







Multimodal First Impression Analysis with Deep Residual Networks
前言
这篇文章也算是一个老文章了,不过效果也非常好,准确率也在前三名之内,有必要读读它的模型结构以及特征方法,特别是他对于声音提取的方面好像有一些小创新,虽然是两个模块,但也有借鉴意义,
模型结构
以下是整个模型的一个流程图,通过,训练集进行训练得到一个模型,然后把被测试者的视频输入到模型中,得到它的个性分数以及是否是一个好的面试者(通过还是不通过)
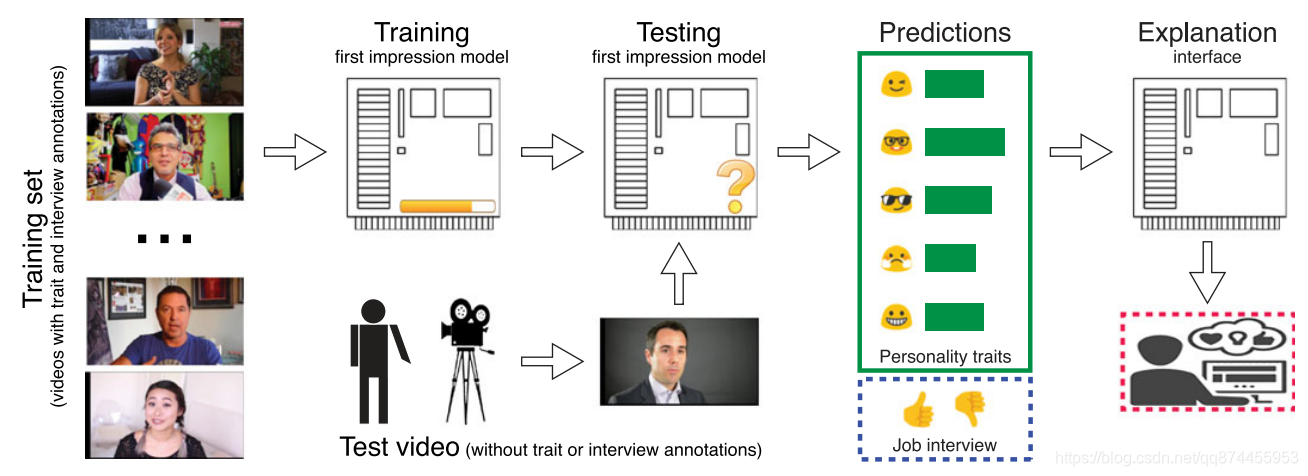
Audiovisual 模型
参考了之前使用的resnet , 但是声音和视觉由于其维度不同,其结构也有一些不同,主要的区别就是,步长, 卷积核的问题
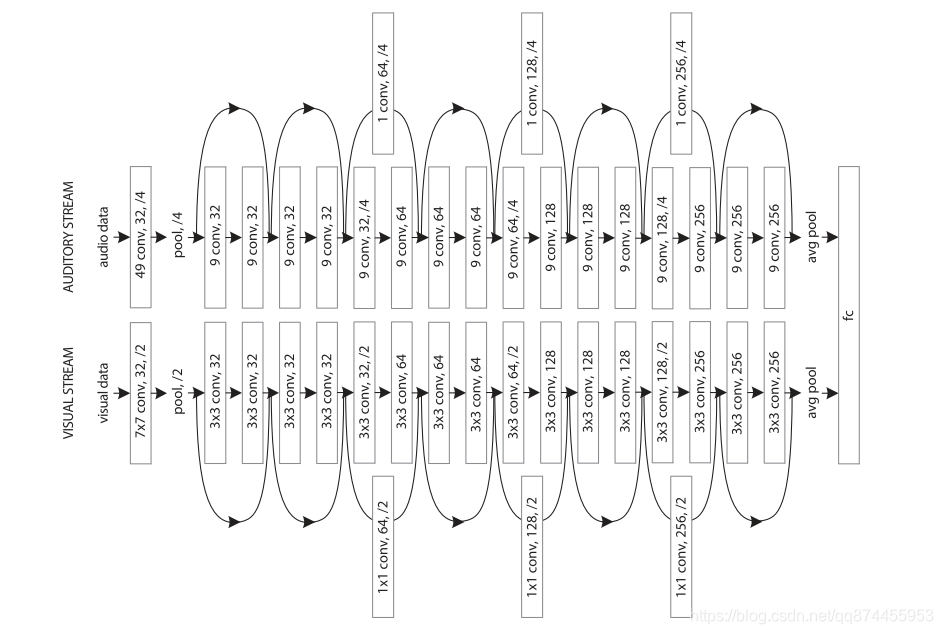
其训练过程如下:
- 从视频中读取声音和视觉数据
- 声音随机采样50176个样本,约为3.316秒, 放到声音提取模型中
- 视觉 随机采样 224*224的图片, 放到视觉提取模型中
- 最后把两个模态得到的特征拼接,进行拼接,最后放入全连接进行预测
验证过程如下:
- 从视频中读取声音和视觉数据
- 声音全部放到声音提取模型中
- 视觉 随机采样一帧
- 最后把两个模态得到的特征拼接,进行拼接,最后放入全连接进行预测
因为两个模态的特征提取模块的 倒数第二层后面都是全局平均池, 所以不用担心输入不同的问题
当然,为了消融实验:
作者还使用了单独的音频模型和单独的视觉模型。 这些模型由视听模型的相应流组成,但是后面是单独的连接层。 他们也分别进行了评估
Language 模型
或者使用两个模型来进行,的预测,一个是词袋模型,另外一个是skip-thought vectors,
每一个句子都被编码成一个固定的特征向量
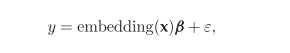
这每一个特征向量都用一个线性回归来进行预测
实验&训练
个性之间的相关性

平均脸
作者这里用了可视化的处理,把5个个性的高人群和低人群的平均脸进行了输出,这里非常有趣
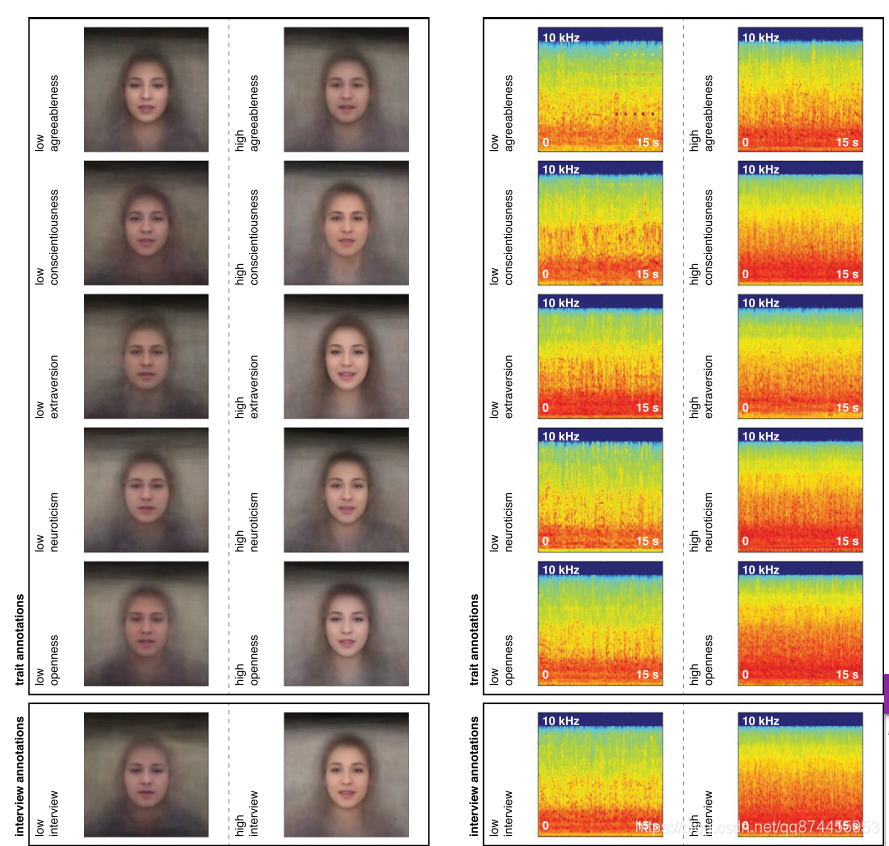
结果
实验结果:

最后文章还给了一一种可解释性的方法来解释为什么不同的个性使得他录取还是不录取,例如由于这个人的开朗性不是很高,所以他将不会被录取,感兴趣的可以自己读一下好,
总结
- 声音的提取模态,有点东西可以看一下
- 准确率还挺高的

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









