlab
文档地址如下:
https://l7.curtisnorthcutt.com/cleanlab-python-package
我们就是通过cleanlab 工具 对带躁数据集合进行去噪声
实战
鉴于网上都没有给出完整的一个置信学习流程, 而且有的话也是非常简略, 什么参数都不告诉你怎么来的,特别是基于tensorflow pytorch kears 深度学习框架 则是完全没有,唯一的一个详细的教程竟然需要收费。 作者靠着自己的摸索,给出一个相对完整的教程,一起相互需学习。本文是使用keras 搭建的神经网络模型
如何去噪
官方原话: 我们使用cheanlab。只需要一行代码即可对数据进行去噪
这一行代码如下
# Compute psx (n x m matrix of predicted probabilities)
# in your favorite framework on your own first, with any classifier.
# Be sure to compute psx in an out-of-sample way (e.g. cross-validation)
# Label errors are ordered by likelihood of being an error.
# First index in the output list is the most likely error.
from cleanlab.pruning import get_noise_indices
ordered_label_errors = get_noise_indices(
s=numpy_array_of_noisy_labels,
psx=numpy_array_of_predicted_probabilities,
sorted_index_method='normalized_margin', # Orders label errors
)
numpy_array_of_noisy_labels : 每个样本实际属于哪个类别
numpy_array_of_predicted_probabilities: 模型预测每个样本在每个类别的概率
sorted_index_method: 选择是否是噪声数据的策略
1. 安装cleanlab
Pip install cleanlab
2. 计算概率
这里就学问大了, 如何计算每个样本的概率呢, 原文的说法是进行K轮交叉验证
K轮交叉验证的具体意思则是
- 把数据分为K份(这里我使用的是5。最好大于5)
- 其中选一份为测试集, 其余K-1份为 训练集,训练一个模型
- 把测试集 输入 训练的模型, 得到测试集每个样本的预测每个类的概率 得到我们需要的 每个样本在每个类别的概率
- 测试集 每个样本 自身的label 则是 每个样本实际属于哪个类别
这样通过K轮交叉验证 我们得到了工具包所需的所有参数,具体怎么做可以看我开源的工程
BERT + mulit-CNN -> 文本分类
3. 调工具包得到 噪声数据位置
# Compute psx (n x m matrix of predicted probabilities)
# in your favorite framework on your own first, with any classifier.
# Be sure to compute psx in an out-of-sample way (e.g. cross-validation)
# Label errors are ordered by likelihood of being an error.
# First index in the output list is the most likely error.
from cleanlab.pruning import get_noise_indices
ordered_label_errors = get_noise_indices(
s=numpy_array_of_noisy_labels,
psx=numpy_array_of_predicted_probabilities,
sorted_index_method='normalized_margin', # Orders label errors
)
4. 去除噪声数据
在上一步训练的过程中我们得到 ordered_label_errors
也就是 所有不可信数据的置信排序, 最不可信到最可信
然后我们则可以对验证集合进行遍历, 如果index 在这个 ordered_label_errors里面 , 说明这个index 的数据是噪声数据
我们取出,否则保留, 得到这一份验证集的去噪版本
重复K次, 把每一份验证集的去噪声版本进行合并则得到我们最终的去噪数据集

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









