






算法除了基础的之外还有搜索,数据结构(之前发过),动态规划,图论等,这篇文章先给大家介绍12种基础算法和一些例题。
1.高精度
当数据的值特别⼤,各种类型都存不下的时候,此时就要⽤⾼精度算法来计算加减乘除:
• 先⽤字符串读⼊这个数,然后⽤数组逆序存储该数的每⼀位;
• 利⽤数组,模拟加减乘除运算的过程。
⾼精度算法本质上还是模拟算法,⽤代码模拟⼩学列竖式计算加减乘除的过程
1.1加法
洛谷⾼精度加法
- ⽤字符串读⼊数据;
- 将字符串的每⼀位拆分,逆序放在数组中;(我们是从最低位开始加)
- 模拟列竖式计算的过程:
a. 对应位累加;
b. 处理进位;
c. 处理余数。 - 处理结果的位数。
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1e6;
int l1, l2, l3 = 0;
int arr1[N], arr2[N], arr3[N];
void add(int arr3[], int arr2[], int arr1[])
{
for (int i = 0; i < l3; i++)
{
arr3[i] += arr2[i] + arr1[i];// 对应位相加,再加上进位
arr3[i + 1] += arr3[i] / 10;// 处理进位
arr3[i] = arr3[i] % 10; // 处理余数
}
if (arr3[l3])l3++;
}
int main()
{
string a; string b;
cin >> a >> b;
l1 = a.size(); l2 = b.size(); l3 = max(l1, l2);
for (int i = 0; i < l1; i++)
{
arr1[l1 - i - 1] = a[i] - '0';
}
for (int j = 0; j < l2; j++)
{
arr2[l2 - j - 1] = b[j] - '0';
}
add(arr3 ,arr1, arr2);
for (int i = l3-1; i >=0; i--)
{
cout << arr3[i];
}
return 0;
}
1.2 减法
洛谷高精度减法
1. ⽤字符串读⼊数据;
2. 判断两个数的⼤⼩,让较⼤的数在前。注意字典序vs数的⼤⼩
a. 位数相等:按字典序⽐较;
b. 位数不等:按照字符串的⻓度⽐较。
3. 将字符串的每⼀位拆分,逆序放在数组中;
4. 模拟列竖式计算的过程:
a. 对应位求差;
b. 处理借位;
5. 处理前导零。
#include<iostream>
using namespace std;
const int N = 1e6;
int a[N], b[N], c[N];
int la, lb, lc;
bool cmp(string& x,string& y)
{
if (x.size() != y.size())return x.size()<y.size();
return x < y;
}
void sub(int a[], int b[], int c[])
{
for(int i = 0; i < lc; i++)
{
c[i] += a[i] - b[i];
if (c[i] < 0)
{
c[i + 1] -= 1;
c[i] += 10;
}
}
while (lc > 1 && c[lc-1] == 0)lc--;
}
int main()
{
string x, y;
cin >> x >> y;
if (cmp(x, y))
{
swap(x, y);
cout << '-';
}
la = x.size(); lb = y.size(); lc = max(la, lb);
for (int i = 0; i < la; i++)
{
a[la - i - 1] = x[i]-'0';
}
for (int j = 0; j < lb; j++)
{
b[lb - j - 1] = y[j]-'0';
}
sub(a, b, c);
for (int i = lc - 1; i >= 0; i--)
{
cout << c[i];
}
return 0;
}
1.3乘法
洛谷高精度乘法
模拟⽆进位相乘再相加的过程:
a. 对应位求乘积;
b. 乘完之后处理进位;
c. 处理余数;
#include<iostream>
using namespace std;
const int N = 1e6;
int a[N], b[N], c[N];
int la, lb, lc;
void mul(int a[], int b[], int c[])
{
for (int i = 0; i < la; i++)
{
for (int j = 0; j < lb; j++)
{
c[i + j] += a[i] * b[j];
}
}
for (int i = 0; i < lc; i++)
{
c[i + 1] += c[i] / 10;
c[i] %= 10;
}
while (lc > 1 && c[lc - 1] == 0)lc--;
}
int main()
{
string x, y;
cin >> x >> y;
la = x.size(); lb = y.size(); lc = la + lb;
for (int i = 0; i < la; i++)
{
a[la - i - 1] = x[i] - '0';
}
for (int j = 0; j < lb; j++)
{
b[lb - j - 1] = y[j] - '0';
}
mul(a, b, c);
for (int i = lc - 1; i >= 0; i--)
{
cout << c[i];
}
return 0;
}
1.4除法
洛谷高精度除法
定义⼀个指针i 从「⾼位」遍历被除数,⼀个变量t 标记当前「被除的数」,记除数是b ;
• 更新⼀个当前被除的数t = t × 10 + a[i] ;
• t/b 表⽰这⼀位的商,t%b 表⽰这⼀位的余数;
• ⽤t 记录这⼀次的余数,遍历到下⼀位的时候重复上⾯的过程
被除数遍历完毕之后,t ⾥⾯存的就是余数,但是商可能存在前导0 ,注意清空。
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
typedef long long LL;
int a[N], b, c[N];
int la, lc;
// ⾼精度除法的模板 - c = a / b (⾼精度 / 低精度)
void sub(int c[], int a[], int b)
{
LL t = 0; // 标记每次除完之后的余数
for(int i = la - 1; i >= 0; i--)
{
// 计算当前的被除数
t = t * 10 + a[i];
c[i] = t / b;
t %= b;
}
// 处理前导 0
while(lc > 1 && c[lc - 1] == 0) lc--;
}
int main()
{
string x; cin >> x >> b;
la = x.size();
for(int i = 0; i < la; i++) a[la - 1 - i] = x[i] - '0';
// 模拟除法的过程
lc = la;
sub(c, a, b); // c = a / b
for(int i = lc - 1; i >= 0; i--) cout << c[i];
return 0;
}
2.枚举
顾名思义,就是把所有情况全都罗列出来,然后找出符合题⽬要求的那⼀个。因此,枚举是⼀种纯暴⼒的算法.使⽤枚举策略时,重点思考枚举的对象(枚举什么),枚举的顺序(正序还是逆序),以及枚举的⽅式(普通枚举?递归枚举?⼆进制枚举)。
⼀般情况下,枚举策略都是会超时的。此时要先根据题⽬的数据范围来判断暴⼒枚举是否可以通过。
如果不⾏的话,就要⽤后⾯要学的各种算法来进⾏优化(⽐如⼆分,双指针,前缀和与差分等),
下面会提到。
这里给大家介绍一下二进制枚举
力扣子集
枚举1~1<<n之间的数,每⼀个数的⼆进制中1的位置可以表⽰数组中对应位置选上该元
素。
class Solution
{
public:
vector<vector<int>> subsets(vector<int>& nums)
{
vector<vector<int>> ret;
int n = nums.size();
// 枚举所有的状态
for(int st = 0; st < (1 << n); st++)
{
// 根据 st 的状态,还原出要选的数
vector<int> tmp; // 从当前选的⼦集
for(int i = 0; i < n; i++)
{
if((st >> i) & 1) tmp.push_back(nums[i]);
}
ret.push_back(tmp);
}
return ret;
}
};
3.前缀和
前缀和与差分的核⼼思想是预处理,可以在暴⼒枚举的过程中,快速给出查询的结果,从⽽优化时间
复杂度。
是经典的⽤空间替换时间的做法。
3.1⼀维前缀和
原数组
arr[N]={1,2,3,4,5}
前缀和
f[N]={1,3,6,10,15}
创建前缀和数组:f[i] = f[i − 1] + a[i]
查询[l, r] 区间和:f[r] − f[l − 1]
3.2⼆维前缀和
- 创建前缀和矩阵:f[x1][y1] = f[x1][y1-1] + f[y1][x1 − 1] − f[x1− 1][y1 − 1] + a[x1][y1]
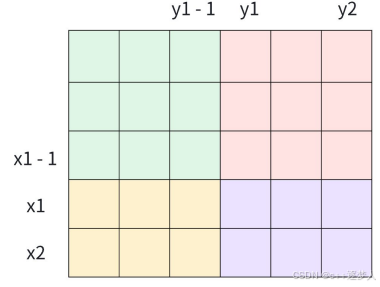
- 查询以(x1 , y1 )为左上⻆(x2 , y2 )为右下⻆的⼦矩阵的和
sum = f[x2][y2]-f[x2][y1-1]-f[x1-1][y2]+f[x1-1][y1-1]
#include<iostream>
using namespace std;
const int N = 5e3 + 10;
int arr[N][N];
int f[N][N];
int main()
{
int n, r;
cin >> n >> r;
while (n--)
{
int x, y,v = 0;
cin >> x >> y >> v;
x++; y++;
arr[x][y] += v;
}
n = 5001;
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= n; j++)
{
f[i][j] = f[i - 1][j] + f[i][j-1] - f[i - 1][j - 1] + arr[i][j];
}
}
int ret = 0;
int x1, x2, y1, y2;
r = min(r, n);
for (int x2 = r; x2 <= n; x2++)
{
for (int y2 = r; y2 <= n; y2++)
{
x1 = x2 - r + 1; y1 = y2 - r + 1;
ret = max(ret, f[x2][y2] - f[x2][y1 - 1] - f[x1 - 1][y2] + f[x1 - 1][y1 - 1]);
}
}
cout << ret;
return 0;
}
4.差分
前缀和与差分的核⼼思想是预处理,可以在暴⼒枚举的过程中,快速给出查询的结果,从⽽优化时间复杂度。
4.1⼀维差分
原数组
arr[N]={1,2,3,4,5}
差分
f[N]={1,1,1,1,1}
1.创建差分数组,根据定义:f[i] = a[i] − a[i − 1]
2.若原数组前4个数+1
arr[N]={2,3,4,5,5}
差分
f[N]={2,1,1,1,0}
根据差分数组的性质处理区间修改:f[L] + = c, f[R + 1] − = c
3.还原经过q 次询问之后的a 数组:对差分数组做⼀次「前缀和」,就可以还原出原数组
f[1]=a[1]______a[1]=f[1]
f[2]=a[2]-a[1] ______a[2]=f[2]+a[1]=f[2]+[1]
f[i]=a[i]-a[i-1] ______a[i]=f[i]+f[i-1]+…f[1]
海底高铁洛谷
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
int n, m;
LL f[N]; // 差分数组
int main()
{
cin >> n >> m;
// x->y
int x; cin >> x;
for(int i = 2; i <= m; i++)
{
int y; cin >> y;
// x -> y
if(x > y)
{
f[y]++;
f[x]--;
}
else
{
f[x]++;
f[y]--;
}
x = y;
}
// 利⽤差分数组,还原出原数组
for(int i = 1; i <= n; i++) f[i] += f[i - 1];
// 直接求结果
LL ret = 0;
for(int i = 1; i < n; i++)
{
LL a, b, c; cin >> a >> b >> c;
ret += min(a * f[i], c + b * f[i]);
}
cout << ret << endl;
return 0;
}
⼆维差分

f[y1][x1]+=k
但求前缀和之后会把其余地方也加上看,因此需要进行处理
f[y2+1][x1]-=k
f[y1][x2+1]-=k
f[y2+1][x2+1]+=k
利⽤前缀和还原出修改之后的数组
f[i][j] = f[i - 1][j] + f[i][j - 1] - f[i - 1][j - 1] + f[i][j];
5.双指针
双指针算法有时候也叫尺取法或者滑动窗⼝,是⼀种优化暴⼒枚举策略的⼿段:
• 当我们发现在两层for循环的暴⼒枚举过程中,两个指针是可以不回退的,此时我们就可以利⽤
两个指针不回退的性质来优化时间复杂度。• 因为双指针算法中,两个指针是朝着同⼀个⽅向移动的,因此也叫做同向双指针。
唯一的雪花洛谷
#include <iostream>
#include <unordered_map>
using namespace std;
const int N = 1e6 + 10;
int n;
int a[N];
int main()
{
int T; cin >> T;
while(T--)
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
// 初始化
int left = 1, right = 1, ret = 0;
unordered_map<int, int> mp; // 维护窗⼝内所有元素出现的次数
while(right <= n)
{
// 进窗⼝
mp[a[right]]++;
// 判断
while(mp[a[right]] > 1)
{
// 出窗⼝
mp[a[left]]--;
left++;
}
// 窗⼝合法,更新结果
ret = max(ret, right - left + 1);
right++;
}
cout << ret << endl;
}
return 0;
}
6.⼆分算法
当我们的解具有⼆段性时,就可以使⽤⼆分算法找出答案:
• 根据待查找区间的中点位置,分析答案会出现在哪⼀侧;
• 接下来舍弃⼀半的待查找区间,转⽽在有答案的区间内继续使⽤⼆分算法查找结果。
// ⼆分查找区间左端点
int l = 1, r = n;
while(l < r)
{
int mid = (l + r) / 2;
if(check(mid)) r = mid;
else l = mid + 1;
}
// ⼆分结束之后可能需要判断是否存在结
果
// ⼆分查找区间右端点
int l = 1, r = n;
while(l < r)
{
int mid = (l + r + 1) / 2;
if(check(mid)) l = mid;
else r = mid - 1;
}
// ⼆分结束之后可能需要判断是否存在结
果
7.贪心
贪⼼算法,或者说是贪⼼策略:企图⽤局部最优找出全局最优。
- 把解决问题的过程分成若⼲步;
- 解决每⼀步时,都选择"当前看起来最优的"解法;
- "希望"得到全局的最优解。
因为贪心算法简单的很简单难的很困难,之后另开一篇详说
8.倍增思想
倍增,顾名思义就是翻倍。它能够使线性的处理转化为对数级的处理,极⼤地优化时间复杂度
#include <iostream>
using namespace std;
typedef long long LL;
LL a, b, p;
// 快速幂的模板
LL qpow(LL a, LL b, LL p)
{
LL ret = 1;
while(b)
{
if(b & 1) ret = ret * a % p;
a = a * a % p;
b >>= 1;
}
return ret;
}
int main()
{
cin >> a >> b >> p;
printf("%lld^%lld mod %lld=%lld",a, b, p, qpow(a, b, p));
return 0;
}
9.离散化
当题⽬中数据的范围很⼤,但是数据的总量不是很⼤。此时如果需要⽤数据的值来映射数组的下标时,就可以⽤离散化的思想先预处理⼀下所有的数据,使得每⼀个数据都映射成⼀个较⼩的值。之后再⽤离散化之后的数去处理问题。
⽐如:[99, 9, 9999, 999999] 离散之后就变成[2, 1, 3, 4]
// 离散化模板:排序 + 去重 + ⼆分查找离散之后的结果
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1e5 + 10;
int n;
int a[N];
int pos; // 标记去重之后的元素个数
int disc[N]; // 帮助离散化
// ⼆分 x 的位置
int find(int x)
{
int l = 1, r = pos;
while(l < r)
{
int mid = (l + r) / 2;
if(disc[mid] >= x) r = mid;
else l = mid + 1;
}
return l;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i];
disc[++pos] = a[i];
}
// 离散化
sort(disc + 1, disc + 1 + pos); // 排序
pos = unique(disc + 1, disc + 1 + pos) - (disc + 1); // 去重
for(int i = 1; i <= n; i++)
{
cout << a[i] << "离散化之后:" << find(a[i]) << endl;
}
return 0;
}
10.递归
- 先找到相同的⼦问题->确定函数的功能以及函数头的设计;
- 只关⼼某⼀个⼦问题是如何解决的->函数体
- 不能继续拆分的⼦问题->递归出口
11.分治
分治,字⾯上的解释是「分⽽治之」,就是把⼀个复杂的问题分成两个或更多的相同的⼦问题,直到
最后⼦问题可以简单的直接求解,原问题的解即⼦问题的解的合并。
一般分为左中右
12.模拟
模拟,顾名思义,就是题⽬让你做什么你就做什么,考察的是将思路转化成代码的代码能⼒。
一般都是简单题,但也有例外。
这里就给大家介绍一道比较经典的例题。
洛谷蛇形方阵
可以定义两个方向数组。
#include<iostream>
using namespace std;
const int N = 15;
int tmp[N][N];
int main()
{
int x = 1;
int y = 1;
int pos = 0;
int a = 0; int b = 0;
int dx[] = { 0,1,0,-1 };
int dy[] = { 1,0,-1,0 };
int n;
cin >> n;
for(int i=1;i<=n*n;i++)
{
tmp[x][y] = i;
a = x + dx[pos]; b = y + dy[pos];
if (a > n || a<1 || b>n || b < 1||tmp[a][b])
{
pos = (pos + 1) % 4;
a = x + dx[pos]; b = y + dy[pos];
}
x = a; y = b;
}
for(int i=1;i<=n;i++)
{
for (int j = 1; j <=n; j++)
{
printf("%3d", tmp[i][j]);
}
printf("\n");
}
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









